 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-HATERS: A Hate Speech Detection Corpus in Korean with Target-Specific Ratings
Oct 24, 2023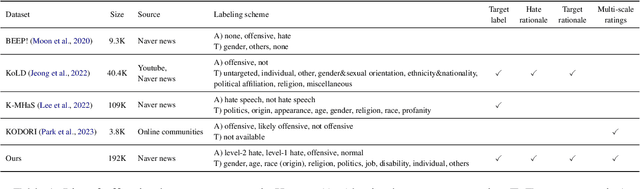


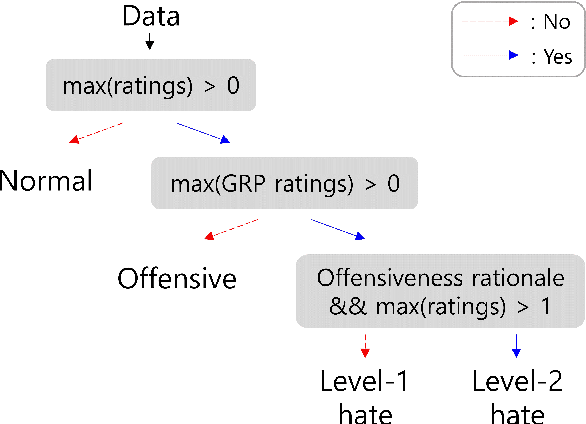
Numerous datasets have been proposed to combat the spread of online hate. Despite these efforts, a majority of these resources are English-centric, primarily focusing on overt forms of hate. This research gap calls for developing high-quality corpora in diverse languages that also encapsulate more subtle hate expressions. This study introduces K-HATERS, a new corpus for hate speech detection in Korean, comprising approximately 192K news comments with target-specific offensiveness ratings. This resource is the largest offensive language corpus in Korean and is the first to offer target-specific ratings on a three-point Likert scale, enabling the detection of hate expressions in Korean across varying degrees of offensiveness. We conduct experiments showing the effectiveness of the proposed corpus, including a comparison with existing datasets. Additionally, to address potential noise and bias in human annotations, we explore a novel idea of adopting the Cognitive Reflection Test, which is widely used in social science for assessing an individual's cognitive ability, as a proxy of labeling quality. Findings indicate that annotations from individuals with the lowest test scores tend to yield detection models that make biased predictions toward specific target groups and are less accurate. This study contributes to the NLP research on hate speech detection and resource construction. The code and dataset can be accessed at https://github.com/ssu-humane/K-HATERS.
A Technical Report for Polyglot-Ko: Open-Source Large-Scale Korean Language Models
Jun 06, 2023Polyglot is a pioneering project aimed at enhancing the non-English language performance of multilingual language models. Despite the availability of various multilingual models such as mBERT (Devlin et al., 2019), XGLM (Lin et al., 2022), and BLOOM (Scao et al., 2022), researchers and developers often resort to building monolingual models in their respective languages due to the dissatisfaction with the current multilingual models non-English language capabilities. Addressing this gap, we seek to develop advanced multilingual language models that offer improved performance in non-English languages. In this paper, we introduce the Polyglot Korean models, which represent a specific focus rather than being multilingual in nature. In collaboration with TUNiB, our team collected 1.2TB of Korean data meticulously curated for our research journey. We made a deliberate decision to prioritize the development of Korean models before venturing into multilingual models. This choice was motivated by multiple factors: firstly, the Korean models facilitated performance comparisons with existing multilingual models; and finally, they catered to the specific needs of Korean companies and researchers. This paper presents our work in developing the Polyglot Korean models, which propose some steps towards addressing the non-English language performance gap in multilingual language models.
