 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilling the Gaps: Selective Knowledge Augmentation for LLM Recommenders
Apr 09, 2026Large language models (LLMs) have recently emerged as powerful training-free recommenders. However, their knowledge of individual items is inevitably uneven due to imbalanced information exposure during pretraining, a phenomenon we refer to as knowledge gap problem. To address this, most prior methods have employed a naive uniform augmentation that appends external information for every item in the input prompt. However, this approach not only wastes limited context budget on redundant augmentation for well-known items but can also hinder the model's effective reasoning. To this end, we propose KnowSA_CKP (Knowledge-aware Selective Augmentation with Comparative Knowledge Probing) to mitigate the knowledge gap problem. KnowSA_CKP estimates the LLM's internal knowledge by evaluating its capability to capture collaborative relationships and selectively injects additional information only where it is most needed. By avoiding unnecessary augmentation for well-known items, KnowSA_CKP focuses on items that benefit most from knowledge supplementation, thereby making more effective use of the context budget. KnowSA_CKP requires no fine-tuning step, and consistently improves both recommendation accuracy and context efficiency across four real-world datasets.
Dynamic Multi-period Experts for Online Time Series Forecasting
Mar 10, 2026Online Time Series Forecasting (OTSF) requires models to continuously adapt to concept drift. However, existing methods often treat concept drift as a monolithic phenomenon. To address this limitation, we first redefine concept drift by categorizing it into two distinct types: Recurring Drift, where previously seen patterns reappear, and Emergent Drift, where entirely new patterns emerge. We then propose DynaME (Dynamic Multi-period Experts), a novel hybrid framework designed to effectively address this dual nature of drift. For Recurring Drift, DynaME employs a committee of specialized experts that are dynamically fitted to the most relevant historical periodic patterns at each time step. For Emergent Drift, the framework detects high-uncertainty scenarios and shifts reliance to a stable, general expert. Extensive experiments on several benchmark datasets and backbones demonstrate that DynaME effectively adapts to both concept drifts and significantly outperforms existing baselines.
Harmonic Dataset Distillation for Time Series Forecasting
Mar 04, 2026Time Series forecasting (TSF) in the modern era faces significant computational and storage cost challenges due to the massive scale of real-world data. Dataset Distillation (DD), a paradigm that synthesizes a small, compact dataset to achieve training performance comparable to that of the original dataset, has emerged as a promising solution. However, conventional DD methods are not tailored for time series and suffer from architectural overfitting and limited scalability. To address these issues, we propose Harmonic Dataset Distillation for Time Series Forecasting (HDT). HDT decomposes the time series into its sinusoidal basis through the FFT and aligns the core periodic structure by Harmonic Matching. Since this process operates in the frequency domain, all updates during distillation are applied globally without disrupting temporal dependencies of time series. Extensive experiments demonstrate that HDT achieves strong cross-architecture generalization and scalability, validating its practicality for large-scale, real-world applications.
STEPER: Step-wise Knowledge Distillation for Enhancing Reasoning Ability in Multi-Step Retrieval-Augmented Language Models
Oct 09, 2025Answering complex real-world questions requires step-by-step retrieval and integration of relevant information to generate well-grounded responses. However, existing knowledge distillation methods overlook the need for different reasoning abilities at different steps, hindering transfer in multi-step retrieval-augmented frameworks. To address this, we propose Stepwise Knowledge Distillation for Enhancing Reasoning Ability in Multi-Step Retrieval-Augmented Language Models (StepER). StepER employs step-wise supervision to align with evolving information and reasoning demands across stages. Additionally, it incorporates difficulty-aware training to progressively optimize learning by prioritizing suitable steps. Our method is adaptable to various multi-step retrieval-augmented language models, including those that use retrieval queries for reasoning paths or decomposed questions. Extensive experiments show that StepER outperforms prior methods on multi-hop QA benchmarks, with an 8B model achieving performance comparable to a 70B teacher model.
Uncertainty Quantification and Decomposition for LLM-based Recommendation
Jan 29, 2025Despite the widespread adoption of large language models (LLMs) for recommendation, we demonstrate that LLMs often exhibit uncertainty in their recommendations. To ensure the trustworthy use of LLMs in generating recommendations, we emphasize the importance of assessing the reliability of recommendations generated by LLMs. We start by introducing a novel framework for estimating the predictive uncertainty to quantitatively measure the reliability of LLM-based recommendations. We further propose to decompose the predictive uncertainty into recommendation uncertainty and prompt uncertainty, enabling in-depth analyses of the primary source of uncertainty. Through extensive experiments, we (1) demonstrate predictive uncertainty effectively indicates the reliability of LLM-based recommendations, (2) investigate the origins of uncertainty with decomposed uncertainty measures, and (3) propose uncertainty-aware prompting for a lower predictive uncertainty and enhanced recommendation. Our source code and model weights are available at https://github.com/WonbinKweon/UNC_LLM_REC_WWW2025
Learning Discriminative Dynamics with Label Corruption for Noisy Label Detection
May 30, 2024Label noise, commonly found in real-world datasets, has a detrimental impact on a model's generalization. To effectively detect incorrectly labeled instances, previous works have mostly relied on distinguishable training signals, such as training loss, as indicators to differentiate between clean and noisy labels. However, they have limitations in that the training signals incompletely reveal the model's behavior and are not effectively generalized to various noise types, resulting in limited detection accuracy. In this paper, we propose DynaCor framework that distinguishes incorrectly labeled instances from correctly labeled ones based on the dynamics of the training signals. To cope with the absence of supervision for clean and noisy labels, DynaCor first introduces a label corruption strategy that augments the original dataset with intentionally corrupted labels, enabling indirect simulation of the model's behavior on noisy labels. Then, DynaCor learns to identify clean and noisy instances by inducing two clearly distinguishable clusters from the latent representations of training dynamics. Our comprehensive experiments show that DynaCor outperforms the state-of-the-art competitors and shows strong robustness to various noise types and noise rates.
