 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Robust Cross-Lingual Entity Alignment via Joint Modeling of Entity and Relation Texts
Jul 22, 2024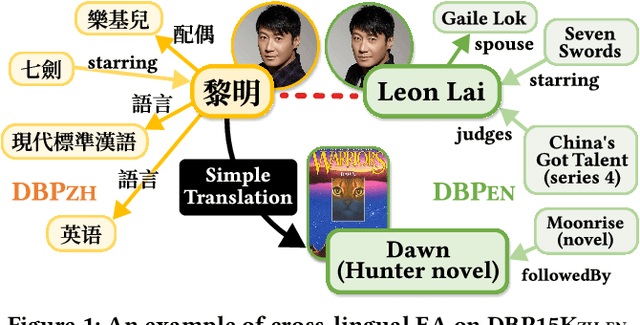
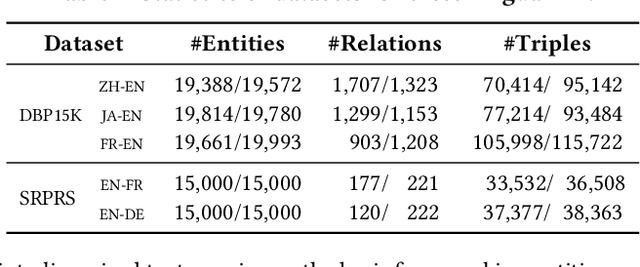
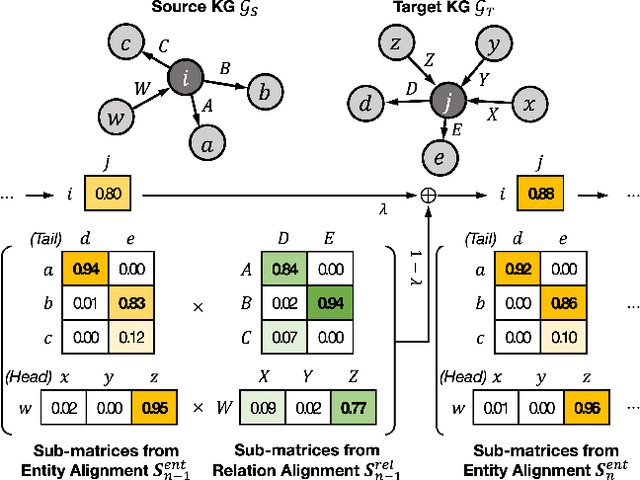
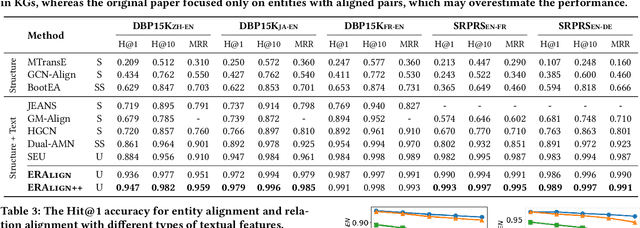
Cross-lingual entity alignment (EA) enables the integration of multiple knowledge graphs (KGs) across different languages, providing users with seamless access to diverse and comprehensive knowledge.Existing methods, mostly supervised, face challenges in obtaining labeled entity pairs. To address this, recent studies have shifted towards a self-supervised and unsupervised frameworks. Despite their effectiveness, these approaches have limitations: (1) they mainly focus on entity features, neglecting the semantic information of relations, (2) they assume isomorphism between source and target graphs, leading to noise and reduced alignment accuracy, and (3) they are susceptible to noise in the textual features, especially when encountering inconsistent translations or Out-Of-Vocabulary (OOV) problems. In this paper, we propose ERAlign, an unsupervised and robust cross-lingual EA framework that jointly performs Entity-level and Relation-level Alignment using semantic textual features of relations and entities. Its refinement process iteratively enhances results by fusing entity-level and relation-level alignments based on neighbor triple matching. The additional verification process examines the entities' neighbor triples as the linearized text. This \textit{Align-and-Verify} pipeline that rigorously assesses alignment results, achieving near-perfect alignment even in the presence of noisy textual features of entities. Our extensive experiments demonstrate that robustness and general applicability of \proposed improved the accuracy and effectiveness of EA tasks, contributing significantly to knowledge-oriented applications.
Evidence-Focused Fact Summarization for Knowledge-Augmented Zero-Shot Question Answering
Mar 05, 2024



Recent studies have investigated utilizing Knowledge Graphs (KGs) to enhance Quesetion Answering (QA) performance of Large Language Models (LLMs), yet structured KG verbalization remains challengin. Existing methods, such as triple-form or free-form textual conversion of triple-form facts, encounter several issues. These include reduced evidence density due to duplicated entities or relationships, and reduced evidence clarity due to an inability to emphasize crucial evidence. To address these issues, we propose EFSum, an Evidence-focused Fact Summarization framework for enhanced QA with knowledge-augmented LLMs. We optimize an open-source LLM as a fact summarizer through distillation and preference alignment. Our extensive experiments show that EFSum improves LLM's zero-shot QA performance, and it is possible to ensure both the helpfulness and faithfulness of the summary.