An Empirical Study of Tokenization Strategies for Various Korean NLP Tasks
Oct 06, 2020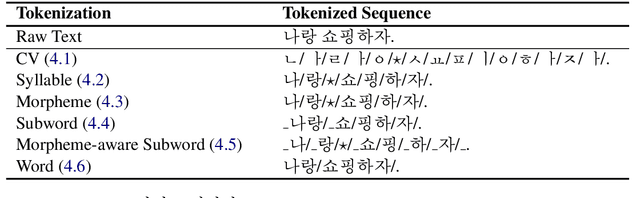
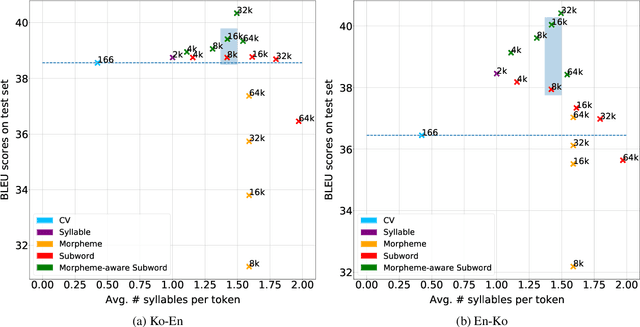
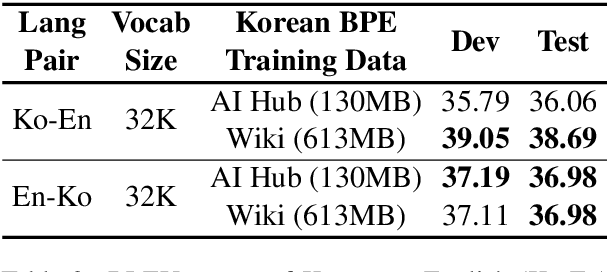
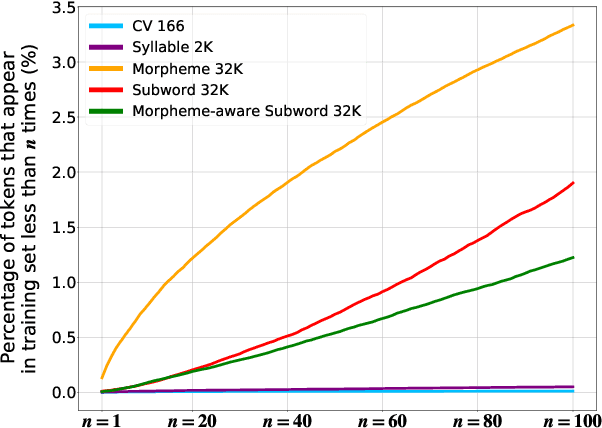
Typically, tokenization is the very first step in most text processing works. As a token serves as an atomic unit that embeds the contextual information of text, how to define a token plays a decisive role in the performance of a model.Even though Byte Pair Encoding (BPE) has been considered the de facto standard tokenization method due to its simplicity and universality, it still remains unclear whether BPE works best across all languages and tasks. In this paper, we test several tokenization strategies in order to answer our primary research question, that is, "What is the best tokenization strategy for Korean NLP tasks?" Experimental results demonstrate that a hybrid approach of morphological segmentation followed by BPE works best in Korean to/from English machine translation and natural language understanding tasks such as KorNLI, KorSTS, NSMC, and PAWS-X. As an exception, for KorQuAD, the Korean extension of SQuAD, BPE segmentation turns out to be the most effective.
