 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom What to Respond to When to Respond: Timely Response Generation for Open-domain Dialogue Agents
Jun 17, 2025While research on dialogue response generation has primarily focused on generating coherent responses conditioning on textual context, the critical question of when to respond grounded on the temporal context remains underexplored. To bridge this gap, we propose a novel task called timely dialogue response generation and introduce the TimelyChat benchmark, which evaluates the capabilities of language models to predict appropriate time intervals and generate time-conditioned responses. Additionally, we construct a large-scale training dataset by leveraging unlabeled event knowledge from a temporal commonsense knowledge graph and employing a large language model (LLM) to synthesize 55K event-driven dialogues. We then train Timer, a dialogue agent designed to proactively predict time intervals and generate timely responses that align with those intervals. Experimental results show that Timer outperforms prompting-based LLMs and other fine-tuned baselines in both turn-level and dialogue-level evaluations. We publicly release our data, model, and code.
On the Effectiveness of Integration Methods for Multimodal Dialogue Response Retrieval
Jun 13, 2025Multimodal chatbots have become one of the major topics for dialogue systems in both research community and industry. Recently, researchers have shed light on the multimodality of responses as well as dialogue contexts. This work explores how a dialogue system can output responses in various modalities such as text and image. To this end, we first formulate a multimodal dialogue response retrieval task for retrieval-based systems as the combination of three subtasks. We then propose three integration methods based on a two-step approach and an end-to-end approach, and compare the merits and demerits of each method. Experimental results on two datasets demonstrate that the end-to-end approach achieves comparable performance without an intermediate step in the two-step approach. In addition, a parameter sharing strategy not only reduces the number of parameters but also boosts performance by transferring knowledge across the subtasks and the modalities.
Exploring Language Model's Code Generation Ability with Auxiliary Functions
Mar 15, 2024



Auxiliary function is a helpful component to improve language model's code generation ability. However, a systematic exploration of how they affect has yet to be done. In this work, we comprehensively evaluate the ability to utilize auxiliary functions encoded in recent code-pretrained language models. First, we construct a human-crafted evaluation set, called HumanExtension, which contains examples of two functions where one function assists the other. With HumanExtension, we design several experiments to examine their ability in a multifaceted way. Our evaluation processes enable a comprehensive understanding of including auxiliary functions in the prompt in terms of effectiveness and robustness. An additional implementation style analysis captures the models' various implementation patterns when they access the auxiliary function. Through this analysis, we discover the models' promising ability to utilize auxiliary functions including their self-improving behavior by implementing the two functions step-by-step. However, our analysis also reveals the model's underutilized behavior to call the auxiliary function, suggesting the future direction to enhance their implementation by eliciting the auxiliary function call ability encoded in the models. We release our code and dataset to facilitate this research direction.
KoDialogBench: Evaluating Conversational Understanding of Language Models with Korean Dialogue Benchmark
Feb 27, 2024As language models are often deployed as chatbot assistants, it becomes a virtue for models to engage in conversations in a user's first language. While these models are trained on a wide range of languages, a comprehensive evaluation of their proficiency in low-resource languages such as Korean has been lacking. In this work, we introduce KoDialogBench, a benchmark designed to assess language models' conversational capabilities in Korean. To this end, we collect native Korean dialogues on daily topics from public sources, or translate dialogues from other languages. We then structure these conversations into diverse test datasets, spanning from dialogue comprehension to response selection tasks. Leveraging the proposed benchmark, we conduct extensive evaluations and analyses of various language models to measure a foundational understanding of Korean dialogues. Experimental results indicate that there exists significant room for improvement in models' conversation skills. Furthermore, our in-depth comparisons across different language models highlight the effectiveness of recent training techniques in enhancing conversational proficiency. We anticipate that KoDialogBench will promote the progress towards conversation-aware Korean language models.