Rectifying Demonstration Shortcut in In-Context Learning
Mar 29, 2024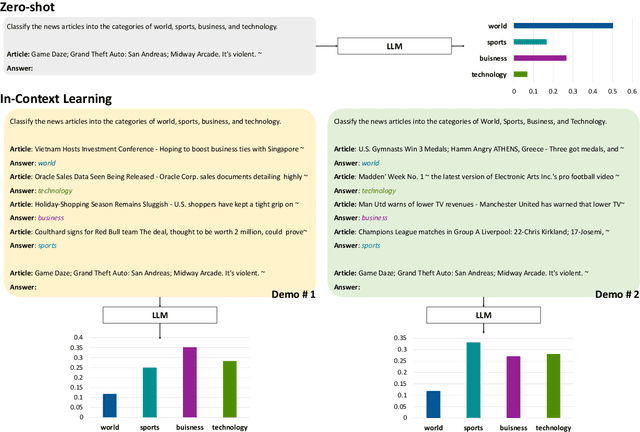



Large language models (LLMs) are able to solve various tasks with only a few demonstrations utilizing their in-context learning (ICL) abilities. However, LLMs often rely on their pre-trained semantic priors of demonstrations rather than on the input-label relationships to proceed with ICL prediction. In this work, we term this phenomenon as the 'Demonstration Shortcut'. While previous works have primarily focused on improving ICL prediction results for predefined tasks, we aim to rectify the Demonstration Shortcut, thereby enabling the LLM to effectively learn new input-label relationships from demonstrations. To achieve this, we introduce In-Context Calibration, a demonstration-aware calibration method. We evaluate the effectiveness of the proposed method in two settings: (1) the Original ICL Task using the standard label space and (2) the Task Learning setting, where the label space is replaced with semantically unrelated tokens. In both settings, In-Context Calibration demonstrates substantial improvements, with results generalized across three LLM families (OPT, GPT, and Llama2) under various configurations.
Multi-Domain Recommendation to Attract Users via Domain Preference Modeling
Mar 26, 2024Recently, web platforms have been operating various service domains simultaneously. Targeting a platform that operates multiple service domains, we introduce a new task, Multi-Domain Recommendation to Attract Users (MDRAU), which recommends items from multiple ``unseen'' domains with which each user has not interacted yet, by using knowledge from the user's ``seen'' domains. In this paper, we point out two challenges of MDRAU task. First, there are numerous possible combinations of mappings from seen to unseen domains because users have usually interacted with a different subset of service domains. Second, a user might have different preferences for each of the target unseen domains, which requires that recommendations reflect the user's preferences on domains as well as items. To tackle these challenges, we propose DRIP framework that models users' preferences at two levels (i.e., domain and item) and learns various seen-unseen domain mappings in a unified way with masked domain modeling. Our extensive experiments demonstrate the effectiveness of DRIP in MDRAU task and its ability to capture users' domain-level preferences.
Exploring Language Model's Code Generation Ability with Auxiliary Functions
Mar 15, 2024



Auxiliary function is a helpful component to improve language model's code generation ability. However, a systematic exploration of how they affect has yet to be done. In this work, we comprehensively evaluate the ability to utilize auxiliary functions encoded in recent code-pretrained language models. First, we construct a human-crafted evaluation set, called HumanExtension, which contains examples of two functions where one function assists the other. With HumanExtension, we design several experiments to examine their ability in a multifaceted way. Our evaluation processes enable a comprehensive understanding of including auxiliary functions in the prompt in terms of effectiveness and robustness. An additional implementation style analysis captures the models' various implementation patterns when they access the auxiliary function. Through this analysis, we discover the models' promising ability to utilize auxiliary functions including their self-improving behavior by implementing the two functions step-by-step. However, our analysis also reveals the model's underutilized behavior to call the auxiliary function, suggesting the future direction to enhance their implementation by eliciting the auxiliary function call ability encoded in the models. We release our code and dataset to facilitate this research direction.
Top-Personalized-K Recommendation
Feb 26, 2024The conventional top-K recommendation, which presents the top-K items with the highest ranking scores, is a common practice for generating personalized ranking lists. However, is this fixed-size top-K recommendation the optimal approach for every user's satisfaction? Not necessarily. We point out that providing fixed-size recommendations without taking into account user utility can be suboptimal, as it may unavoidably include irrelevant items or limit the exposure to relevant ones. To address this issue, we introduce Top-Personalized-K Recommendation, a new recommendation task aimed at generating a personalized-sized ranking list to maximize individual user satisfaction. As a solution to the proposed task, we develop a model-agnostic framework named PerK. PerK estimates the expected user utility by leveraging calibrated interaction probabilities, subsequently selecting the recommendation size that maximizes this expected utility. Through extensive experiments on real-world datasets, we demonstrate the superiority of PerK in Top-Personalized-K recommendation task. We expect that Top-Personalized-K recommendation has the potential to offer enhanced solutions for various real-world recommendation scenarios, based on its great compatibility with existing models.