KoParadigm: A Korean Conjugation Paradigm Generator
Apr 28, 2020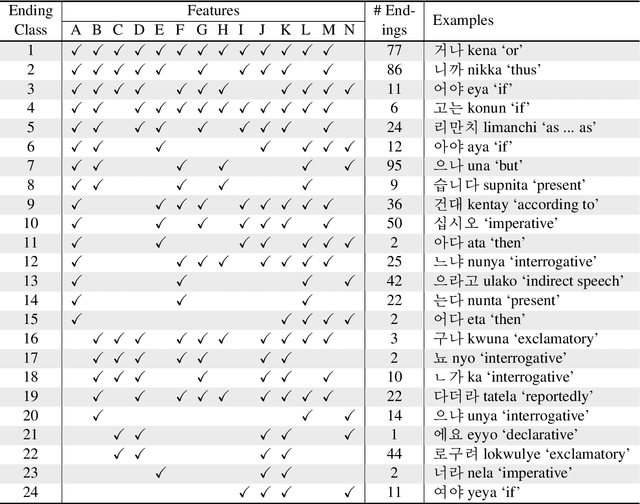
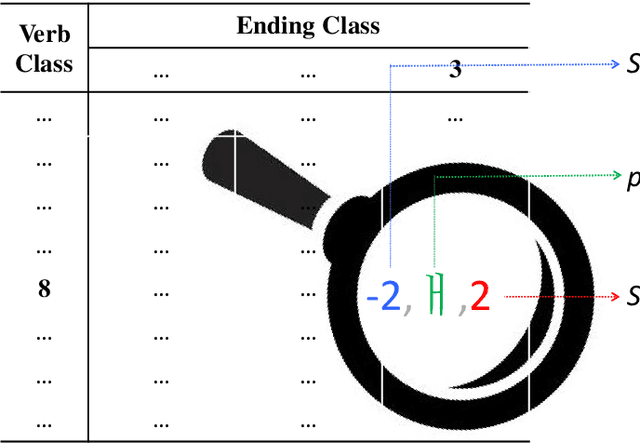
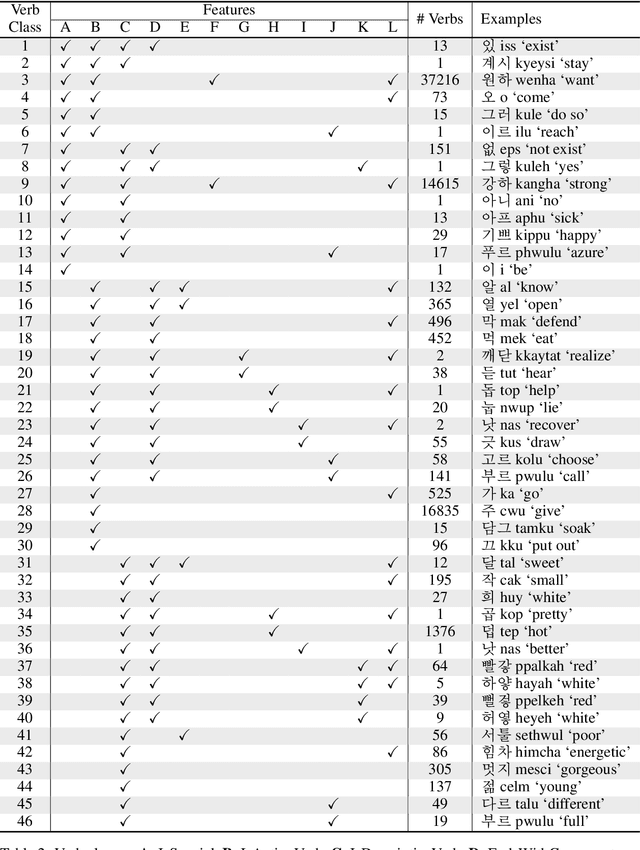

Korean is a morphologically rich language. Korean verbs change their forms in a fickle manner depending on tense, mood, speech level, meaning, etc. Therefore, it is challenging to construct comprehensive conjugation paradigms of Korean verbs. In this paper we introduce a Korean (verb) conjugation paradigm generator, dubbed KoParadigm. To the best of our knowledge, it is the first Korean conjugation module that covers all contemporary Korean verbs and endings. KoParadigm is not only linguistically well established, but also computationally simple and efficient. We share it via PyPi.
