 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Historical and Current Interests for Continual Sequential Recommendation
Jun 09, 2025Sequential recommendation models based on the Transformer architecture show superior performance in harnessing long-range dependencies within user behavior via self-attention. However, naively updating them on continuously arriving non-stationary data streams incurs prohibitive computation costs or leads to catastrophic forgetting. To address this, we propose Continual Sequential Transformer for Recommendation (CSTRec) that effectively leverages well-preserved historical user interests while capturing current interests. At its core is Continual Sequential Attention (CSA), a linear attention mechanism that retains past knowledge without direct access to old data. CSA integrates two key components: (1) Cauchy-Schwarz Normalization that stabilizes training under uneven interaction frequencies, and (2) Collaborative Interest Enrichment that mitigates forgetting through shared, learnable interest pools. We further introduce a technique that facilitates learning for cold-start users by transferring historical knowledge from behaviorally similar existing users. Extensive experiments on three real-world datasets indicate that CSTRec outperforms state-of-the-art baselines in both knowledge retention and acquisition.
Towards 3D Acceleration for low-power Mixture-of-Experts and Multi-Head Attention Spiking Transformers
Dec 07, 2024Spiking Neural Networks(SNNs) provide a brain-inspired and event-driven mechanism that is believed to be critical to unlock energy-efficient deep learning. The mixture-of-experts approach mirrors the parallel distributed processing of nervous systems, introducing conditional computation policies and expanding model capacity without scaling up the number of computational operations. Additionally, spiking mixture-of-experts self-attention mechanisms enhance representation capacity, effectively capturing diverse patterns of entities and dependencies between visual or linguistic tokens. However, there is currently a lack of hardware support for highly parallel distributed processing needed by spiking transformers, which embody a brain-inspired computation. This paper introduces the first 3D hardware architecture and design methodology for Mixture-of-Experts and Multi-Head Attention spiking transformers. By leveraging 3D integration with memory-on-logic and logic-on-logic stacking, we explore such brain-inspired accelerators with spatially stackable circuitry, demonstrating significant optimization of energy efficiency and latency compared to conventional 2D CMOS integration.
Spiking Transformer Hardware Accelerators in 3D Integration
Nov 11, 2024Spiking neural networks (SNNs) are powerful models of spatiotemporal computation and are well suited for deployment on resource-constrained edge devices and neuromorphic hardware due to their low power consumption. Leveraging attention mechanisms similar to those found in their artificial neural network counterparts, recently emerged spiking transformers have showcased promising performance and efficiency by capitalizing on the binary nature of spiking operations. Recognizing the current lack of dedicated hardware support for spiking transformers, this paper presents the first work on 3D spiking transformer hardware architecture and design methodology. We present an architecture and physical design co-optimization approach tailored specifically for spiking transformers. Through memory-on-logic and logic-on-logic stacking enabled by 3D integration, we demonstrate significant energy and delay improvements compared to conventional 2D CMOS integration.
Multi-Domain Recommendation to Attract Users via Domain Preference Modeling
Mar 26, 2024Recently, web platforms have been operating various service domains simultaneously. Targeting a platform that operates multiple service domains, we introduce a new task, Multi-Domain Recommendation to Attract Users (MDRAU), which recommends items from multiple ``unseen'' domains with which each user has not interacted yet, by using knowledge from the user's ``seen'' domains. In this paper, we point out two challenges of MDRAU task. First, there are numerous possible combinations of mappings from seen to unseen domains because users have usually interacted with a different subset of service domains. Second, a user might have different preferences for each of the target unseen domains, which requires that recommendations reflect the user's preferences on domains as well as items. To tackle these challenges, we propose DRIP framework that models users' preferences at two levels (i.e., domain and item) and learns various seen-unseen domain mappings in a unified way with masked domain modeling. Our extensive experiments demonstrate the effectiveness of DRIP in MDRAU task and its ability to capture users' domain-level preferences.
Deep Rating Elicitation for New Users in Collaborative Filtering
Feb 26, 2024



Recent recommender systems started to use rating elicitation, which asks new users to rate a small seed itemset for inferring their preferences, to improve the quality of initial recommendations. The key challenge of the rating elicitation is to choose the seed items which can best infer the new users' preference. This paper proposes a novel end-to-end Deep learning framework for Rating Elicitation (DRE), that chooses all the seed items at a time with consideration of the non-linear interactions. To this end, it first defines categorical distributions to sample seed items from the entire itemset, then it trains both the categorical distributions and a neural reconstruction network to infer users' preferences on the remaining items from CF information of the sampled seed items. Through the end-to-end training, the categorical distributions are learned to select the most representative seed items while reflecting the complex non-linear interactions. Experimental results show that DRE outperforms the state-of-the-art approaches in the recommendation quality by accurately inferring the new users' preferences and its seed itemset better represents the latent space than the seed itemset obtained by the other methods.
Consensus Learning from Heterogeneous Objectives for One-Class Collaborative Filtering
Feb 26, 2022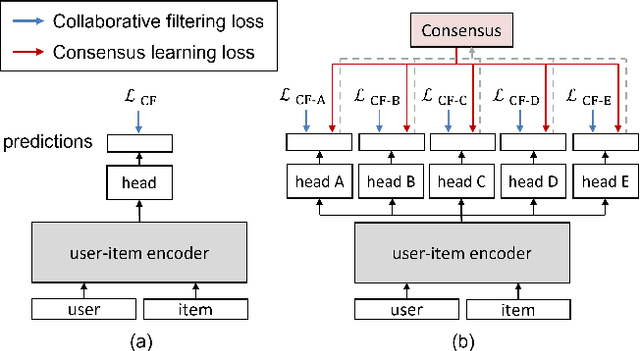


