 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiplicative Learning
Paper and Code
Mar 13, 2025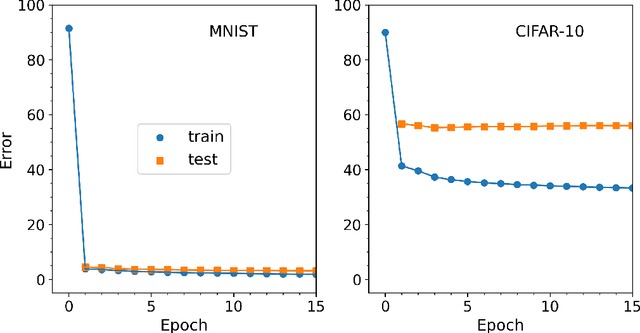
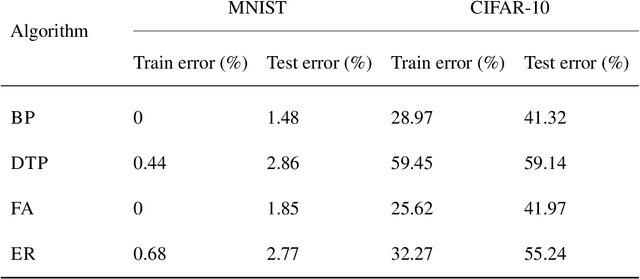
Efficient training of artificial neural networks remains a key challenge in deep learning. Backpropagation (BP), the standard learning algorithm, relies on gradient descent and typically requires numerous iterations for convergence. In this study, we introduce Expectation Reflection (ER), a novel learning approach that updates weights multiplicatively based on the ratio of observed to predicted outputs. Unlike traditional methods, ER maintains consistency without requiring ad hoc loss functions or learning rate hyperparameters. We extend ER to multilayer networks and demonstrate its effectiveness in performing image classification tasks. Notably, ER achieves optimal weight updates in a single iteration. Additionally, we reinterpret ER as a modified form of gradient descent incorporating the inverse mapping of target propagation. These findings suggest that ER provides an efficient and scalable alternative for training neural networks.