An Empirical Study of Invariant Risk Minimization
Apr 10, 2020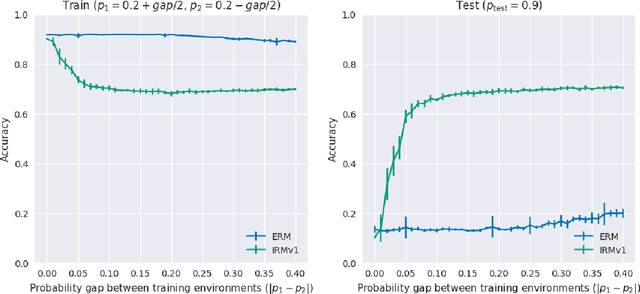
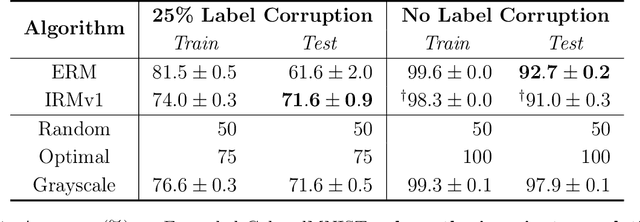
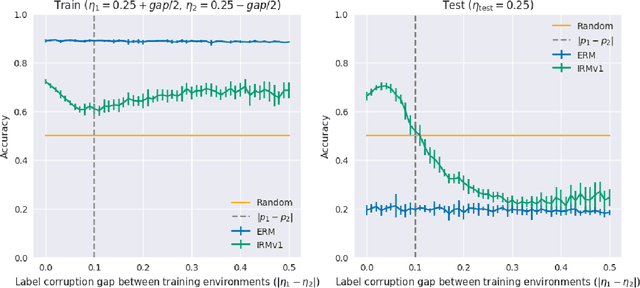

Invariant risk minimization (IRM; Arjovsky et al., 2019) is a recently proposed framework designed for learning predictors that are invariant to spurious correlations across different training environments. Because IRM does not assume that the test data is identically distributed as the training data, it can allow models to learn invariances that generalize well on unseen and out-of-distribution (OOD) samples. Yet, despite this theoretical justification, IRM has not been extensively tested across various settings. In an attempt to gain a better understanding of IRM, we empirically investigate several research questions using IRMv1, which is the first practical algorithm proposed in (Arjovsky et al., 2019) to approximately solve IRM. By extending the ColoredMNIST experiment from (Arjovsky et al., 2019) in multiple ways, we find that IRMv1 (i) performs better as the spurious correlation varies more widely between training environments, (ii) learns an approximately invariant predictor when the underlying relationship is approximately invariant, and (iii) can be extended to multiple environments, multiple outcomes, and different modalities (i.e., text). We hope that this work will shed light on the characteristics of IRM and help with applying IRM to real-world OOD generalization tasks.
KorNLI and KorSTS: New Benchmark Datasets for Korean Natural Language Understanding
Apr 08, 2020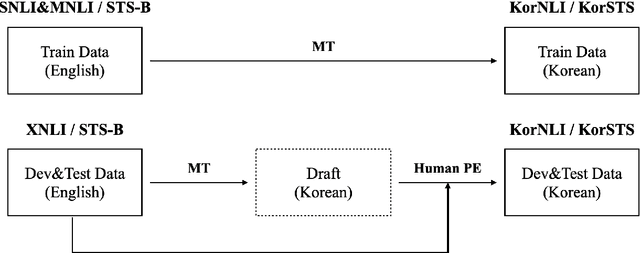
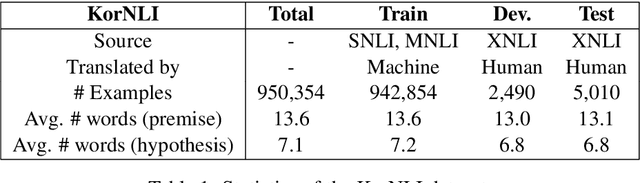
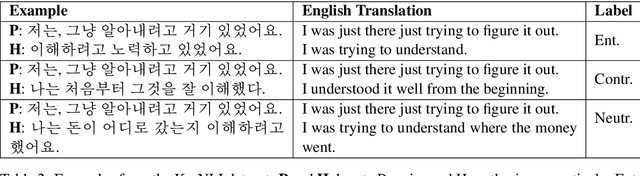
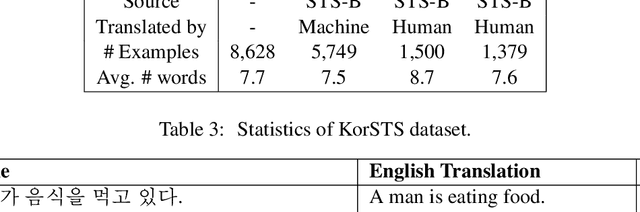
Natural language inference (NLI) and semantic textual similarity (STS) are key tasks in natural language understanding (NLU). Although several benchmark datasets for those tasks have been released in English and a few other languages, there are no publicly available NLI or STS datasets in the Korean language. Motivated by this, we construct and release new datasets for Korean NLI and STS, dubbed KorNLI and KorSTS, respectively. Following previous approaches, we machine-translate existing English training sets and manually translate development and test sets into Korean. To accelerate research on Korean NLU, we also establish baselines on KorNLI and KorSTS. Our datasets are made publicly available via our GitHub repository.
