 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into Instance-Dependent Label Noise in Graph Data: A Comprehensive Study and Benchmark
Jun 14, 2025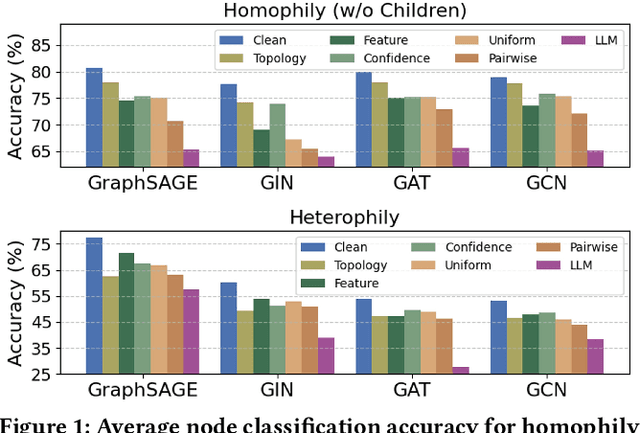
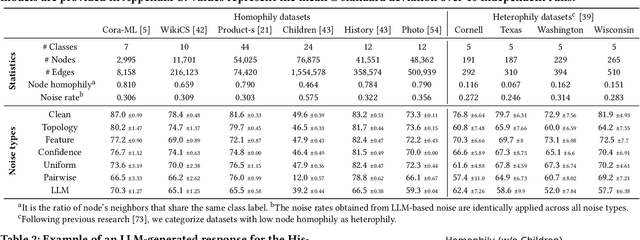
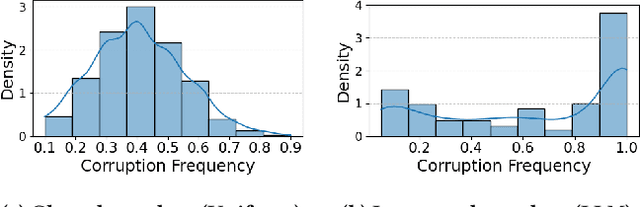
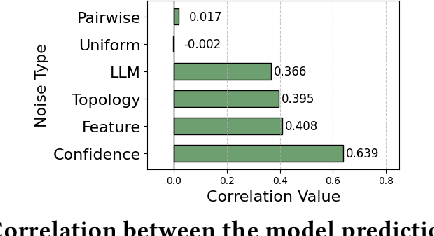
Graph Neural Networks (GNNs) have achieved state-of-the-art performance in node classification tasks but struggle with label noise in real-world data. Existing studies on graph learning with label noise commonly rely on class-dependent label noise, overlooking the complexities of instance-dependent noise and falling short of capturing real-world corruption patterns. We introduce BeGIN (Benchmarking for Graphs with Instance-dependent Noise), a new benchmark that provides realistic graph datasets with various noise types and comprehensively evaluates noise-handling strategies across GNN architectures, noisy label detection, and noise-robust learning. To simulate instance-dependent corruptions, BeGIN introduces algorithmic methods and LLM-based simulations. Our experiments reveal the challenges of instance-dependent noise, particularly LLM-based corruption, and underscore the importance of node-specific parameterization to enhance GNN robustness. By comprehensively evaluating noise-handling strategies, BeGIN provides insights into their effectiveness, efficiency, and key performance factors. We expect that BeGIN will serve as a valuable resource for advancing research on label noise in graphs and fostering the development of robust GNN training methods. The code is available at https://github.com/kimsu55/BeGIN.
* 17 pages
Eliciting Instruction-tuned Code Language Models' Capabilities to Utilize Auxiliary Function for Code Generation
Sep 20, 2024
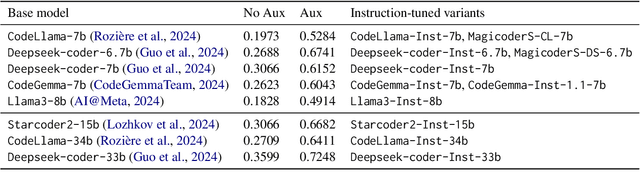
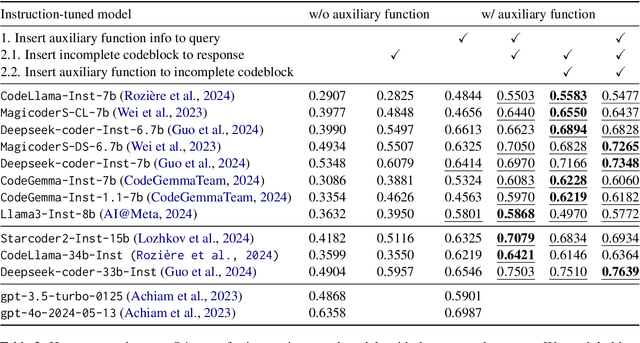
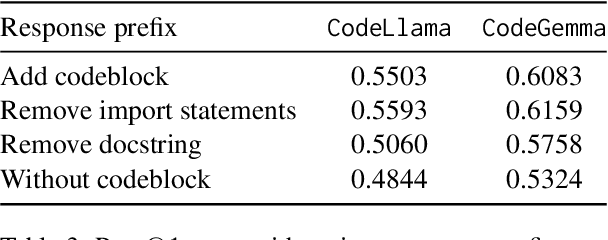
We study the code generation behavior of instruction-tuned models built on top of code pre-trained language models when they could access an auxiliary function to implement a function. We design several ways to provide auxiliary functions to the models by adding them to the query or providing a response prefix to incorporate the ability to utilize auxiliary functions with the instruction-following capability. Our experimental results show the effectiveness of combining the base models' auxiliary function utilization ability with the instruction following ability. In particular, the performance of adopting our approaches with the open-sourced language models surpasses that of the recent powerful proprietary language models, i.e., gpt-4o.
