 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMPASS: A Framework for Evaluating Organization-Specific Policy Alignment in LLMs
Jan 05, 2026As large language models are deployed in high-stakes enterprise applications, from healthcare to finance, ensuring adherence to organization-specific policies has become essential. Yet existing safety evaluations focus exclusively on universal harms. We present COMPASS (Company/Organization Policy Alignment Assessment), the first systematic framework for evaluating whether LLMs comply with organizational allowlist and denylist policies. We apply COMPASS to eight diverse industry scenarios, generating and validating 5,920 queries that test both routine compliance and adversarial robustness through strategically designed edge cases. Evaluating seven state-of-the-art models, we uncover a fundamental asymmetry: models reliably handle legitimate requests (>95% accuracy) but catastrophically fail at enforcing prohibitions, refusing only 13-40% of adversarial denylist violations. These results demonstrate that current LLMs lack the robustness required for policy-critical deployments, establishing COMPASS as an essential evaluation framework for organizational AI safety.
EXAONE 4.0: Unified Large Language Models Integrating Non-reasoning and Reasoning Modes
Jul 15, 2025This technical report introduces EXAONE 4.0, which integrates a Non-reasoning mode and a Reasoning mode to achieve both the excellent usability of EXAONE 3.5 and the advanced reasoning abilities of EXAONE Deep. To pave the way for the agentic AI era, EXAONE 4.0 incorporates essential features such as agentic tool use, and its multilingual capabilities are extended to support Spanish in addition to English and Korean. The EXAONE 4.0 model series consists of two sizes: a mid-size 32B model optimized for high performance, and a small-size 1.2B model designed for on-device applications. The EXAONE 4.0 demonstrates superior performance compared to open-weight models in its class and remains competitive even against frontier-class models. The models are publicly available for research purposes and can be easily downloaded via https://huggingface.co/LGAI-EXAONE.
Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study
May 21, 2025Rapid deployment of vision-language models (VLMs) magnifies safety risks, yet most evaluations rely on artificial images. This study asks: How safe are current VLMs when confronted with meme images that ordinary users share? To investigate this question, we introduce MemeSafetyBench, a 50,430-instance benchmark pairing real meme images with both harmful and benign instructions. Using a comprehensive safety taxonomy and LLM-based instruction generation, we assess multiple VLMs across single and multi-turn interactions. We investigate how real-world memes influence harmful outputs, the mitigating effects of conversational context, and the relationship between model scale and safety metrics. Our findings demonstrate that VLMs show greater vulnerability to meme-based harmful prompts than to synthetic or typographic images. Memes significantly increase harmful responses and decrease refusals compared to text-only inputs. Though multi-turn interactions provide partial mitigation, elevated vulnerability persists. These results highlight the need for ecologically valid evaluations and stronger safety mechanisms.
Verbosity-Aware Rationale Reduction: Effective Reduction of Redundant Rationale via Principled Criteria
Dec 30, 2024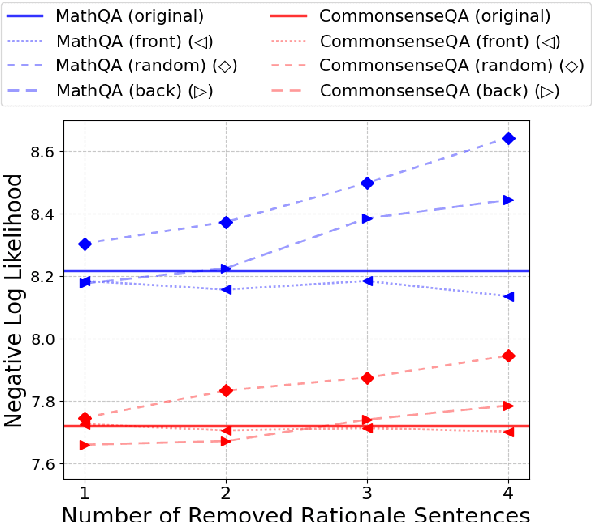
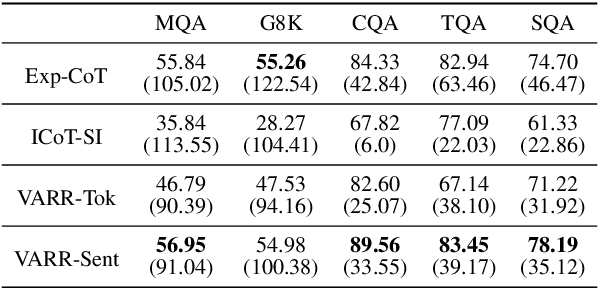
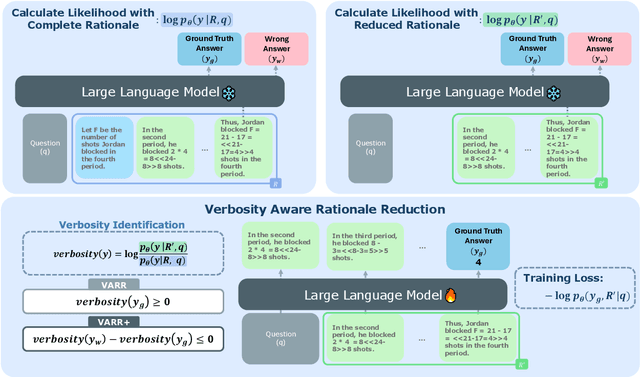
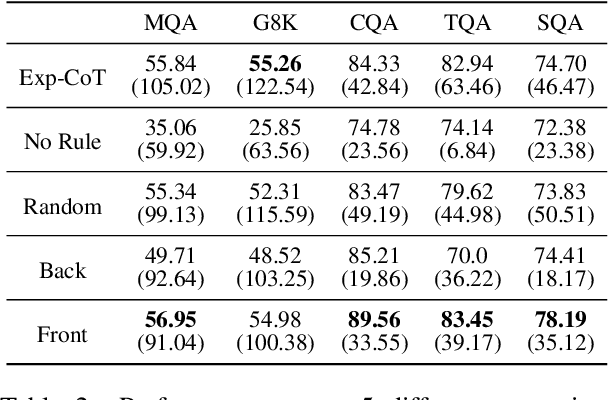
Large Language Models (LLMs) rely on generating extensive intermediate reasoning units (e.g., tokens, sentences) to enhance final answer quality across a wide range of complex tasks. While generating multiple reasoning paths or iteratively refining rationales proves effective for improving performance, these approaches inevitably result in significantly higher inference costs. In this work, we propose a novel sentence-level rationale reduction training framework that leverages likelihood-based criteria, verbosity, to identify and remove redundant reasoning sentences. Unlike previous approaches that utilize token-level reduction, our sentence-level reduction framework maintains model performance while reducing generation length. This preserves the original reasoning abilities of LLMs and achieves an average 17.15% reduction in generation costs across various models and tasks.