g2pM: A Neural Grapheme-to-Phoneme Conversion Package for MandarinChinese Based on a New Open Benchmark Dataset
Apr 07, 2020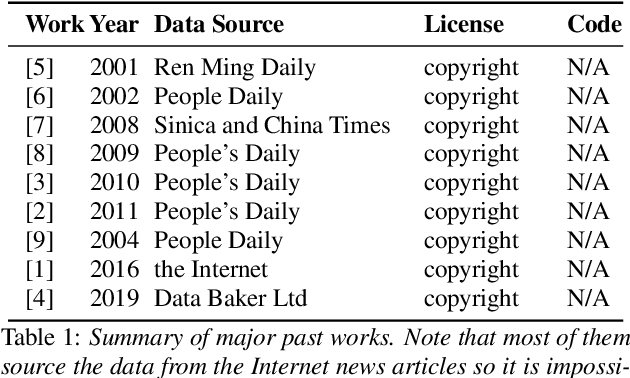
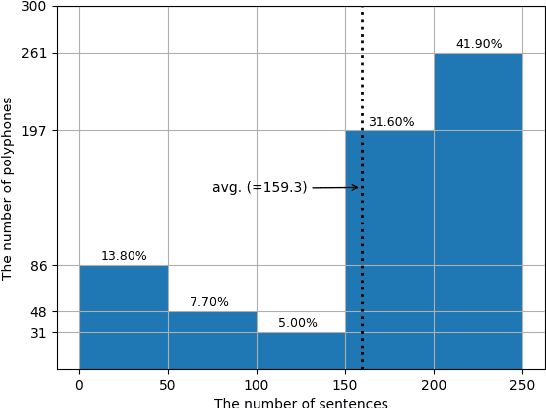
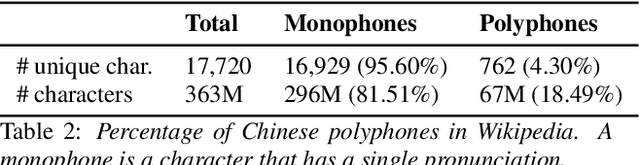
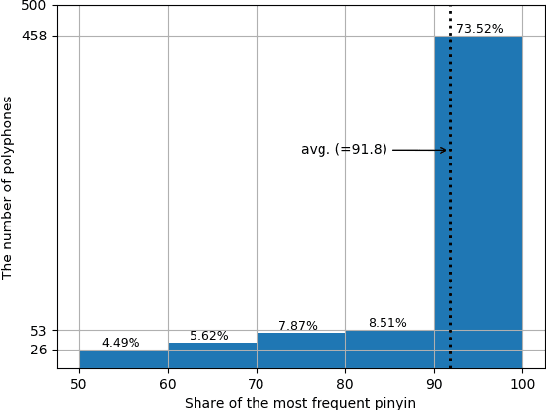
Conversion of Chinese graphemes to phonemes (G2P) is an essential component in Mandarin Chinese Text-To-Speech (TTS) systems. One of the biggest challenges in Chinese G2P conversion is how to disambiguate the pronunciation of polyphones -- characters having multiple pronunciations. Although many academic efforts have been made to address it, there has been no open dataset that can serve as a standard benchmark for fair comparison to date. In addition, most of the reported systems are hard to employ for researchers or practitioners who want to convert Chinese text into pinyin at their convenience. Motivated by these, in this work, we introduce a new benchmark dataset that consists of 99,000+ sentences for Chinese polyphone disambiguation. We train a simple neural network model on it, and find that it outperforms other preexisting G2P systems. Finally, we package our project and share it on PyPi.
