 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoGoColor: Local-Global 3D Colorization for 360° Scenes
Dec 10, 2025



Single-channel 3D reconstruction is widely used in fields such as robotics and medical imaging. While this line of work excels at reconstructing 3D geometry, the outputs are not colored 3D models, thus 3D colorization is required for visualization. Recent 3D colorization studies address this problem by distilling 2D image colorization models. However, these approaches suffer from an inherent inconsistency of 2D image models. This results in colors being averaged during training, leading to monotonous and oversimplified results, particularly in complex 360° scenes. In contrast, we aim to preserve color diversity by generating a new set of consistently colorized training views, thereby bypassing the averaging process. Nevertheless, eliminating the averaging process introduces a new challenge: ensuring strict multi-view consistency across these colorized views. To achieve this, we propose LoGoColor, a pipeline designed to preserve color diversity by eliminating this guidance-averaging process with a `Local-Global' approach: we partition the scene into subscenes and explicitly tackle both inter-subscene and intra-subscene consistency using a fine-tuned multi-view diffusion model. We demonstrate that our method achieves quantitatively and qualitatively more consistent and plausible 3D colorization on complex 360° scenes than existing methods, and validate its superior color diversity using a novel Color Diversity Index.
Style Composition within Distinct LoRA modules for Traditional Art
Jul 16, 2025Diffusion-based text-to-image models have achieved remarkable results in synthesizing diverse images from text prompts and can capture specific artistic styles via style personalization. However, their entangled latent space and lack of smooth interpolation make it difficult to apply distinct painting techniques in a controlled, regional manner, often causing one style to dominate. To overcome this, we propose a zero-shot diffusion pipeline that naturally blends multiple styles by performing style composition on the denoised latents predicted during the flow-matching denoising process of separately trained, style-specialized models. We leverage the fact that lower-noise latents carry stronger stylistic information and fuse them across heterogeneous diffusion pipelines using spatial masks, enabling precise, region-specific style control. This mechanism preserves the fidelity of each individual style while allowing user-guided mixing. Furthermore, to ensure structural coherence across different models, we incorporate depth-map conditioning via ControlNet into the diffusion framework. Qualitative and quantitative experiments demonstrate that our method successfully achieves region-specific style mixing according to the given masks.
S3D: Sketch-Driven 3D Model Generation
May 07, 2025Generating high-quality 3D models from 2D sketches is a challenging task due to the inherent ambiguity and sparsity of sketch data. In this paper, we present S3D, a novel framework that converts simple hand-drawn sketches into detailed 3D models. Our method utilizes a U-Net-based encoder-decoder architecture to convert sketches into face segmentation masks, which are then used to generate a 3D representation that can be rendered from novel views. To ensure robust consistency between the sketch domain and the 3D output, we introduce a novel style-alignment loss that aligns the U-Net bottleneck features with the initial encoder outputs of the 3D generation module, significantly enhancing reconstruction fidelity. To further enhance the network's robustness, we apply augmentation techniques to the sketch dataset. This streamlined framework demonstrates the effectiveness of S3D in generating high-quality 3D models from sketch inputs. The source code for this project is publicly available at https://github.com/hailsong/S3D.
MSG score: A Comprehensive Evaluation for Multi-Scene Video Generation
Nov 28, 2024This paper addresses the metrics required for generating multi-scene videos based on a continuous scenario, as opposed to traditional short video generation. Scenario-based videos require a comprehensive evaluation that considers multiple factors such as character consistency, artistic coherence, aesthetic quality, and the alignment of the generated content with the intended prompt. Additionally, in video generation, unlike single images, the movement of characters across frames introduces potential issues like distortion or unintended changes, which must be effectively evaluated and corrected. In the context of probabilistic models like diffusion, generating the desired scene requires repeated sampling and manual selection, akin to how a film director chooses the best shots from numerous takes. We propose a score-based evaluation benchmark that automates this process, enabling a more objective and efficient assessment of these complexities. This approach allows for the generation of high-quality multi-scene videos by selecting the best outcomes based on automated scoring rather than manual inspection.