Eliciting Instruction-tuned Code Language Models' Capabilities to Utilize Auxiliary Function for Code Generation
Sep 20, 2024
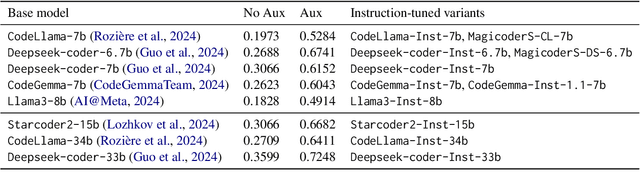
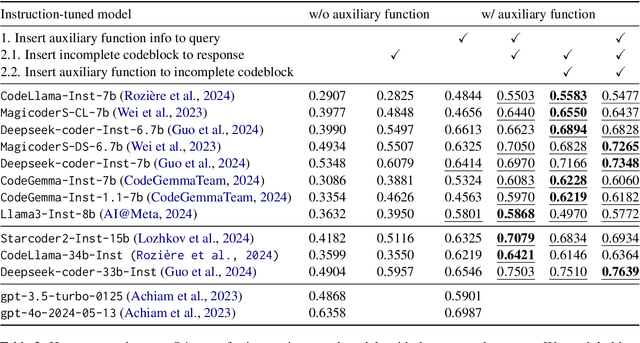
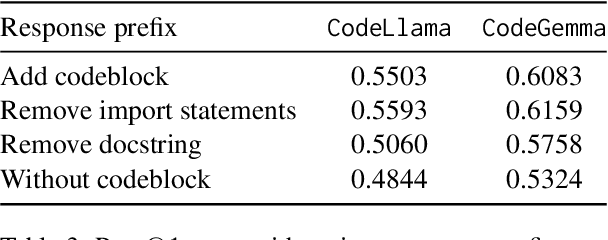
We study the code generation behavior of instruction-tuned models built on top of code pre-trained language models when they could access an auxiliary function to implement a function. We design several ways to provide auxiliary functions to the models by adding them to the query or providing a response prefix to incorporate the ability to utilize auxiliary functions with the instruction-following capability. Our experimental results show the effectiveness of combining the base models' auxiliary function utilization ability with the instruction following ability. In particular, the performance of adopting our approaches with the open-sourced language models surpasses that of the recent powerful proprietary language models, i.e., gpt-4o.
Rectifying Demonstration Shortcut in In-Context Learning
Mar 29, 2024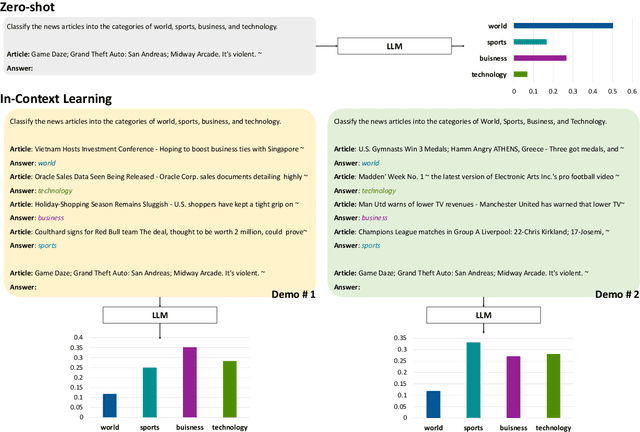



Large language models (LLMs) are able to solve various tasks with only a few demonstrations utilizing their in-context learning (ICL) abilities. However, LLMs often rely on their pre-trained semantic priors of demonstrations rather than on the input-label relationships to proceed with ICL prediction. In this work, we term this phenomenon as the 'Demonstration Shortcut'. While previous works have primarily focused on improving ICL prediction results for predefined tasks, we aim to rectify the Demonstration Shortcut, thereby enabling the LLM to effectively learn new input-label relationships from demonstrations. To achieve this, we introduce In-Context Calibration, a demonstration-aware calibration method. We evaluate the effectiveness of the proposed method in two settings: (1) the Original ICL Task using the standard label space and (2) the Task Learning setting, where the label space is replaced with semantically unrelated tokens. In both settings, In-Context Calibration demonstrates substantial improvements, with results generalized across three LLM families (OPT, GPT, and Llama2) under various configurations.