 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuse to Detect: Generative Diffusion Models for Unsupervised IC Anomaly Detection
May 26, 2026Latent defect screening is challenged by extremely low failure rates, high-dimensional test data, and absence of labeled anomalies. We propose the first unsupervised anomaly detection framework incorporating a Diffusion Transformer. Raw test measurements are first compressed by an autoencoder, then reshaped into a structured token sequence enriched with sinusoidal and per-device wafer-position embeddings. Anomaly scores are derived from the noise-prediction error over mid-range diffusion timesteps, enabling fast wafer-scale screening without any labeled defects or manual feature engineering. Our approach achieves state-of-the-art performance on industrial 16nm IC test data under extreme class imbalance, offering interpretable failure localization through latent-space reconstruction residuals.
Sparse Forcing: Native Trainable Sparse Attention for Real-time Autoregressive Diffusion Video Generation
Apr 23, 2026We introduce Sparse Forcing, a training-and-inference paradigm for autoregressive video diffusion models that improves long-horizon generation quality while reducing decoding latency. Sparse Forcing is motivated by an empirical observation in autoregressive diffusion rollouts: attention concentrates on a persistent subset of salient visual blocks, forming an implicit spatiotemporal memory in the KV cache, and exhibits a locally structured block-sparse pattern within sliding windows. Building on this observation, we propose a trainable native sparsity mechanism that learns to compress, preserve, and update these persistent blocks while restricting computation within each local window to a dynamically selected local neighborhood. To make the approach practical at scale for both training and inference, we further propose Persistent Block-Sparse Attention (PBSA), an efficient GPU kernel that accelerates sparse attention and memory updates for low-latency, memory-efficient decoding. Experiments show that Sparse Forcing improves the VBench score by +0.26 over Self-Forcing on 5-second text-to-video generation while delivering a 1.11-1.17x decoding speedup and 42% lower peak KV-cache footprint. The gains are more pronounced on longer-horizon rollouts, delivering improved visual quality with +0.68 and +2.74 VBench improvements, and 1.22x and 1.27x speedups on 20-second and 1-minute generations, respectively.
VEGAS: Mitigating Hallucinations in Large Vision-Language Models via Vision-Encoder Attention Guided Adaptive Steering
Dec 12, 2025Large vision-language models (LVLMs) exhibit impressive ability to jointly reason over visual and textual inputs. However, they often produce outputs that are linguistically fluent but factually inconsistent with the visual evidence, i.e., they hallucinate. Despite growing efforts to mitigate such hallucinations, a key question remains: what form of visual attention can effectively suppress hallucinations during decoding? In this work, we provide a simple answer: the vision encoder's own attention map. We show that LVLMs tend to hallucinate when their final visual-attention maps fail to concentrate on key image objects, whereas the vision encoder's more concentrated attention maps substantially reduce hallucinations. To further investigate the cause, we analyze vision-text conflicts during decoding and find that these conflicts peak in the language model's middle layers. Injecting the vision encoder's attention maps into these layers effectively suppresses hallucinations. Building on these insights, we introduce VEGAS, a simple yet effective inference-time method that integrates the vision encoder's attention maps into the language model's mid-layers and adaptively steers tokens which fail to concentrate on key image objects. Extensive experiments across multiple benchmarks demonstrate that VEGAS consistently achieves state-of-the-art performance in reducing hallucinations.
Large Language Models for EDA Cloud Job Resource and Lifetime Prediction
Dec 08, 2025The rapid growth of cloud computing in the Electronic Design Automation (EDA) industry has created a critical need for resource and job lifetime prediction to achieve optimal scheduling. Traditional machine learning methods often struggle with the complexity and heterogeneity of EDA workloads, requiring extensive feature engineering and domain expertise. We propose a novel framework that fine-tunes Large Language Models (LLMs) to address this challenge through text-to-text regression. We introduce the scientific notation and prefix filling to constrain the LLM, significantly improving output format reliability. Moreover, we found that full-attention finetuning and inference improves the prediction accuracy of sliding-window-attention LLMs. We demonstrate the effectiveness of our proposed framework on real-world cloud datasets, setting a new baseline for performance prediction in the EDA domain.
Khan-GCL: Kolmogorov-Arnold Network Based Graph Contrastive Learning with Hard Negatives
May 21, 2025Graph contrastive learning (GCL) has demonstrated great promise for learning generalizable graph representations from unlabeled data. However, conventional GCL approaches face two critical limitations: (1) the restricted expressive capacity of multilayer perceptron (MLP) based encoders, and (2) suboptimal negative samples that either from random augmentations-failing to provide effective 'hard negatives'-or generated hard negatives without addressing the semantic distinctions crucial for discriminating graph data. To this end, we propose Khan-GCL, a novel framework that integrates the Kolmogorov-Arnold Network (KAN) into the GCL encoder architecture, substantially enhancing its representational capacity. Furthermore, we exploit the rich information embedded within KAN coefficient parameters to develop two novel critical feature identification techniques that enable the generation of semantically meaningful hard negative samples for each graph representation. These strategically constructed hard negatives guide the encoder to learn more discriminative features by emphasizing critical semantic differences between graphs. Extensive experiments demonstrate that our approach achieves state-of-the-art performance compared to existing GCL methods across a variety of datasets and tasks.
