 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Think, But Not In Your Flow: Reasoning-Level Personalization for Black-Box Large Language Models
May 28, 2025Large language models (LLMs) have recently achieved impressive performance across a wide range of natural language tasks and are now widely used in real-world applications. Among them, black-box LLMs--served via APIs without access to model internals--are especially dominant due to their scalability and ease of deployment. Despite their strong capabilities, these models typically produce generalized responses that overlook personal preferences and reasoning styles. This has led to growing interest in black-box LLM personalization, which aims to tailor model outputs to user-specific context without modifying model parameters. However, existing approaches primarily focus on response-level personalization, attempting to match final outputs without modeling personal thought process. To address this limitation, we propose RPM, a framework for reasoning-level personalization that aligns the model's reasoning process with a user's personalized logic. RPM first constructs statistical user-specific factors by extracting and grouping response-influential features from user history. It then builds personalized reasoning paths that reflect how these factors are used in context. In the inference stage, RPM retrieves reasoning-aligned examples for new queries via feature-level similarity and performs inference conditioned on the structured factors and retrieved reasoning paths, enabling the model to follow user-specific reasoning trajectories. This reasoning-level personalization enhances both predictive accuracy and interpretability by grounding model outputs in user-specific logic through structured information. Extensive experiments across diverse tasks show that RPM consistently outperforms response-level personalization methods, demonstrating the effectiveness of reasoning-level personalization in black-box LLMs.
SC-Rec: Enhancing Generative Retrieval with Self-Consistent Reranking for~Sequential Recommendation
Aug 16, 2024Language Models (LMs) are increasingly employed in recommendation systems due to their advanced language understanding and generation capabilities. Recent recommender systems based on generative retrieval have leveraged the inferential abilities of LMs to directly generate the index tokens of the next item, based on item sequences within the user's interaction history. Previous studies have mostly focused on item indices based solely on textual semantic or collaborative information. However, although the standalone effectiveness of these aspects has been demonstrated, the integration of this information has remained unexplored. Our in-depth analysis finds that there is a significant difference in the knowledge captured by the model from heterogeneous item indices and diverse input prompts, which can have a high potential for complementarity. In this paper, we propose SC-Rec, a unified recommender system that learns diverse preference knowledge from two distinct item indices and multiple prompt templates. Furthermore, SC-Rec adopts a novel reranking strategy that aggregates a set of ranking results, inferred based on different indices and prompts, to achieve the self-consistency of the model. Our empirical evaluation on three real-world datasets demonstrates that SC-Rec considerably outperforms the state-of-the-art methods for sequential recommendation, effectively incorporating complementary knowledge from varied outputs of the model.
Unsupervised Robust Cross-Lingual Entity Alignment via Joint Modeling of Entity and Relation Texts
Jul 22, 2024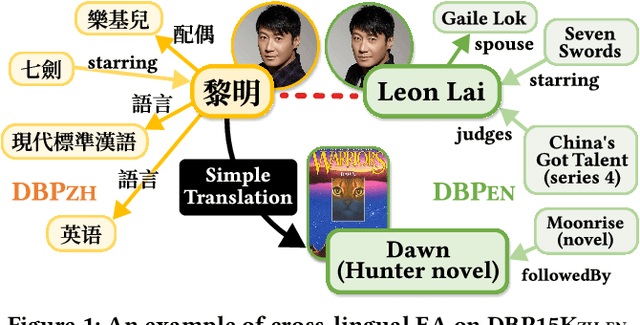
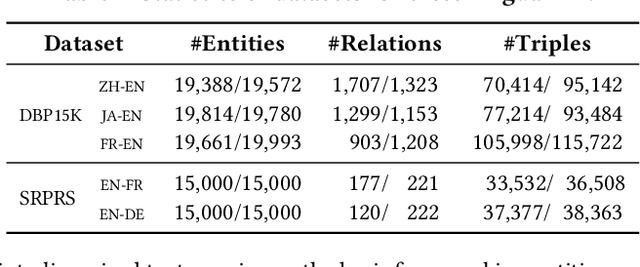
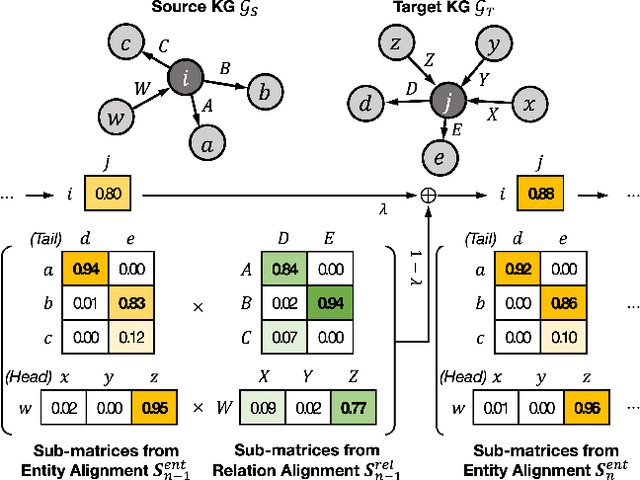
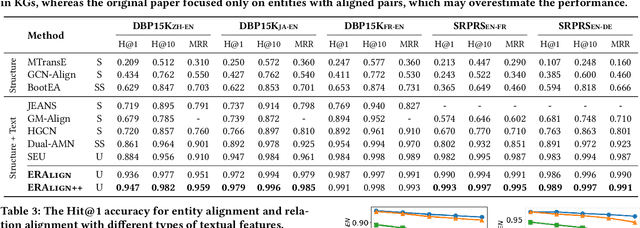
Cross-lingual entity alignment (EA) enables the integration of multiple knowledge graphs (KGs) across different languages, providing users with seamless access to diverse and comprehensive knowledge.Existing methods, mostly supervised, face challenges in obtaining labeled entity pairs. To address this, recent studies have shifted towards a self-supervised and unsupervised frameworks. Despite their effectiveness, these approaches have limitations: (1) they mainly focus on entity features, neglecting the semantic information of relations, (2) they assume isomorphism between source and target graphs, leading to noise and reduced alignment accuracy, and (3) they are susceptible to noise in the textual features, especially when encountering inconsistent translations or Out-Of-Vocabulary (OOV) problems. In this paper, we propose ERAlign, an unsupervised and robust cross-lingual EA framework that jointly performs Entity-level and Relation-level Alignment using semantic textual features of relations and entities. Its refinement process iteratively enhances results by fusing entity-level and relation-level alignments based on neighbor triple matching. The additional verification process examines the entities' neighbor triples as the linearized text. This \textit{Align-and-Verify} pipeline that rigorously assesses alignment results, achieving near-perfect alignment even in the presence of noisy textual features of entities. Our extensive experiments demonstrate that robustness and general applicability of \proposed improved the accuracy and effectiveness of EA tasks, contributing significantly to knowledge-oriented applications.