 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Path Attribution: Efficient Attribution for SwiGLU-Transformers through Layer-Wise Target Propagation
Mar 20, 2026Understanding the internal mechanisms of transformer-based large language models (LLMs) is crucial for their reliable deployment and effective operation. While recent efforts have yielded a plethora of attribution methods attempting to balance faithfulness and computational efficiency, dense component attribution remains prohibitively expensive. In this work, we introduce Dual Path Attribution (DPA), a novel framework that faithfully traces information flow on the frozen transformer in one forward and one backward pass without requiring counterfactual examples. DPA analytically decomposes and linearizes the computational structure of the SwiGLU Transformers into distinct pathways along which it propagates a targeted unembedding vector to receive the effective representation at each residual position. This target-centric propagation achieves O(1) time complexity with respect to the number of model components, scaling to long input sequences and dense component attribution. Extensive experiments on standard interpretability benchmarks demonstrate that DPA achieves state-of-the-art faithfulness and unprecedented efficiency compared to existing baselines.
From What to Respond to When to Respond: Timely Response Generation for Open-domain Dialogue Agents
Jun 17, 2025While research on dialogue response generation has primarily focused on generating coherent responses conditioning on textual context, the critical question of when to respond grounded on the temporal context remains underexplored. To bridge this gap, we propose a novel task called timely dialogue response generation and introduce the TimelyChat benchmark, which evaluates the capabilities of language models to predict appropriate time intervals and generate time-conditioned responses. Additionally, we construct a large-scale training dataset by leveraging unlabeled event knowledge from a temporal commonsense knowledge graph and employing a large language model (LLM) to synthesize 55K event-driven dialogues. We then train Timer, a dialogue agent designed to proactively predict time intervals and generate timely responses that align with those intervals. Experimental results show that Timer outperforms prompting-based LLMs and other fine-tuned baselines in both turn-level and dialogue-level evaluations. We publicly release our data, model, and code.
On the Effectiveness of Integration Methods for Multimodal Dialogue Response Retrieval
Jun 13, 2025Multimodal chatbots have become one of the major topics for dialogue systems in both research community and industry. Recently, researchers have shed light on the multimodality of responses as well as dialogue contexts. This work explores how a dialogue system can output responses in various modalities such as text and image. To this end, we first formulate a multimodal dialogue response retrieval task for retrieval-based systems as the combination of three subtasks. We then propose three integration methods based on a two-step approach and an end-to-end approach, and compare the merits and demerits of each method. Experimental results on two datasets demonstrate that the end-to-end approach achieves comparable performance without an intermediate step in the two-step approach. In addition, a parameter sharing strategy not only reduces the number of parameters but also boosts performance by transferring knowledge across the subtasks and the modalities.
Eliciting Instruction-tuned Code Language Models' Capabilities to Utilize Auxiliary Function for Code Generation
Sep 20, 2024
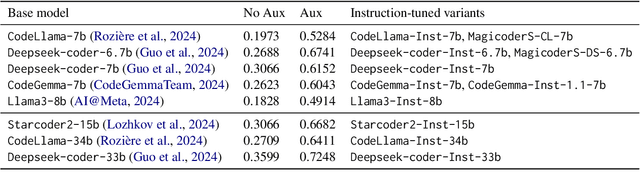
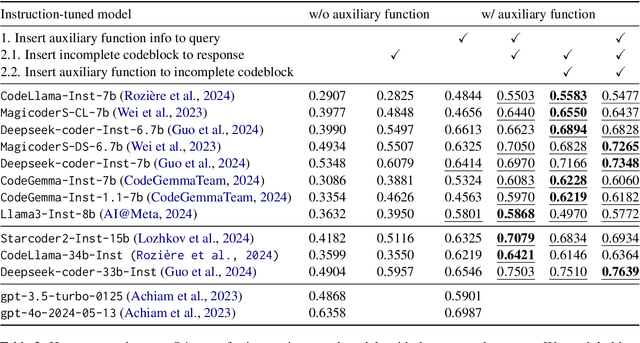
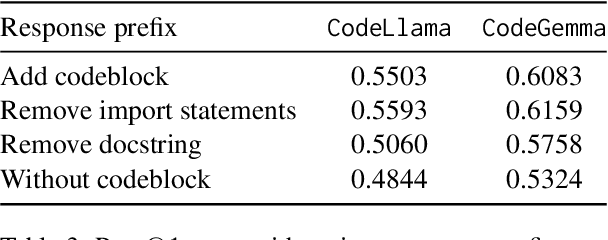
We study the code generation behavior of instruction-tuned models built on top of code pre-trained language models when they could access an auxiliary function to implement a function. We design several ways to provide auxiliary functions to the models by adding them to the query or providing a response prefix to incorporate the ability to utilize auxiliary functions with the instruction-following capability. Our experimental results show the effectiveness of combining the base models' auxiliary function utilization ability with the instruction following ability. In particular, the performance of adopting our approaches with the open-sourced language models surpasses that of the recent powerful proprietary language models, i.e., gpt-4o.