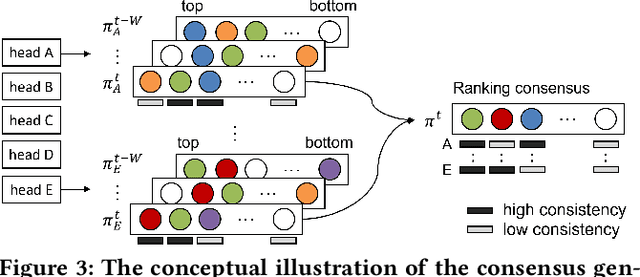
Over the past decades, for One-Class Collaborative Filtering (OCCF), many learning objectives have been researched based on a variety of underlying probabilistic models. From our analysis, we observe that models trained with different OCCF objectives capture distinct aspects of user-item relationships, which in turn produces complementary recommendations. This paper proposes a novel OCCF framework, named ConCF, that exploits the complementarity from heterogeneous objectives throughout the training process, generating a more generalizable model. ConCF constructs a multi-branch variant of a given target model by adding auxiliary heads, each of which is trained with heterogeneous objectives. Then, it generates consensus by consolidating the various views from the heads, and guides the heads based on the consensus. The heads are collaboratively evolved based on their complementarity throughout the training, which again results in generating more accurate consensus iteratively. After training, we convert the multi-branch architecture back to the original target model by removing the auxiliary heads, thus there is no extra inference cost for the deployment. Our extensive experiments on real-world datasets demonstrate that ConCF significantly improves the generalization of the model by exploiting the complementarity from heterogeneous objectives.
Topology Distillation for Recommender System
Jun 16, 2021


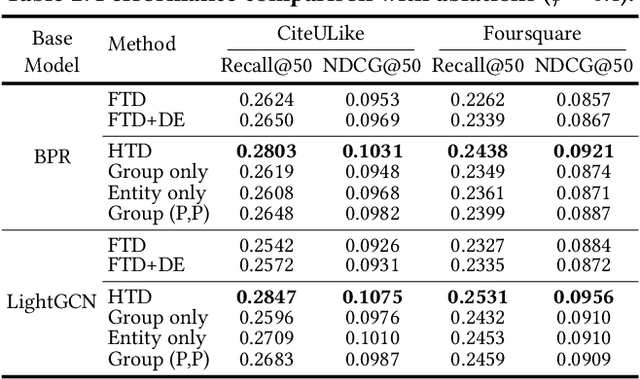
Recommender Systems (RS) have employed knowledge distillation which is a model compression technique training a compact student model with the knowledge transferred from a pre-trained large teacher model. Recent work has shown that transferring knowledge from the teacher's intermediate layer significantly improves the recommendation quality of the student. However, they transfer the knowledge of individual representation point-wise and thus have a limitation in that primary information of RS lies in the relations in the representation space. This paper proposes a new topology distillation approach that guides the student by transferring the topological structure built upon the relations in the teacher space. We first observe that simply making the student learn the whole topological structure is not always effective and even degrades the student's performance. We demonstrate that because the capacity of the student is highly limited compared to that of the teacher, learning the whole topological structure is daunting for the student. To address this issue, we propose a novel method named Hierarchical Topology Distillation (HTD) which distills the topology hierarchically to cope with the large capacity gap. Our extensive experiments on real-world datasets show that the proposed method significantly outperforms the state-of-the-art competitors. We also provide in-depth analyses to ascertain the benefit of distilling the topology for RS.
DE-RRD: A Knowledge Distillation Framework for Recommender System
Dec 08, 2020

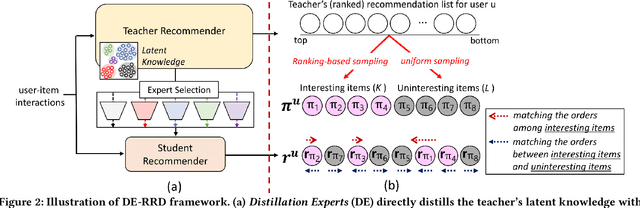

Recent recommender systems have started to employ knowledge distillation, which is a model compression technique distilling knowledge from a cumbersome model (teacher) to a compact model (student), to reduce inference latency while maintaining performance. The state-of-the-art methods have only focused on making the student model accurately imitate the predictions of the teacher model. They have a limitation in that the prediction results incompletely reveal the teacher's knowledge. In this paper, we propose a novel knowledge distillation framework for recommender system, called DE-RRD, which enables the student model to learn from the latent knowledge encoded in the teacher model as well as from the teacher's predictions. Concretely, DE-RRD consists of two methods: 1) Distillation Experts (DE) that directly transfers the latent knowledge from the teacher model. DE exploits "experts" and a novel expert selection strategy for effectively distilling the vast teacher's knowledge to the student with limited capacity. 2) Relaxed Ranking Distillation (RRD) that transfers the knowledge revealed from the teacher's prediction with consideration of the relaxed ranking orders among items. Our extensive experiments show that DE-RRD outperforms the state-of-the-art competitors and achieves comparable or even better performance to that of the teacher model with faster inference time.