 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Clock Attention for Aligning Continuous and Ordered Sequences
Sep 18, 2025We formulate an attention mechanism for continuous and ordered sequences that explicitly functions as an alignment model, which serves as the core of many sequence-to-sequence tasks. Standard scaled dot-product attention relies on positional encodings and masks but does not enforce continuity or monotonicity, which are crucial for frame-synchronous targets. We propose learned nonnegative \emph{clocks} to source and target and model attention as the meeting probability of these clocks; a path-integral derivation yields a closed-form, Gaussian-like scoring rule with an intrinsic bias toward causal, smooth, near-diagonal alignments, without external positional regularizers. The framework supports two complementary regimes: normalized clocks for parallel decoding when a global length is available, and unnormalized clocks for autoregressive decoding -- both nearly-parameter-free, drop-in replacements. In a Transformer text-to-speech testbed, this construction produces more stable alignments and improved robustness to global time-scaling while matching or improving accuracy over scaled dot-product baselines. We hypothesize applicability to other continuous targets, including video and temporal signal modeling.
Unified Cross-modal Translation of Score Images, Symbolic Music, and Performance Audio
May 19, 2025Music exists in various modalities, such as score images, symbolic scores, MIDI, and audio. Translations between each modality are established as core tasks of music information retrieval, such as automatic music transcription (audio-to-MIDI) and optical music recognition (score image to symbolic score). However, most past work on multimodal translation trains specialized models on individual translation tasks. In this paper, we propose a unified approach, where we train a general-purpose model on many translation tasks simultaneously. Two key factors make this unified approach viable: a new large-scale dataset and the tokenization of each modality. Firstly, we propose a new dataset that consists of more than 1,300 hours of paired audio-score image data collected from YouTube videos, which is an order of magnitude larger than any existing music modal translation datasets. Secondly, our unified tokenization framework discretizes score images, audio, MIDI, and MusicXML into a sequence of tokens, enabling a single encoder-decoder Transformer to tackle multiple cross-modal translation as one coherent sequence-to-sequence task. Experimental results confirm that our unified multitask model improves upon single-task baselines in several key areas, notably reducing the symbol error rate for optical music recognition from 24.58% to a state-of-the-art 13.67%, while similarly substantial improvements are observed across the other translation tasks. Notably, our approach achieves the first successful score-image-conditioned audio generation, marking a significant breakthrough in cross-modal music generation.
Multiplicative Learning
Mar 13, 2025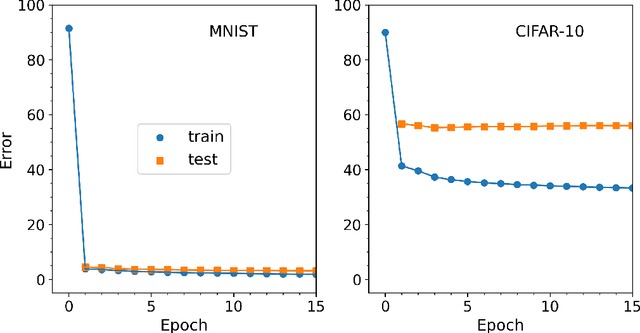
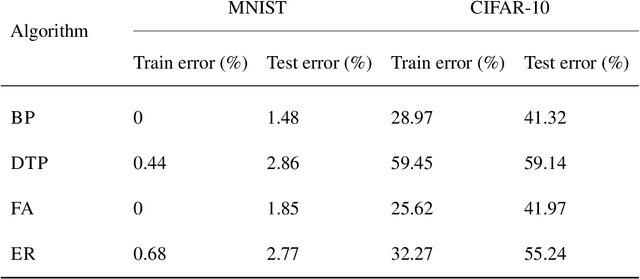
Efficient training of artificial neural networks remains a key challenge in deep learning. Backpropagation (BP), the standard learning algorithm, relies on gradient descent and typically requires numerous iterations for convergence. In this study, we introduce Expectation Reflection (ER), a novel learning approach that updates weights multiplicatively based on the ratio of observed to predicted outputs. Unlike traditional methods, ER maintains consistency without requiring ad hoc loss functions or learning rate hyperparameters. We extend ER to multilayer networks and demonstrate its effectiveness in performing image classification tasks. Notably, ER achieves optimal weight updates in a single iteration. Additionally, we reinterpret ER as a modified form of gradient descent incorporating the inverse mapping of target propagation. These findings suggest that ER provides an efficient and scalable alternative for training neural networks.
