 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCREAM: Continual Retrieval on Dynamic Streaming Corpora with Adaptive Soft Memory
Jan 06, 2026Information retrieval (IR) in dynamic data streams is emerging as a challenging task, as shifts in data distribution degrade the performance of AI-powered IR systems. To mitigate this issue, memory-based continual learning has been widely adopted for IR. However, existing methods rely on a fixed set of queries with ground-truth relevant documents, which limits generalization to unseen queries and documents, making them impractical for real-world applications. To enable more effective learning with unseen topics of a new corpus without ground-truth labels, we propose CREAM, a self-supervised framework for memory-based continual retrieval. CREAM captures the evolving semantics of streaming queries and documents into dynamically structured soft memory and leverages it to adapt to both seen and unseen topics in an unsupervised setting. We realize this through three key techniques: fine-grained similarity estimation, regularized cluster prototyping, and stratified coreset sampling. Experiments on two benchmark datasets demonstrate that CREAM exhibits superior adaptability and retrieval accuracy, outperforming the strongest method in a label-free setting by 27.79\% in Success@5 and 44.5\% in Recall@10 on average, and achieving performance comparable to or even exceeding that of supervised methods.
Topic Coverage-based Demonstration Retrieval for In-Context Learning
Sep 15, 2025The effectiveness of in-context learning relies heavily on selecting demonstrations that provide all the necessary information for a given test input. To achieve this, it is crucial to identify and cover fine-grained knowledge requirements. However, prior methods often retrieve demonstrations based solely on embedding similarity or generation probability, resulting in irrelevant or redundant examples. In this paper, we propose TopicK, a topic coverage-based retrieval framework that selects demonstrations to comprehensively cover topic-level knowledge relevant to both the test input and the model. Specifically, TopicK estimates the topics required by the input and assesses the model's knowledge on those topics. TopicK then iteratively selects demonstrations that introduce previously uncovered required topics, in which the model exhibits low topical knowledge. We validate the effectiveness of TopicK through extensive experiments across various datasets and both open- and closed-source LLMs. Our source code is available at https://github.com/WonbinKweon/TopicK_EMNLP2025.
Delving into Instance-Dependent Label Noise in Graph Data: A Comprehensive Study and Benchmark
Jun 14, 2025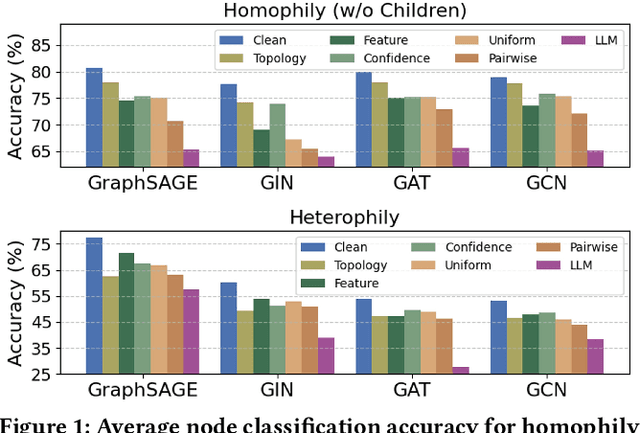
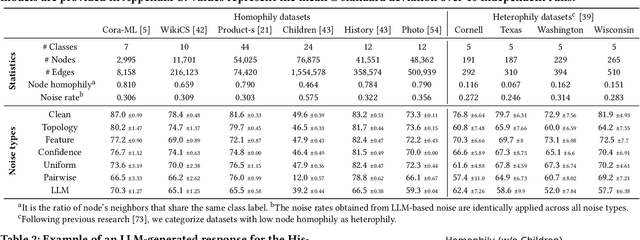
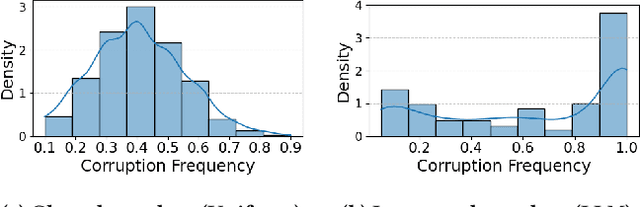
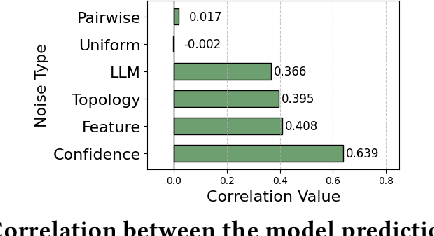
Graph Neural Networks (GNNs) have achieved state-of-the-art performance in node classification tasks but struggle with label noise in real-world data. Existing studies on graph learning with label noise commonly rely on class-dependent label noise, overlooking the complexities of instance-dependent noise and falling short of capturing real-world corruption patterns. We introduce BeGIN (Benchmarking for Graphs with Instance-dependent Noise), a new benchmark that provides realistic graph datasets with various noise types and