 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle Composition within Distinct LoRA modules for Traditional Art
Jul 16, 2025Diffusion-based text-to-image models have achieved remarkable results in synthesizing diverse images from text prompts and can capture specific artistic styles via style personalization. However, their entangled latent space and lack of smooth interpolation make it difficult to apply distinct painting techniques in a controlled, regional manner, often causing one style to dominate. To overcome this, we propose a zero-shot diffusion pipeline that naturally blends multiple styles by performing style composition on the denoised latents predicted during the flow-matching denoising process of separately trained, style-specialized models. We leverage the fact that lower-noise latents carry stronger stylistic information and fuse them across heterogeneous diffusion pipelines using spatial masks, enabling precise, region-specific style control. This mechanism preserves the fidelity of each individual style while allowing user-guided mixing. Furthermore, to ensure structural coherence across different models, we incorporate depth-map conditioning via ControlNet into the diffusion framework. Qualitative and quantitative experiments demonstrate that our method successfully achieves region-specific style mixing according to the given masks.
Harmonizing Visual and Textual Embeddings for Zero-Shot Text-to-Image Customization
Mar 21, 2024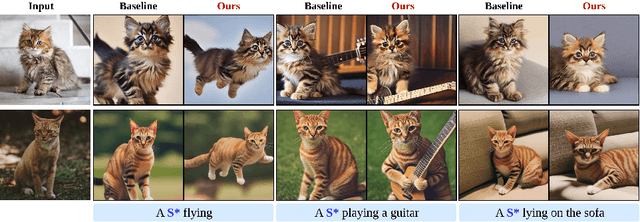
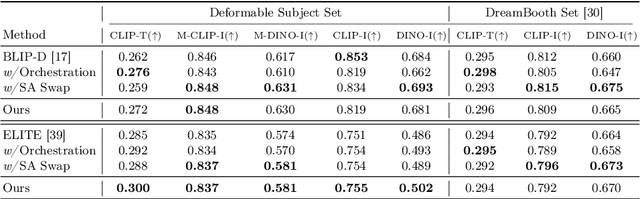
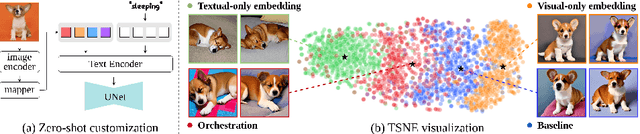
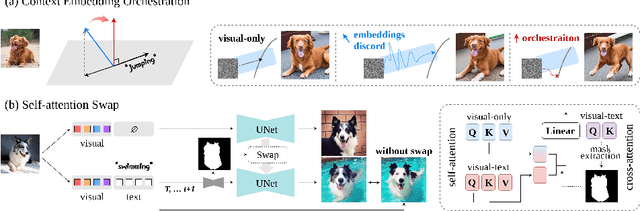
In a surge of text-to-image (T2I) models and their customization methods that generate new images of a user-provided subject, current works focus on alleviating the costs incurred by a lengthy per-subject optimization. These zero-shot customization methods encode the image of a specified subject into a visual embedding which is then utilized alongside the textual embedding for diffusion guidance. The visual embedding incorporates intrinsic information about the subject, while the textual embedding provides a new, transient context. However, the existing methods often 1) are significantly affected by the input images, eg., generating images with the same pose, and 2) exhibit deterioration in the subject's identity. We first pin down the problem and show that redundant pose information in the visual embedding interferes with the textual embedding containing the desired pose information. To address this issue, we propose orthogonal visual embedding which effectively harmonizes with the given textual embedding. We also adopt the visual-only embedding and inject the subject's clear features utilizing a self-attention swap. Our results demonstrate the effectiveness and robustness of our method, which offers highly flexible zero-shot generation while effectively maintaining the subject's identity.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.