Jejueo Datasets for Machine Translation and Speech Synthesis
Nov 27, 2019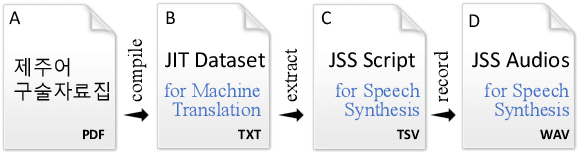
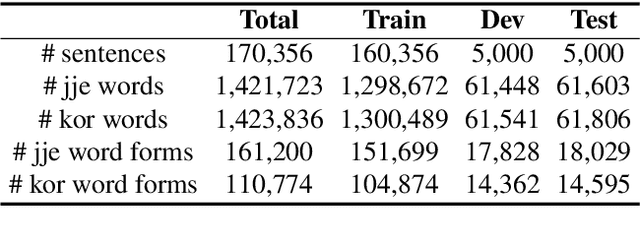
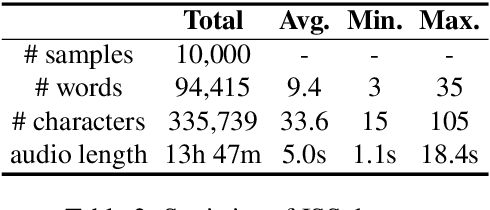
Jejueo was classified as critically endangered by UNESCO in 2010. Although diverse efforts to revitalize it have been made, there have been few computational approaches. Motivated by this, we construct two new Jejueo datasets: Jejueo Interview Transcripts (JIT) and Jejueo Single Speaker Speech (JSS). The JIT dataset is a parallel corpus containing 170k+ Jejueo-Korean sentences, and the JSS dataset consists of 10k high-quality audio files recorded by a native Jejueo speaker and a transcript file. Subsequently, we build neural systems of machine translation and speech synthesis using them. All resources are publicly available via our GitHub repository. We hope that these datasets will attract interest of both language and machine learning communities.
word2word: A Collection of Bilingual Lexicons for 3,564 Language Pairs
Nov 27, 2019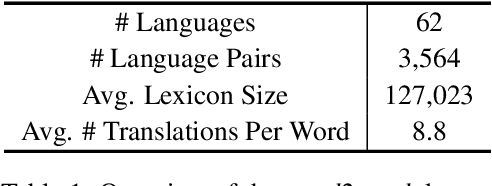
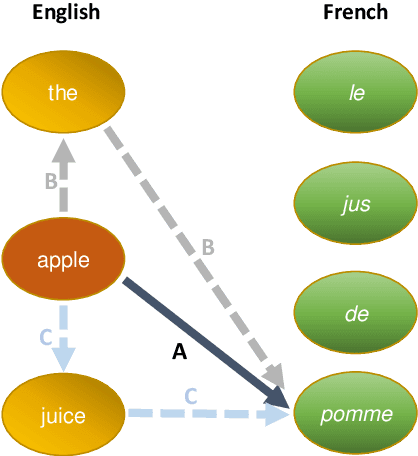
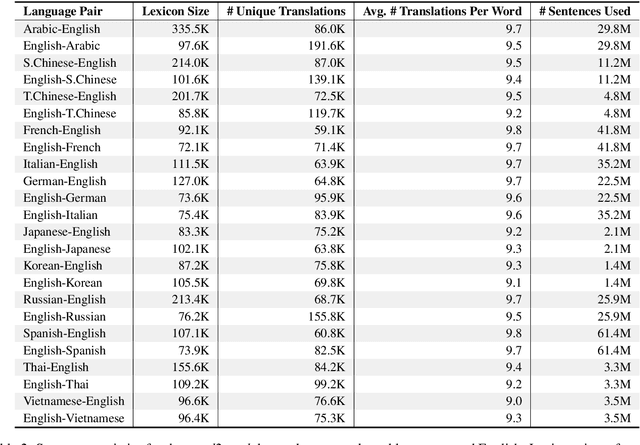

We present word2word, a publicly available dataset and an open-source Python package for cross-lingual word translations extracted from sentence-level parallel corpora. Our dataset provides top-k word translations in 3,564 (directed) language pairs across 62 languages in OpenSubtitles2018 (Lison et al., 2018). To obtain this dataset, we use a count-based bilingual lexicon extraction model based on the observation that not only source and target words but also source words themselves can be highly correlated. We illustrate that the resulting bilingual lexicons have high coverage and attain competitive translation quality for several language pairs. We wrap our dataset and model in an easy-to-use Python library, which supports downloading and retrieving top-k word translations in any of the supported language pairs as well as computing top-k word translations for custom parallel corpora.