comprehensively evaluates noise-handling strategies across GNN architectures, noisy label detection, and noise-robust learning. To simulate instance-dependent corruptions, BeGIN introduces algorithmic methods and LLM-based simulations. Our experiments reveal the challenges of instance-dependent noise, particularly LLM-based corruption, and underscore the importance of node-specific parameterization to enhance GNN robustness. By comprehensively evaluating noise-handling strategies, BeGIN provides insights into their effectiveness, efficiency, and key performance factors. We expect that BeGIN will serve as a valuable resource for advancing research on label noise in graphs and fostering the development of robust GNN training methods. The code is available at https://github.com/kimsu55/BeGIN.
* 17 pages
Leveraging Historical and Current Interests for Continual Sequential Recommendation
Jun 09, 2025Sequential recommendation models based on the Transformer architecture show superior performance in harnessing long-range dependencies within user behavior via self-attention. However, naively updating them on continuously arriving non-stationary data streams incurs prohibitive computation costs or leads to catastrophic forgetting. To address this, we propose Continual Sequential Transformer for Recommendation (CSTRec) that effectively leverages well-preserved historical user interests while capturing current interests. At its core is Continual Sequential Attention (CSA), a linear attention mechanism that retains past knowledge without direct access to old data. CSA integrates two key components: (1) Cauchy-Schwarz Normalization that stabilizes training under uneven interaction frequencies, and (2) Collaborative Interest Enrichment that mitigates forgetting through shared, learnable interest pools. We further introduce a technique that facilitates learning for cold-start users by transferring historical knowledge from behaviorally similar existing users. Extensive experiments on three real-world datasets indicate that CSTRec outperforms state-of-the-art baselines in both knowledge retention and acquisition.
Scientific Paper Retrieval with LLM-Guided Semantic-Based Ranking
May 27, 2025Scientific paper retrieval is essential for supporting literature discovery and research. While dense retrieval methods demonstrate effectiveness in general-purpose tasks, they often fail to capture fine-grained scientific concepts that are essential for accurate understanding of scientific queries. Recent studies also use large language models (LLMs) for query understanding; however, these methods often lack grounding in corpus-specific knowledge and may generate unreliable or unfaithful content. To overcome these limitations, we propose SemRank, an effective and efficient paper retrieval framework that combines LLM-guided query understanding with a concept-based semantic index. Each paper is indexed using multi-granular scientific concepts, including general research topics and detailed key phrases. At query time, an LLM identifies core concepts derived from the corpus to explicitly capture the query's information need. These identified concepts enable precise semantic matching, significantly enhancing retrieval accuracy. Experiments show that SemRank consistently improves the performance of various base retrievers, surpasses strong existing LLM-based baselines, and remains highly efficient.