Is Functional Correctness Enough to Evaluate Code Language Models? Exploring Diversity of Generated Codes
Aug 24, 2024Language models (LMs) have exhibited impressive abilities in generating codes from natural language requirements. In this work, we highlight the diversity of code generated by LMs as a critical criterion for evaluating their code generation capabilities, in addition to functional correctness. Despite its practical implications, there is a lack of studies focused on assessing the diversity of generated code, which overlooks its importance in the development of code LMs. We propose a systematic approach to evaluate the diversity of generated code, utilizing various metrics for inter-code similarity as well as functional correctness. Specifically, we introduce a pairwise code similarity measure that leverages large LMs' capabilities in code understanding and reasoning, demonstrating the highest correlation with human judgment. We extensively investigate the impact of various factors on the quality of generated code, including model sizes, temperatures, training approaches, prompting strategies, and the difficulty of input problems. Our consistent observation of a positive correlation between the test pass score and the inter-code similarity score indicates that current LMs tend to produce functionally correct code with limited diversity.
Exploring Language Model's Code Generation Ability with Auxiliary Functions
Mar 15, 2024



Auxiliary function is a helpful component to improve language model's code generation ability. However, a systematic exploration of how they affect has yet to be done. In this work, we comprehensively evaluate the ability to utilize auxiliary functions encoded in recent code-pretrained language models. First, we construct a human-crafted evaluation set, called HumanExtension, which contains examples of two functions where one function assists the other. With HumanExtension, we design several experiments to examine their ability in a multifaceted way. Our evaluation processes enable a comprehensive understanding of including auxiliary functions in the prompt in terms of effectiveness and robustness. An additional implementation style analysis captures the models' various implementation patterns when they access the auxiliary function. Through this analysis, we discover the models' promising ability to utilize auxiliary functions including their self-improving behavior by implementing the two functions step-by-step. However, our analysis also reveals the model's underutilized behavior to call the auxiliary function, suggesting the future direction to enhance their implementation by eliciting the auxiliary function call ability encoded in the models. We release our code and dataset to facilitate this research direction.
KoDialogBench: Evaluating Conversational Understanding of Language Models with Korean Dialogue Benchmark
Feb 27, 2024As language models are often deployed as chatbot assistants, it becomes a virtue for models to engage in conversations in a user's first language. While these models are trained on a wide range of languages, a comprehensive evaluation of their proficiency in low-resource languages such as Korean has been lacking. In this work, we introduce KoDialogBench, a benchmark designed to assess language models' conversational capabilities in Korean. To this end, we collect native Korean dialogues on daily topics from public sources, or translate dialogues from other languages. We then structure these conversations into diverse test datasets, spanning from dialogue comprehension to response selection tasks. Leveraging the proposed benchmark, we conduct extensive evaluations and analyses of various language models to measure a foundational understanding of Korean dialogues. Experimental results indicate that there exists significant room for improvement in models' conversation skills. Furthermore, our in-depth comparisons across different language models highlight the effectiveness of recent training techniques in enhancing conversational proficiency. We anticipate that KoDialogBench will promote the progress towards conversation-aware Korean language models.