Learning Discriminative Dynamics with Label Corruption for Noisy Label Detection
May 30, 2024Label noise, commonly found in real-world datasets, has a detrimental impact on a model's generalization. To effectively detect incorrectly labeled instances, previous works have mostly relied on distinguishable training signals, such as training loss, as indicators to differentiate between clean and noisy labels. However, they have limitations in that the training signals incompletely reveal the model's behavior and are not effectively generalized to various noise types, resulting in limited detection accuracy. In this paper, we propose DynaCor framework that distinguishes incorrectly labeled instances from correctly labeled ones based on the dynamics of the training signals. To cope with the absence of supervision for clean and noisy labels, DynaCor first introduces a label corruption strategy that augments the original dataset with intentionally corrupted labels, enabling indirect simulation of the model's behavior on noisy labels. Then, DynaCor learns to identify clean and noisy instances by inducing two clearly distinguishable clusters from the latent representations of training dynamics. Our comprehensive experiments show that DynaCor outperforms the state-of-the-art competitors and shows strong robustness to various noise types and noise rates.
Enhancing Clinical Efficiency through LLM: Discharge Note Generation for Cardiac Patients
Apr 08, 2024Medical documentation, including discharge notes, is crucial for ensuring patient care quality, continuity, and effective medical communication. However, the manual creation of these documents is not only time-consuming but also prone to inconsistencies and potential errors. The automation of this documentation process using artificial intelligence (AI) represents a promising area of innovation in healthcare. This study directly addresses the inefficiencies and inaccuracies in creating discharge notes manually, particularly for cardiac patients, by employing AI techniques, specifically large language model (LLM). Utilizing a substantial dataset from a cardiology center, encompassing wide-ranging medical records and physician assessments, our research evaluates the capability of LLM to enhance the documentation process. Among the various models assessed, Mistral-7B distinguished itself by accurately generating discharge notes that significantly improve both documentation efficiency and the continuity of care for patients. These notes underwent rigorous qualitative evaluation by medical expert, receiving high marks for their clinical relevance, completeness, readability, and contribution to informed decision-making and care planning. Coupled with quantitative analyses, these results confirm Mistral-7B's efficacy in distilling complex medical information into concise, coherent summaries. Overall, our findings illuminate the considerable promise of specialized LLM, such as Mistral-7B, in refining healthcare documentation workflows and advancing patient care. This study lays the groundwork for further integrating advanced AI technologies in healthcare, demonstrating their potential to revolutionize patient documentation and support better care outcomes.
MitoVis: A Visually-guided Interactive Intelligent System for Neuronal Mitochondria Analysis
Sep 03, 2021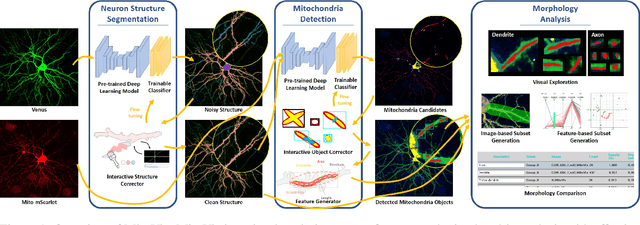
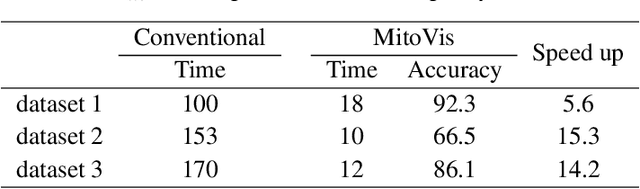


Neurons have a polarized structure, including dendrites and axons, and compartment-specific functions can be affected by dwelling mitochondria. It is known that the morphology of mitochondria is closely related to the functions of neurons and neurodegenerative diseases. Even though several deep learning methods have been developed to automatically analyze the morphology of mitochondria, the application of existing methods to actual analysis still encounters several difficulties. Since the performance of pre-trained deep learning model may vary depending on the target data, re-training of the model is often required. Besides, even though deep learning has shown superior performance under a constrained setup, there are always errors that need to be corrected by humans in real analysis. To address these issues, we introduce MitoVis, a novel visualization system for end-to-end data processing and interactive analysis of the morphology of neuronal mitochondria. MitoVis enables interactive fine-tuning of a pre-trained neural network model without the domain knowledge of machine learning, which allows neuroscientists to easily leverage deep learning in their research. MitoVis also provides novel visual guides and interactive proofreading functions so that the users can quickly identify and correct errors in the result with minimal effort. We demonstrate the usefulness and efficacy of the system via a case study conducted by a neuroscientist on a real analysis scenario. The result shows that MitoVis allows up to 15x faster analysis with similar accuracy compared to the fully manual analysis method.