LLM-Based Compact Reranking with Document Features for Scientific Retrieval
May 19, 2025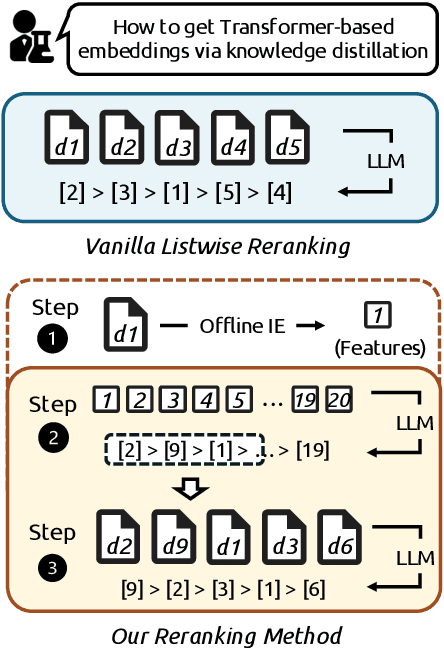
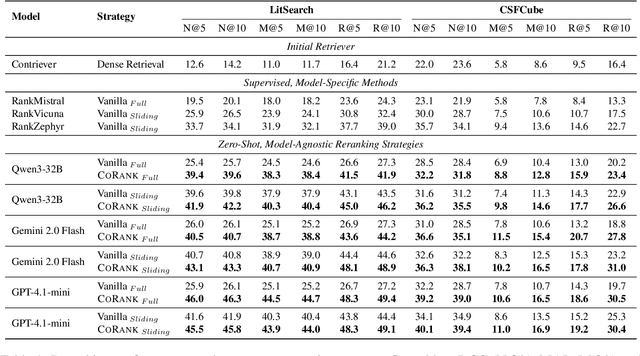

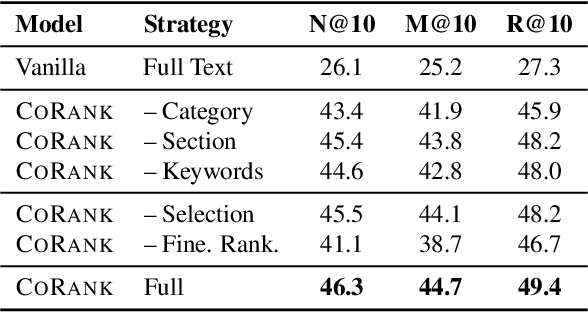
Scientific retrieval is essential for advancing academic discovery. Within this process, document reranking plays a critical role by refining first-stage retrieval results. However, large language model (LLM) listwise reranking faces unique challenges in the scientific domain. First-stage retrieval is often suboptimal in the scientific domain, so relevant documents are ranked lower. Moreover, conventional listwise reranking uses the full text of candidate documents in the context window, limiting the number of candidates that can be considered. As a result, many relevant documents are excluded before reranking, which constrains overall retrieval performance. To address these challenges, we explore compact document representations based on semantic features such as categories, sections, and keywords, and propose a training-free, model-agnostic reranking framework for scientific retrieval called CoRank. The framework involves three stages: (i) offline extraction of document-level features, (ii) coarse reranking using these compact representations, and (iii) fine-grained reranking on full texts of the top candidates from stage (ii). This hybrid design provides a high-level abstraction of document semantics, expands candidate coverage, and retains critical details required for precise ranking. Experiments on LitSearch and CSFCube show that CoRank significantly improves reranking performance across different LLM backbones, increasing nDCG@10 from 32.0 to 39.7. Overall, these results highlight the value of information extraction for reranking in scientific retrieval.
Imagine All The Relevance: Scenario-Profiled Indexing with Knowledge Expansion for Dense Retrieval
Mar 29, 2025Existing dense retrieval models struggle with reasoning-intensive retrieval task as they fail to capture implicit relevance that requires reasoning beyond surface-level semantic information. To address these challenges, we propose Scenario-Profiled Indexing with Knowledge Expansion (SPIKE), a dense retrieval framework that explicitly indexes implicit relevance by decomposing documents into scenario-based retrieval units. SPIKE organizes documents into scenario, which encapsulates the reasoning process necessary to uncover implicit relationships between hypothetical information needs and document content. SPIKE constructs a scenario-augmented dataset using a powerful teacher large language model (LLM), then distills these reasoning capabilities into a smaller, efficient scenario generator. During inference, SPIKE incorporates scenario-level relevance alongside document-level relevance, enabling reasoning-aware retrieval. Extensive experiments demonstrate that SPIKE consistently enhances retrieval performance across various query types and dense retrievers. It also enhances the retrieval experience for users through scenario and offers valuable contextual information for LLMs in retrieval-augmented generation (RAG).