Learning Topology-Specific Experts for Molecular Property Prediction
Mar 12, 2023Recently, graph neural networks (GNNs) have been successfully applied to predicting molecular properties, which is one of the most classical cheminformatics tasks with various applications. Despite their effectiveness, we empirically observe that training a single GNN model for diverse molecules with distinct structural patterns limits its prediction performance. In this paper, motivated by this observation, we propose TopExpert to leverage topology-specific prediction models (referred to as experts), each of which is responsible for each molecular group sharing similar topological semantics. That is, each expert learns topology-specific discriminative features while being trained with its corresponding topological group. To tackle the key challenge of grouping molecules by their topological patterns, we introduce a clustering-based gating module that assigns an input molecule into one of the clusters and further optimizes the gating module with two different types of self-supervision: topological semantics induced by GNNs and molecular scaffolds, respectively. Extensive experiments demonstrate that TopExpert has boosted the performance for molecular property prediction and also achieved better generalization for new molecules with unseen scaffolds than baselines. The code is available at https://github.com/kimsu55/ToxExpert.
* 11 pages with 8 figures
Toward Interpretable Semantic Textual Similarity via Optimal Transport-based Contrastive Sentence Learning
Feb 26, 2022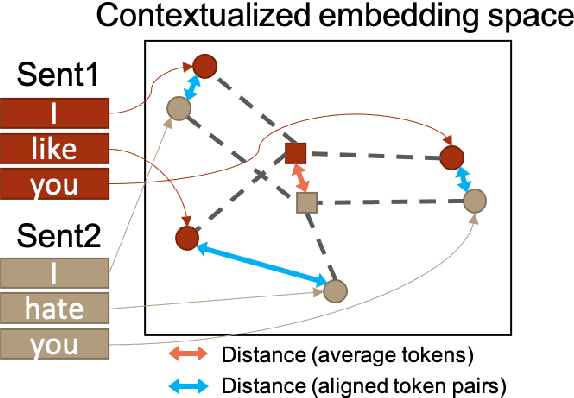
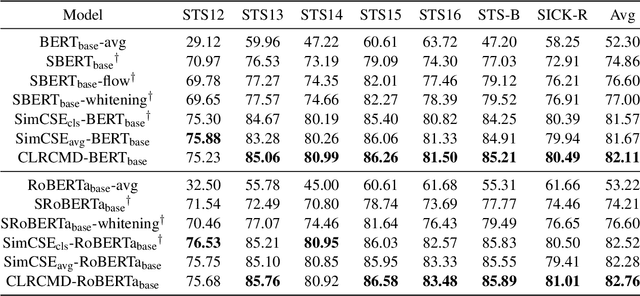

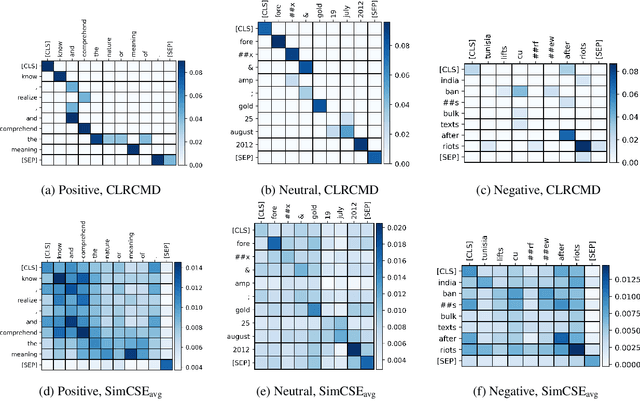
Recently, finetuning a pretrained language model to capture the similarity between sentence embeddings has shown the state-of-the-art performance on the semantic textual similarity (STS) task. However, the absence of an interpretation method for the sentence similarity makes it difficult to explain the model output. In this work, we explicitly describe the sentence distance as the weighted sum of contextualized token distances on the basis of a transportation problem, and then present the optimal transport-based distance measure, named RCMD; it identifies and leverages semantically-aligned token pairs. In the end, we propose CLRCMD, a contrastive learning framework that optimizes RCMD of sentence pairs, which enhances the quality of sentence similarity and their interpretation. Extensive experiments demonstrate that our learning framework outperforms other baselines on both STS and interpretable-STS benchmarks, indicating that it computes effective sentence similarity and also provides interpretation consistent with human judgement.
