 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Static Benchmarks to Dynamic Protocol: Agent-Centric Text Anomaly Detection for Evaluating LLM Reasoning
Feb 27, 2026The evaluation of large language models (LLMs) has predominantly relied on static datasets, which offer limited scalability and fail to capture the evolving reasoning capabilities of recent models. To overcome these limitations, we propose an agent-centric benchmarking paradigm that moves beyond static datasets by introducing a dynamic protocol in which autonomous agents iteratively generate, validate, and solve problems. Within this protocol, a teacher agent generates candidate problems, an orchestrator agent rigorously verifies their validity and guards against adversarial attacks, and a student agent attempts to solve the validated problems. An invalid problem is revised by the teacher agent until it passes validation. If the student correctly solves the problem, the orchestrator prompts the teacher to generate more challenging variants. Consequently, the benchmark scales in difficulty automatically as more capable agents are substituted into any role, enabling progressive evaluation of large language models without manually curated datasets. Adopting text anomaly detection as our primary evaluation format, which demands cross-sentence logical inference and resists pattern-matching shortcuts, we demonstrate that this protocol systematically exposes corner-case reasoning errors that conventional benchmarks fail to reveal. We further advocate evaluating systems along several complementary axes including cross-model pairwise performance and progress between the initial and orchestrator-finalized problems. By shifting the focus from fixed datasets to dynamic protocols, our approach offers a sustainable direction for evaluating ever-evolving language models and introduces a research agenda centered on the co-evolution of agent-centric benchmarks.
ReTabAD: A Benchmark for Restoring Semantic Context in Tabular Anomaly Detection
Oct 02, 2025In tabular anomaly detection (AD), textual semantics often carry critical signals, as the definition of an anomaly is closely tied to domain-specific context. However, existing benchmarks provide only raw data points without semantic context, overlooking rich textual metadata such as feature descriptions and domain knowledge that experts rely on in practice. This limitation restricts research flexibility and prevents models from fully leveraging domain knowledge for detection. ReTabAD addresses this gap by restoring textual semantics to enable context-aware tabular AD research. We provide (1) 20 carefully curated tabular datasets enriched with structured textual metadata, together with implementations of state-of-the-art AD algorithms including classical, deep learning, and LLM-based approaches, and (2) a zero-shot LLM framework that leverages semantic context without task-specific training, establishing a strong baseline for future research. Furthermore, this work provides insights into the role and utility of textual metadata in AD through experiments and analysis. Results show that semantic context improves detection performance and enhances interpretability by supporting domain-aware reasoning. These findings establish ReTabAD as a benchmark for systematic exploration of context-aware AD.
Safety-Aware Robust Model Predictive Control for Robotic Arms in Dynamic Environments
May 30, 2025Robotic manipulators are essential for precise industrial pick-and-place operations, yet planning collision-free trajectories in dynamic environments remains challenging due to uncertainties such as sensor noise and time-varying delays. Conventional control methods often fail under these conditions, motivating the development of Robust MPC (RMPC) strategies with constraint tightening. In this paper, we propose a novel RMPC framework that integrates phase-based nominal control with a robust safety mode, allowing smooth transitions between safe and nominal operations. Our approach dynamically adjusts constraints based on real-time predictions of moving obstacles\textemdash whether human, robot, or other dynamic objects\textemdash thus ensuring continuous, collision-free operation. Simulation studies demonstrate that our controller improves both motion naturalness and safety, achieving faster task completion than conventional methods.
MultiTab: A Comprehensive Benchmark Suite for Multi-Dimensional Evaluation in Tabular Domains
May 20, 2025Despite the widespread use of tabular data in real-world applications, most benchmarks rely on average-case metrics, which fail to reveal how model behavior varies across diverse data regimes. To address this, we propose MultiTab, a benchmark suite and evaluation framework for multi-dimensional, data-aware analysis of tabular learning algorithms. Rather than comparing models only in aggregate, MultiTab categorizes 196 publicly available datasets along key data characteristics, including sample size, label imbalance, and feature interaction, and evaluates 13 representative models spanning a range of inductive biases. Our analysis shows that model performance is highly sensitive to such regimes: for example, models using sample-level similarity excel on datasets with large sample sizes or high inter-feature correlation, while models encoding inter-feature dependencies perform best with weakly correlated features. These findings reveal that inductive biases do not always behave as intended, and that regime-aware evaluation is essential for understanding and improving model behavior. MultiTab enables more principled model design and offers practical guidance for selecting models tailored to specific data characteristics. All datasets, code, and optimization logs are publicly available at https://huggingface.co/datasets/LGAI-DILab/Multitab.
Unified Cross-modal Translation of Score Images, Symbolic Music, and Performance Audio
May 19, 2025Music exists in various modalities, such as score images, symbolic scores, MIDI, and audio. Translations between each modality are established as core tasks of music information retrieval, such as automatic music transcription (audio-to-MIDI) and optical music recognition (score image to symbolic score). However, most past work on multimodal translation trains specialized models on individual translation tasks. In this paper, we propose a unified approach, where we train a general-purpose model on many translation tasks simultaneously. Two key factors make this unified approach viable: a new large-scale dataset and the tokenization of each modality. Firstly, we propose a new dataset that consists of more than 1,300 hours of paired audio-score image data collected from YouTube videos, which is an order of magnitude larger than any existing music modal translation datasets. Secondly, our unified tokenization framework discretizes score images, audio, MIDI, and MusicXML into a sequence of tokens, enabling a single encoder-decoder Transformer to tackle multiple cross-modal translation as one coherent sequence-to-sequence task. Experimental results confirm that our unified multitask model improves upon single-task baselines in several key areas, notably reducing the symbol error rate for optical music recognition from 24.58% to a state-of-the-art 13.67%, while similarly substantial improvements are observed across the other translation tasks. Notably, our approach achieves the first successful score-image-conditioned audio generation, marking a significant breakthrough in cross-modal music generation.
Emergence of Goal-Directed Behaviors via Active Inference with Self-Prior
Apr 15, 2025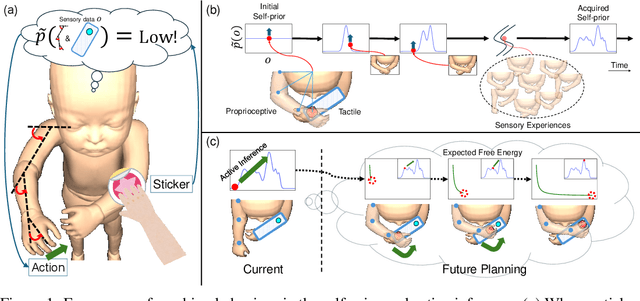