Uncertainty Quantification and Decomposition for LLM-based Recommendation
Jan 29, 2025Despite the widespread adoption of large language models (LLMs) for recommendation, we demonstrate that LLMs often exhibit uncertainty in their recommendations. To ensure the trustworthy use of LLMs in generating recommendations, we emphasize the importance of assessing the reliability of recommendations generated by LLMs. We start by introducing a novel framework for estimating the predictive uncertainty to quantitatively measure the reliability of LLM-based recommendations. We further propose to decompose the predictive uncertainty into recommendation uncertainty and prompt uncertainty, enabling in-depth analyses of the primary source of uncertainty. Through extensive experiments, we (1) demonstrate predictive uncertainty effectively indicates the reliability of LLM-based recommendations, (2) investigate the origins of uncertainty with decomposed uncertainty measures, and (3) propose uncertainty-aware prompting for a lower predictive uncertainty and enhanced recommendation. Our source code and model weights are available at https://github.com/WonbinKweon/UNC_LLM_REC_WWW2025
Why These Documents? Explainable Generative Retrieval with Hierarchical Category Paths
Nov 08, 2024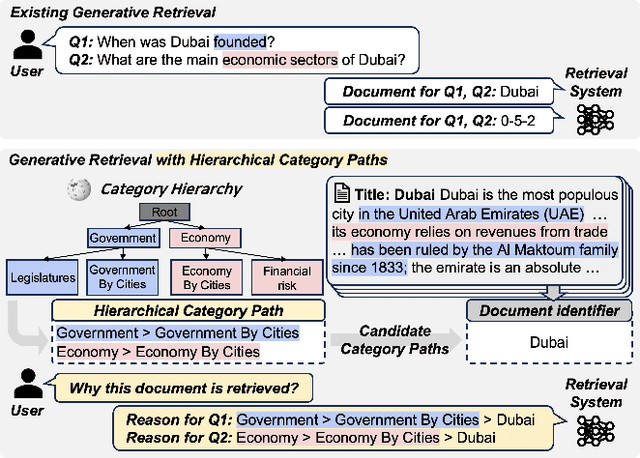
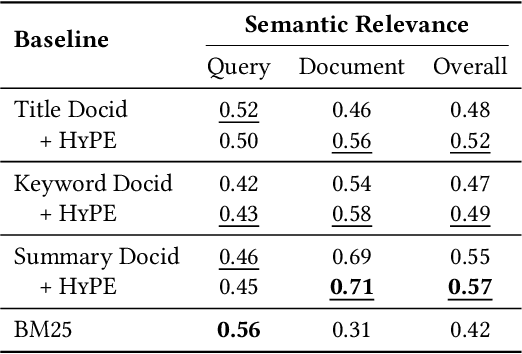
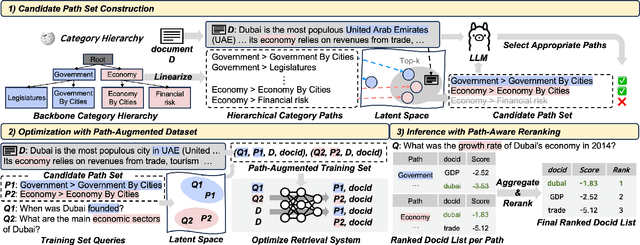
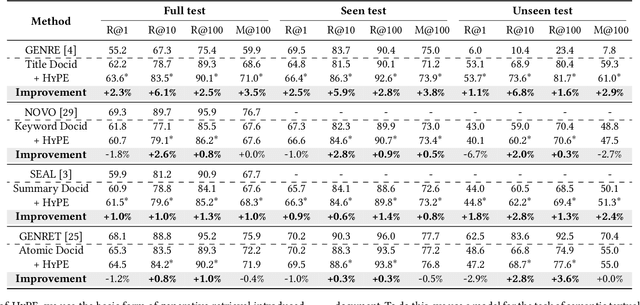
Generative retrieval has recently emerged as a new alternative of traditional information retrieval approaches. However, existing generative retrieval methods directly decode docid when a query is given, making it impossible to provide users with explanations as an answer for "Why this document is retrieved?". To address this limitation, we propose Hierarchical Category Path-Enhanced Generative Retrieval(HyPE), which enhances explainability by generating hierarchical category paths step-by-step before decoding docid. HyPE leverages hierarchical category paths as explanation, progressing from broad to specific semantic categories. This approach enables diverse explanations for the same document depending on the query by using shared category paths between the query and the document, and provides reasonable explanation by reflecting the document's semantic structure through a coarse-to-fine manner. HyPE constructs category paths with external high-quality semantic hierarchy, leverages LLM to select appropriate candidate paths for each document, and optimizes the generative retrieval model with path-augmented dataset. During inference, HyPE utilizes path-aware reranking strategy to aggregate diverse topic information, allowing the most relevant documents to be prioritized in the final ranked list of docids. Our extensive experiments demonstrate that HyPE not only offers a high level of explainability but also improves the retrieval performance in the document retrieval task.