Learnable Structural Semantic Readout for Graph Classification
Nov 22, 2021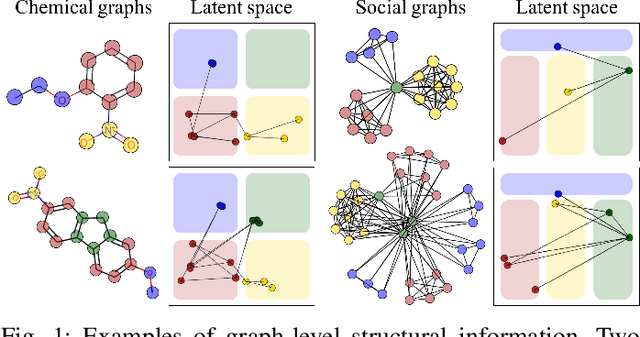
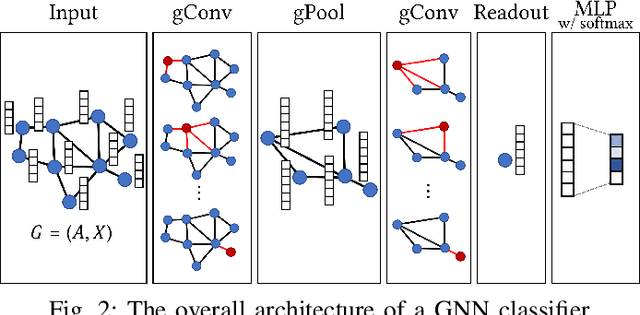
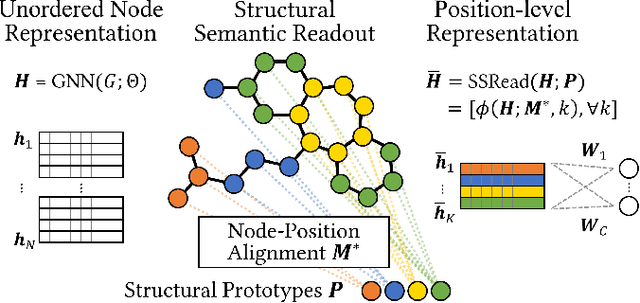
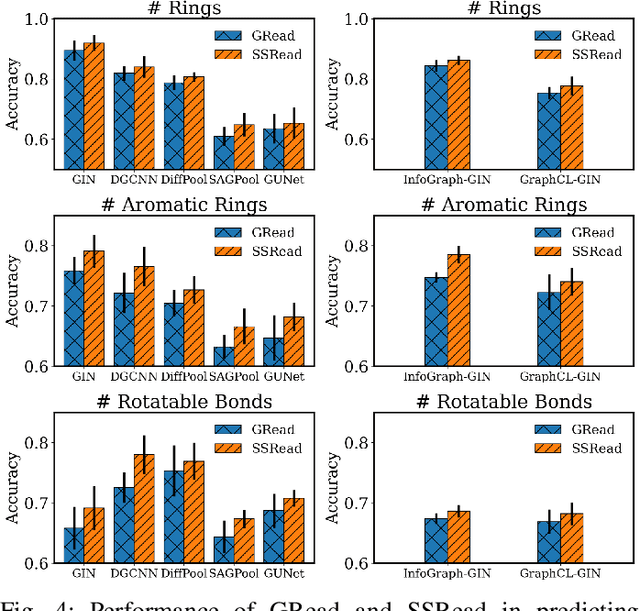
With the great success of deep learning in various domains, graph neural networks (GNNs) also become a dominant approach to graph classification. By the help of a global readout operation that simply aggregates all node (or node-cluster) representations, existing GNN classifiers obtain a graph-level representation of an input graph and predict its class label using the representation. However, such global aggregation does not consider the structural information of each node, which results in information loss on the global structure. Particularly, it limits the discrimination power by enforcing the same weight parameters of the classifier for all the node representations; in practice, each of them contributes to target classes differently depending on its structural semantic. In this work, we propose structural semantic readout (SSRead) to summarize the node representations at the position-level, which allows to model the position-specific weight parameters for classification as well as to effectively capture the graph semantic relevant to the global structure. Given an input graph, SSRead aims to identify structurally-meaningful positions by using the semantic alignment between its nodes and structural prototypes, which encode the prototypical features of each position. The structural prototypes are optimized to minimize the alignment cost for all training graphs, while the other GNN parameters are trained to predict the class labels. Our experimental results demonstrate that SSRead significantly improves the classification performance and interpretability of GNN classifiers while being compatible with a variety of aggregation functions, GNN architectures, and learning frameworks.