Harmonizing Visual and Textual Embeddings for Zero-Shot Text-to-Image Customization
Mar 21, 2024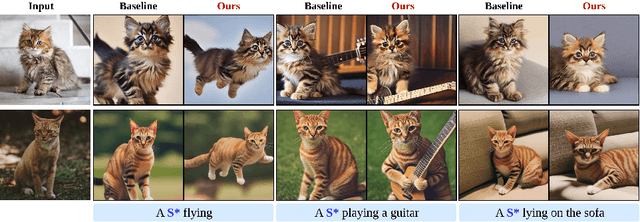
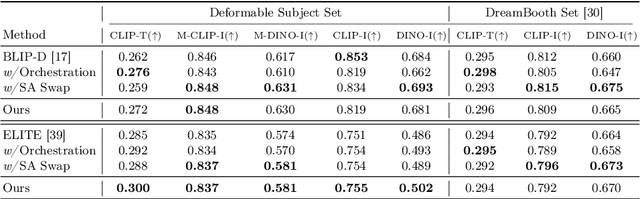
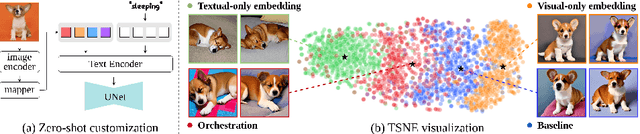
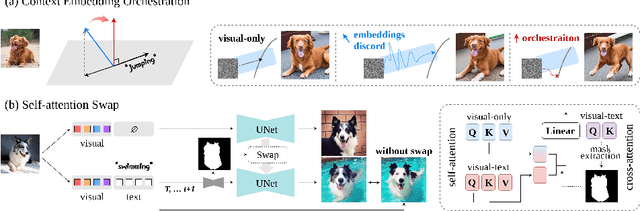
In a surge of text-to-image (T2I) models and their customization methods that generate new images of a user-provided subject, current works focus on alleviating the costs incurred by a lengthy per-subject optimization. These zero-shot customization methods encode the image of a specified subject into a visual embedding which is then utilized alongside the textual embedding for diffusion guidance. The visual embedding incorporates intrinsic information about the subject, while the textual embedding provides a new, transient context. However, the existing methods often 1) are significantly affected by the input images, eg., generating images with the same pose, and 2) exhibit deterioration in the subject's identity. We first pin down the problem and show that redundant pose information in the visual embedding interferes with the textual embedding containing the desired pose information. To address this issue, we propose orthogonal visual embedding which effectively harmonizes with the given textual embedding. We also adopt the visual-only embedding and inject the subject's clear features utilizing a self-attention swap. Our results demonstrate the effectiveness and robustness of our method, which offers highly flexible zero-shot generation while effectively maintaining the subject's identity.
SAVE: Protagonist Diversification with Structure Agnostic Video Editing
Dec 05, 2023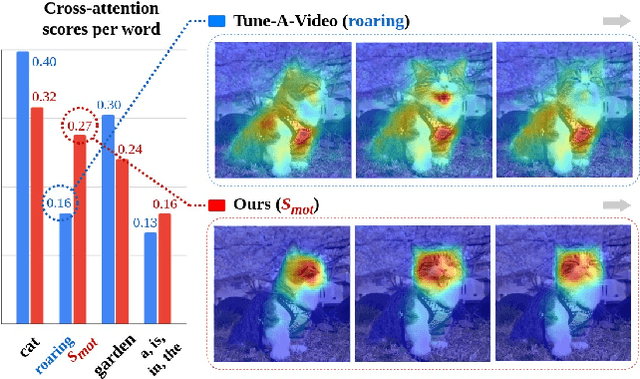
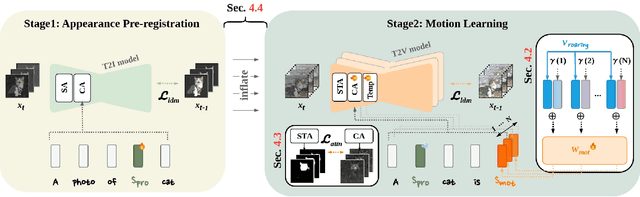
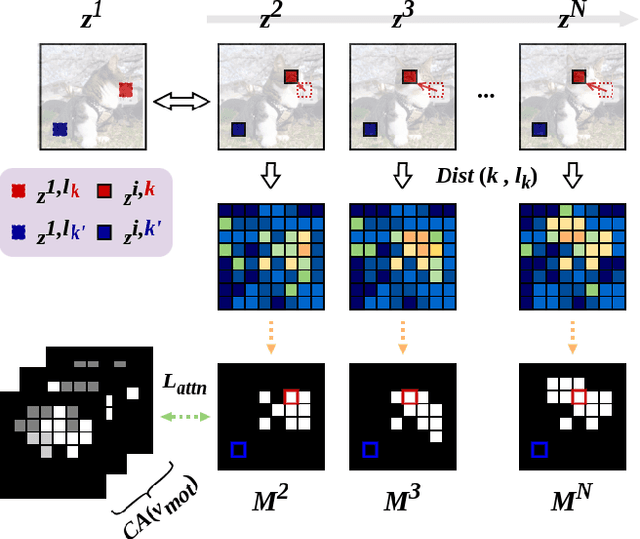

Driven by the upsurge progress in text-to-image (T2I) generation models, text-to-video (T2V) generation has experienced a significant advance as well. Accordingly, tasks such as modifying the object or changing the style in a video have been possible. However, previous works usually work well on trivial and consistent shapes, and easily collapse on a difficult target that has a largely different body shape from the original one. In this paper, we spot the bias problem in the