Enhancing Demand Prediction in Open Systems by Cartogram-aided Deep Learning
Mar 24, 2024Predicting temporal patterns across various domains poses significant challenges due to their nuanced and often nonlinear trajectories. To address this challenge, prediction frameworks have been continuously refined, employing data-driven statistical methods, mathematical models, and machine learning. Recently, as one of the challenging systems, shared transport systems such as public bicycles have gained prominence due to urban constraints and environmental concerns. Predicting rental and return patterns at bicycle stations remains a formidable task due to the system's openness and imbalanced usage patterns across stations. In this study, we propose a deep learning framework to predict rental and return patterns by leveraging cartogram approaches. The cartogram approach facilitates the prediction of demand for newly installed stations with no training data as well as long-period prediction, which has not been achieved before. We apply this method to public bicycle rental-and-return data in Seoul, South Korea, employing a spatial-temporal convolutional graph attention network. Our improved architecture incorporates batch attention and modified node feature updates for better prediction accuracy across different time scales. We demonstrate the effectiveness of our framework in predicting temporal patterns and its potential applications.
Mirror descent of Hopfield model
Nov 29, 2022Mirror descent is a gradient descent method that uses a dual space of parametric models. The great idea has been developed in convex optimization, but not yet widely applied in machine learning. In this study, we provide a possible way that the mirror descent can help data-driven parameter initialization of neural networks. We adopt the Hopfield model as a prototype of neural networks, we demonstrate that the mirror descent can train the model more effectively than the usual gradient descent with random parameter initialization.
KorNLI and KorSTS: New Benchmark Datasets for Korean Natural Language Understanding
Apr 08, 2020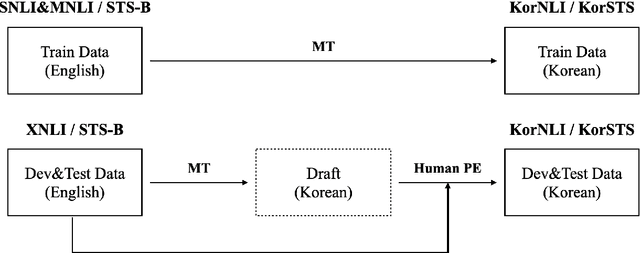
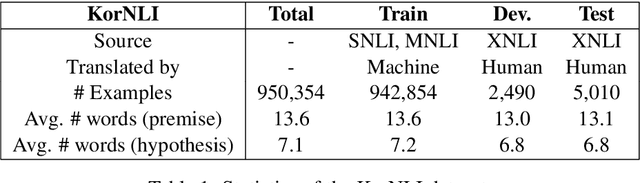
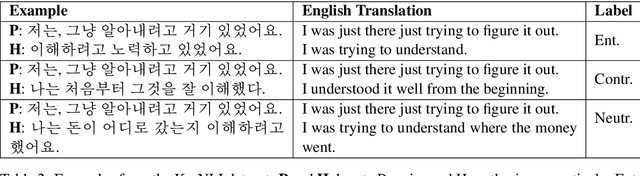
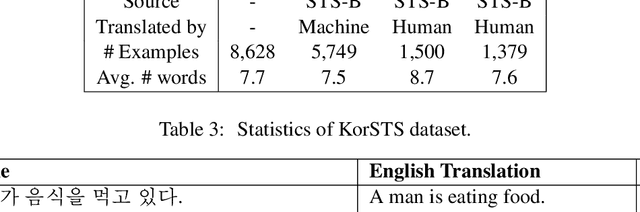
Natural language inference (NLI) and semantic textual similarity (STS) are key tasks in natural language understanding (NLU). Although several benchmark datasets for those tasks have been released in English and a few other languages, there are no publicly available NLI or STS datasets in the Korean language. Motivated by this, we construct and release new datasets for Korean NLI and STS, dubbed KorNLI and KorSTS, respectively. Following previous approaches, we machine-translate existing English training sets and manually translate development and test sets into Korean. To accelerate research on Korean NLU, we also establish baselines on KorNLI and KorSTS. Our datasets are made publicly available via our GitHub repository.