Toward Interpretable Semantic Textual Similarity via Optimal Transport-based Contrastive Sentence Learning
Feb 26, 2022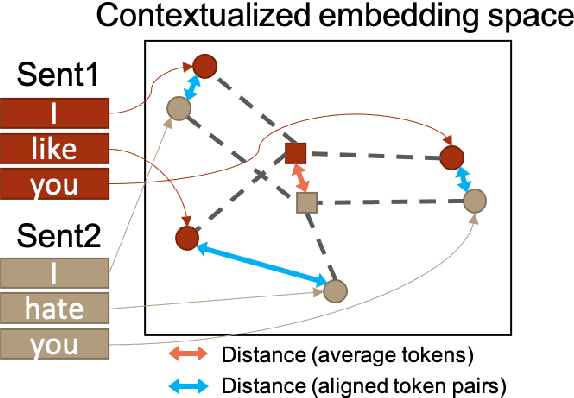
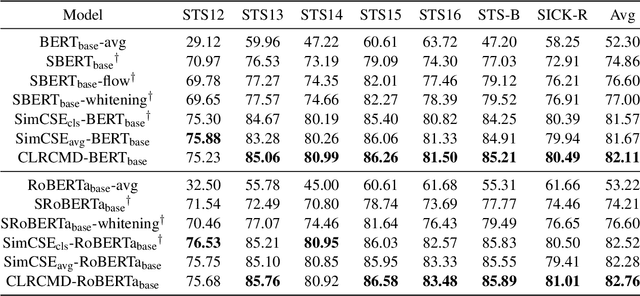

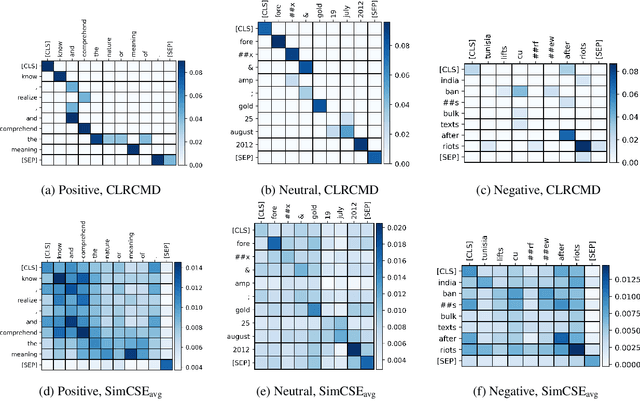
Recently, finetuning a pretrained language model to capture the similarity between sentence embeddings has shown the state-of-the-art performance on the semantic textual similarity (STS) task. However, the absence of an interpretation method for the sentence similarity makes it difficult to explain the model output. In this work, we explicitly describe the sentence distance as the weighted sum of contextualized token distances on the basis of a transportation problem, and then present the optimal transport-based distance measure, named RCMD; it identifies and leverages semantically-aligned token pairs. In the end, we propose CLRCMD, a contrastive learning framework that optimizes RCMD of sentence pairs, which enhances the quality of sentence similarity and their interpretation. Extensive experiments demonstrate that our learning framework outperforms other baselines on both STS and interpretable-STS benchmarks, indicating that it computes effective sentence similarity and also provides interpretation consistent with human judgement.
KLUE: Korean Language Understanding Evaluation
Jun 11, 2021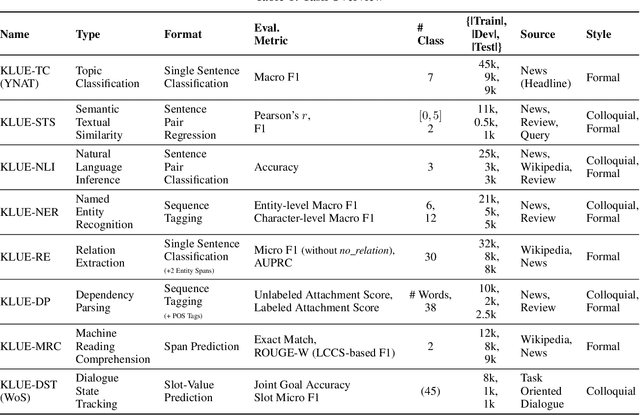
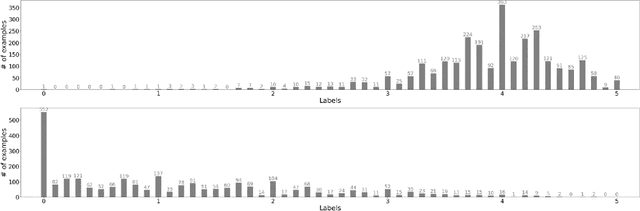
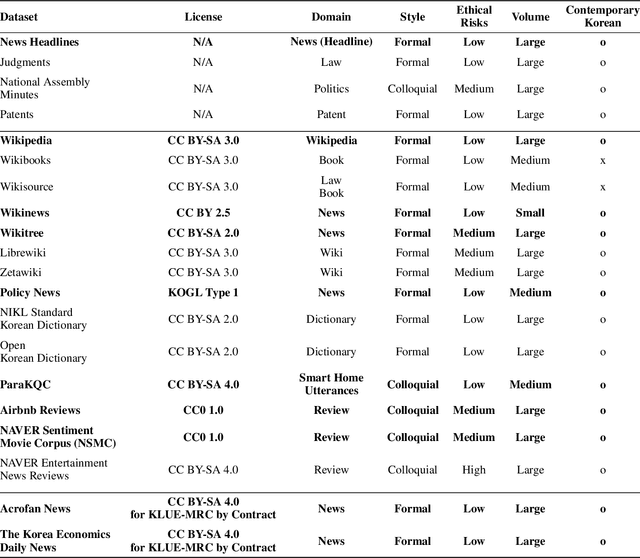
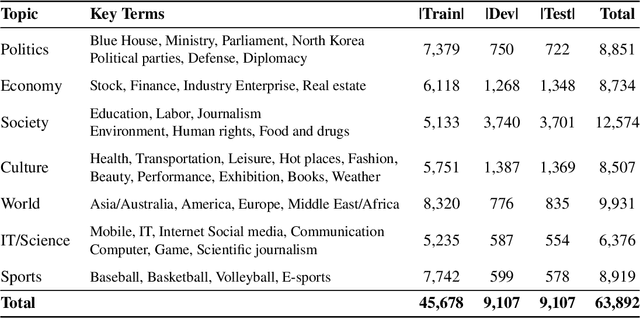
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.