A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
Jul 02, 2019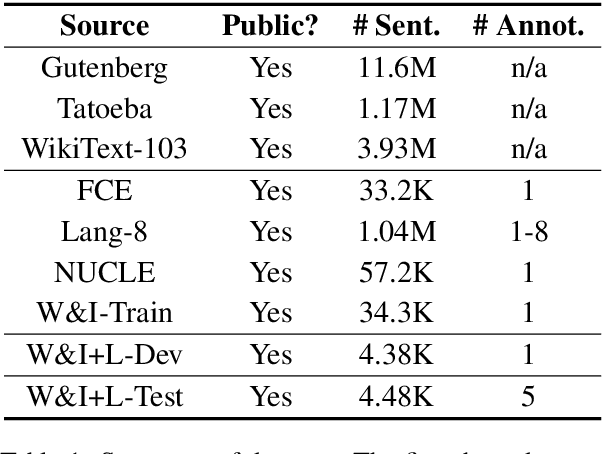

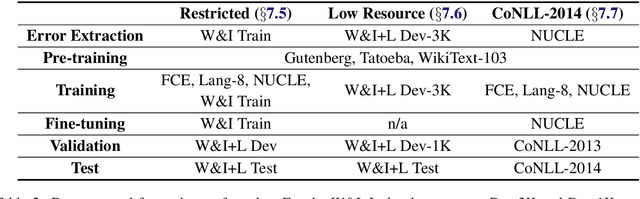
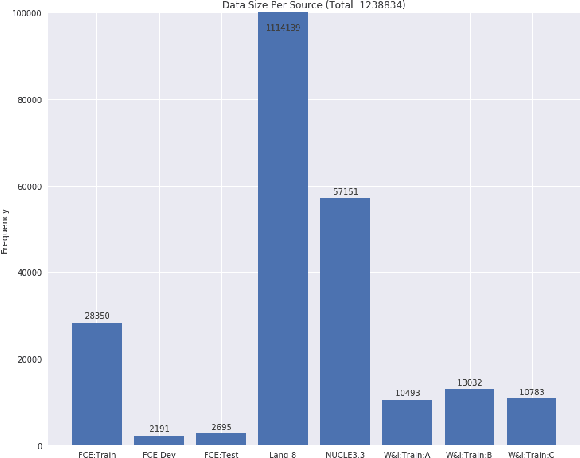
Grammatical error correction can be viewed as a low-resource sequence-to-sequence task, because publicly available parallel corpora are limited. To tackle this challenge, we first generate erroneous versions of large unannotated corpora using a realistic noising function. The resulting parallel corpora are subsequently used to pre-train Transformer models. Then, by sequentially applying transfer learning, we adapt these models to the domain and style of the test set. Combined with a context-aware neural spellchecker, our system achieves competitive results in both restricted and low resource tracks in ACL 2019 BEA Shared Task. We release all of our code and materials for reproducibility.