Taxonomy-guided Semantic Indexing for Academic Paper Search
Oct 25, 2024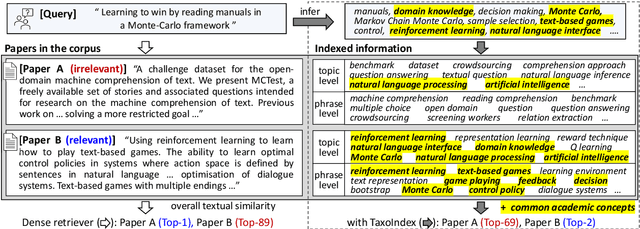
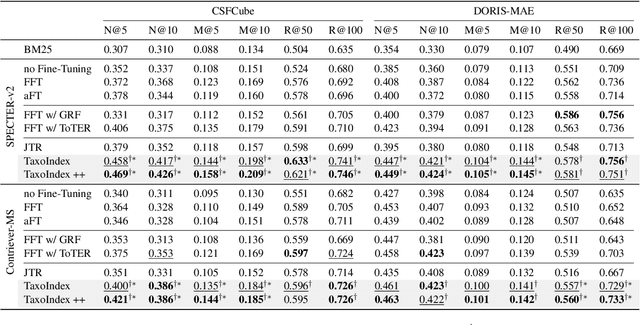
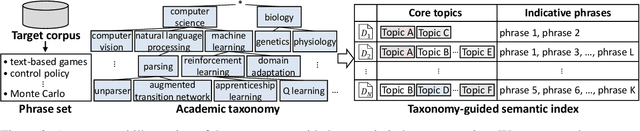
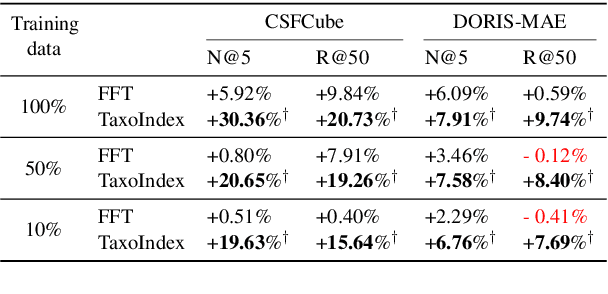
Academic paper search is an essential task for efficient literature discovery and scientific advancement. While dense retrieval has advanced various ad-hoc searches, it often struggles to match the underlying academic concepts between queries and documents, which is critical for paper search. To enable effective academic concept matching for paper search, we propose Taxonomy-guided Semantic Indexing (TaxoIndex) framework. TaxoIndex extracts key concepts from papers and organizes them as a semantic index guided by an academic taxonomy, and then leverages this index as foundational knowledge to identify academic concepts and link queries and documents. As a plug-and-play framework, TaxoIndex can be flexibly employed to enhance existing dense retrievers. Extensive experiments show that TaxoIndex brings significant improvements, even with highly limited training data, and greatly enhances interpretability.