An Empirical Study of Tokenization Strategies for Various Korean NLP Tasks
Oct 06, 2020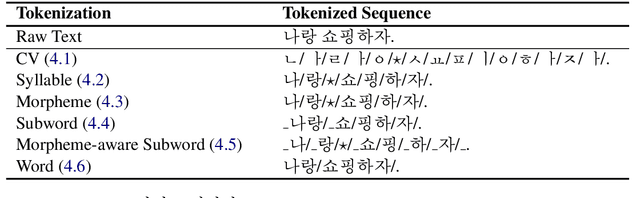
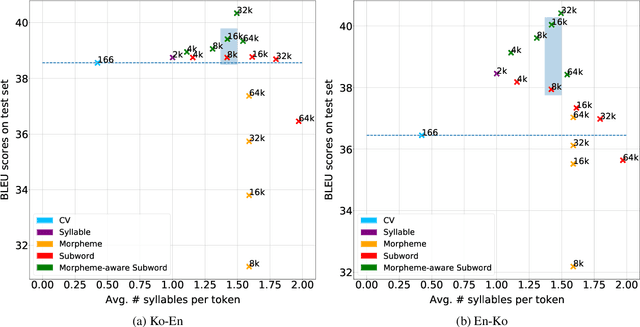
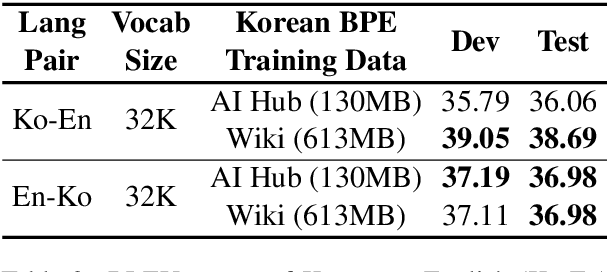
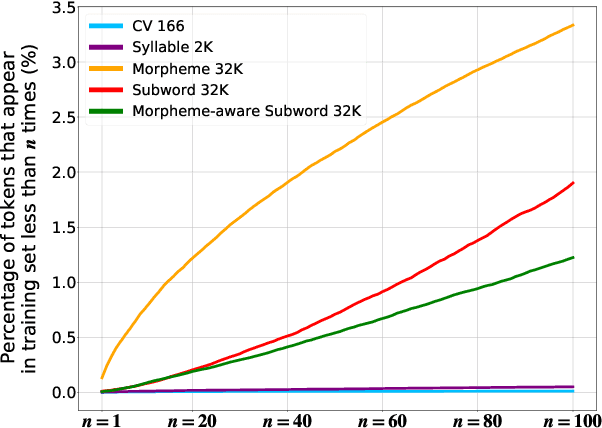
Typically, tokenization is the very first step in most text processing works. As a token serves as an atomic unit that embeds the contextual information of text, how to define a token plays a decisive role in the performance of a model.Even though Byte Pair Encoding (BPE) has been considered the de facto standard tokenization method due to its simplicity and universality, it still remains unclear whether BPE works best across all languages and tasks. In this paper, we test several tokenization strategies in order to answer our primary research question, that is, "What is the best tokenization strategy for Korean NLP tasks?" Experimental results demonstrate that a hybrid approach of morphological segmentation followed by BPE works best in Korean to/from English machine translation and natural language understanding tasks such as KorNLI, KorSTS, NSMC, and PAWS-X. As an exception, for KorQuAD, the Korean extension of SQuAD, BPE segmentation turns out to be the most effective.