 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Manifold Regularization in Contextual Embedding Space for Text Classification
Paper and Code
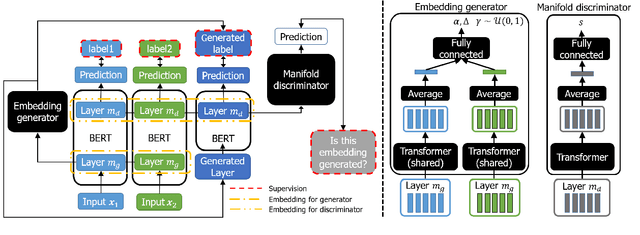

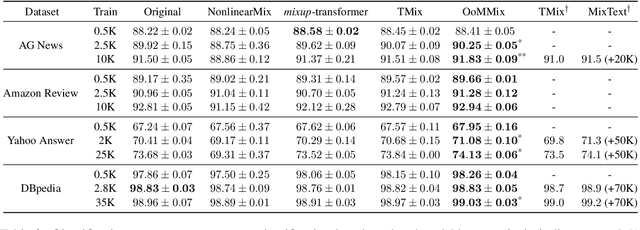
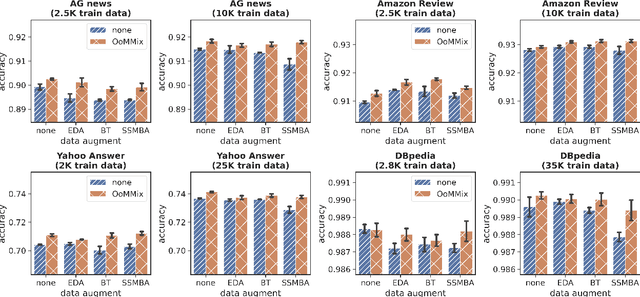
Recent studies on neural networks with pre-trained weights (i.e., BERT) have mainly focused on a low-dimensional subspace, where the embedding vectors computed from input words (or their contexts) are located. In this work, we propose a new approach to finding and regularizing the remainder of the space, referred to as out-of-manifold, which cannot be accessed through the words. Specifically, we synthesize the out-of-manifold embeddings based on two embeddings obtained from actually-observed words, to utilize them for fine-tuning the network. A discriminator is trained to detect whether an input embedding is located inside the manifold or not, and simultaneously, a generator is optimized to produce new embeddings that can be easily identified as out-of-manifold by the discriminator. These two modules successfully collaborate in a unified and end-to-end manner for regularizing the out-of-manifold. Our extensive evaluation on various text classification benchmarks demonstrates the effectiveness of our approach, as well as its good compatibility with existing data augmentation techniques which aim to enhance the manifold.