Infants often exhibit goal-directed behaviors, such as reaching for a sensory stimulus, even when no external reward criterion is provided. These intrinsically motivated behaviors facilitate spontaneous exploration and learning of the body and environment during early developmental stages. Although computational modeling can offer insight into the mechanisms underlying such behaviors, many existing studies on intrinsic motivation focus primarily on how exploration contributes to acquiring external rewards. In this paper, we propose a novel density model for an agent's own multimodal sensory experiences, called the "self-prior," and investigate whether it can autonomously induce goal-directed behavior. Integrated within an active inference framework based on the free energy principle, the self-prior generates behavioral references purely from an intrinsic process that minimizes mismatches between average past sensory experiences and current observations. This mechanism is also analogous to the acquisition and utilization of a body schema through continuous interaction with the environment. We examine this approach in a simulated environment and confirm that the agent spontaneously reaches toward a tactile stimulus. Our study implements intrinsically motivated behavior shaped by the agent's own sensory experiences, demonstrating the spontaneous emergence of intentional behavior during early development.
Six Dragons Fly Again: Reviving 15th-Century Korean Court Music with Transformers and Novel Encoding
Aug 02, 2024



We introduce a project that revives a piece of 15th-century Korean court music, Chihwapyeong and Chwipunghyeong, composed upon the poem Songs of the Dragon Flying to Heaven. One of the earliest examples of Jeongganbo, a Korean musical notation system, the remaining version only consists of a rudimentary melody. Our research team, commissioned by the National Gugak (Korean Traditional Music) Center, aimed to transform this old melody into a performable arrangement for a six-part ensemble. Using Jeongganbo data acquired through bespoke optical music recognition, we trained a BERT-like masked language model and an encoder-decoder transformer model. We also propose an encoding scheme that strictly follows the structure of Jeongganbo and denotes note durations as positions. The resulting machine-transformed version of Chihwapyeong and Chwipunghyeong were evaluated by experts and performed by the Court Music Orchestra of National Gugak Center. Our work demonstrates that generative models can successfully be applied to traditional music with limited training data if combined with careful design.
When Model Meets New Normals: Test-time Adaptation for Unsupervised Time-series Anomaly Detection
Dec 19, 2023Time-series anomaly detection deals with the problem of detecting anomalous timesteps by learning normality from the sequence of observations. However, the concept of normality evolves over time, leading to a "new normal problem", where the distribution of normality can be changed due to the distribution shifts between training and test data. This paper highlights the prevalence of the new normal problem in unsupervised time-series anomaly detection studies. To tackle this issue, we propose a simple yet effective test-time adaptation strategy based on trend estimation and a self-supervised approach to learning new normalities during inference. Extensive experiments on real-world benchmarks demonstrate that incorporating the proposed strategy into the anomaly detector consistently improves the model's performance compared to the baselines, leading to robustness to the distribution shifts.
Deep Imbalanced Time-series Forecasting via Local Discrepancy Density
Feb 27, 2023



Time-series forecasting models often encounter abrupt changes in a given period of time which generally occur due to unexpected or unknown events. Despite their scarce occurrences in the training set, abrupt changes incur loss that significantly contributes to the total loss. Therefore, they act as noisy training samples and prevent the model from learning generalizable patterns, namely the normal states. Based on our findings, we propose a reweighting framework that down-weights the losses incurred by abrupt changes and up-weights those by normal states. For the reweighting framework, we first define a measurement termed Local Discrepancy (LD) which measures the degree of abruptness of a change in a given period of time. Since a training set is mostly composed of normal states, we then consider how frequently the temporal changes appear in the training set based on LD. Our reweighting framework is applicable to existing time-series forecasting models regardless of the architectures. Through extensive experiments on 12 time-series forecasting models over eight datasets with various in-output sequence lengths, we demonstrate that applying our reweighting framework reduces MSE by 10.1% on average and by up to 18.6% in the state-of-the-art model.
WaveBound: Dynamic Error Bounds for Stable Time Series Forecasting
Oct 25, 2022



Time series forecasting has become a critical task due to its high practicality in real-world applications such as traffic, energy consumption, economics and finance, and disease analysis. Recent deep-learning-based approaches have shown remarkable success in time series forecasting. Nonetheless, due to the dynamics of time series data, deep networks still suffer from unstable training and overfitting. Inconsistent patterns appearing in real-world data lead the model to be biased to a particular pattern, thus limiting the generalization. In this work, we introduce the dynamic error bounds on training loss to address the overfitting issue in time series forecasting. Consequently, we propose a regularization method called WaveBound which estimates the adequate error bounds of training loss for each time step and feature at each iteration. By allowing the model to focus less on unpredictable data, WaveBound stabilizes the training process, thus significantly improving generalization. With the extensive experiments, we show that WaveBound consistently improves upon the existing models in large margins, including the state-of-the-art model.