existing video editing method that restricts the range of choices for the new protagonist and attempt to address this issue using the conventional image-level personalization method. We adopt motion personalization that isolates the motion from a single source video and then modifies the protagonist accordingly. To deal with the natural discrepancy between image and video, we propose a motion word with an inflated textual embedding to properly represent the motion in a source video. We also regulate the motion word to attend to proper motion-related areas by introducing a novel pseudo optical flow, efficiently computed from the pre-calculated attention maps. Finally, we decouple the motion from the appearance of the source video with an additional pseudo word. Extensive experiments demonstrate the editing capability of our method, taking a step toward more diverse and extensive video editing.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
Reinforcement Learning for Vision-based Object Manipulation with Non-parametric Policy and Action Primitives
Jun 12, 2022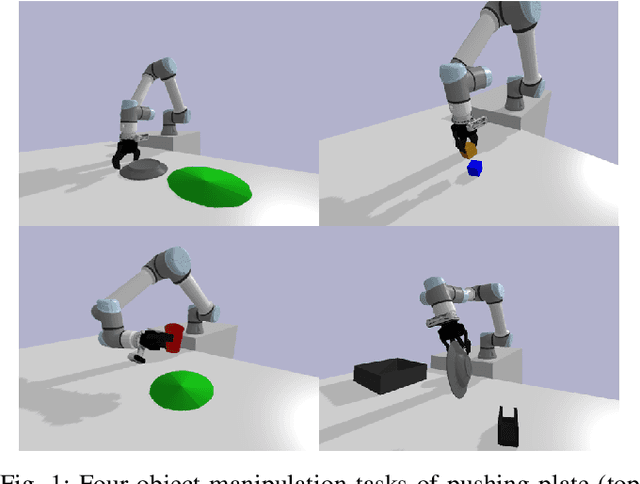
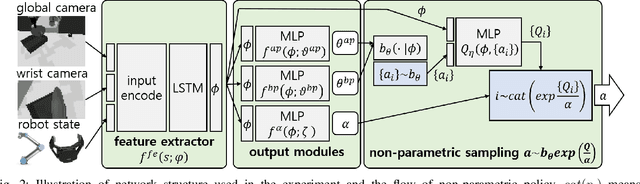
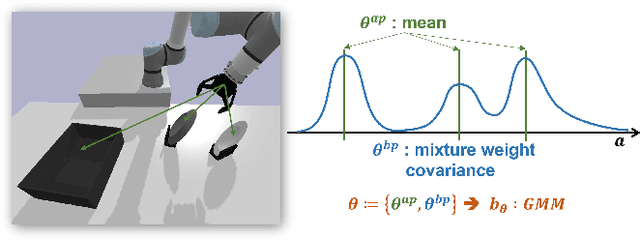
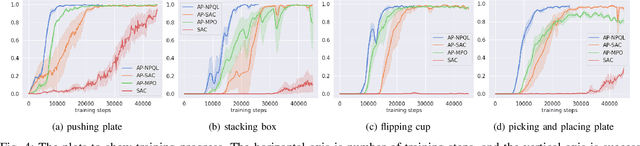
The object manipulation is a crucial ability for a service robot, but it is hard to solve with reinforcement learning due to some reasons such as sample efficiency. In this paper, to tackle this object manipulation, we propose a novel framework, AP-NPQL (Non-Parametric Q Learning with Action Primitives), that can efficiently solve the object manipulation with visual input and sparse reward, by utilizing a non-parametric policy for reinforcement learning and appropriate behavior prior for the object manipulation. We evaluate the efficiency and the performance of the proposed AP-NPQL for four object manipulation tasks on simulation (pushing plate, stacking box, flipping cup, and picking and placing plate), and it turns out that our AP-NPQL outperforms the state-of-the-art algorithms based on parametric policy and behavior prior in terms of learning time and task success rate. We also successfully transfer and validate the learned policy of the plate pick-and-place task to the real robot in a sim-to-real manner.