SpikeX: Exploring Accelerator Architecture and Network-Hardware Co-Optimization for Sparse Spiking Neural Networks
May 18, 2025Spiking Neural Networks (SNNs) are promising biologically plausible models of computation which utilize a spiking binary activation function similar to that of biological neurons. SNNs are well positioned to process spatiotemporal data, and are advantageous in ultra-low power and real-time processing. Despite a large body of work on conventional artificial neural network accelerators, much less attention has been given to efficient SNN hardware accelerator design. In particular, SNNs exhibit inherent unstructured spatial and temporal firing sparsity, an opportunity yet to be fully explored for great hardware processing efficiency. In this work, we propose a novel systolic-array SNN accelerator architecture, called SpikeX, to take on the challenges and opportunities stemming from unstructured sparsity while taking into account the unique characteristics of spike-based computation. By developing an efficient dataflow targeting expensive multi-bit weight data movements, SpikeX reduces memory access and increases data sharing and hardware utilization for computations spanning across both time and space, thereby significantly improving energy efficiency and inference latency. Furthermore, recognizing the importance of SNN network and hardware co-design, we develop a co-optimization methodology facilitating not only hardware-aware SNN training but also hardware accelerator architecture search, allowing joint network weight parameter optimization and accelerator architectural reconfiguration. This end-to-end network/accelerator co-design approach offers a significant reduction of 15.1x-150.87x in energy-delay-product(EDP) without comprising model accuracy.
Bishop: Sparsified Bundling Spiking Transformers on Heterogeneous Cores with Error-Constrained Pruning
May 18, 2025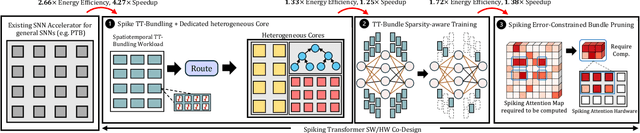
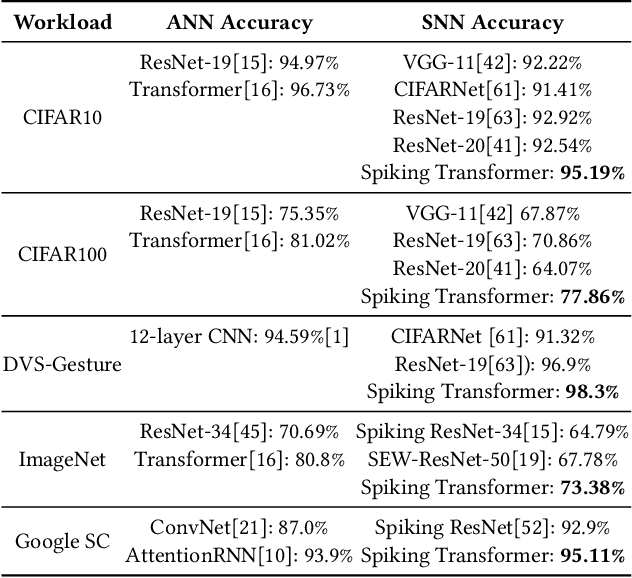
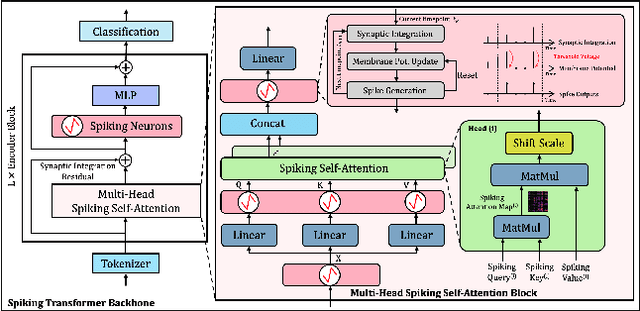
We present Bishop, the first dedicated hardware accelerator architecture and HW/SW co-design framework for spiking transformers that optimally represents, manages, and processes spike-based workloads while exploring spatiotemporal sparsity and data reuse. Specifically, we introduce the concept of Token-Time Bundle (TTB), a container that bundles spiking data of a set of tokens over multiple time points. Our heterogeneous accelerator architecture Bishop concurrently processes workload packed in TTBs and explores intra- and inter-bundle multiple-bit weight reuse to significantly reduce memory access. Bishop utilizes a stratifier, a dense core array, and a sparse core array to process MLP blocks and projection layers. The stratifier routes high-density spiking activation workload to the dense core and low-density counterpart to the sparse core, ensuring optimized processing tailored to the given spatiotemporal sparsity level. To further reduce data access and computation, we introduce a novel Bundle Sparsity-Aware (BSA) training pipeline that enhances not only the overall but also structured TTB-level firing sparsity. Moreover, the processing efficiency of self-attention layers is boosted by the proposed Error-Constrained TTB Pruning (ECP), which trims activities in spiking queries, keys, and values both before and after the computation of spiking attention maps with a well-defined error bound. Finally, we design a reconfigurable TTB spiking attention core to efficiently compute spiking attention maps by executing highly simplified "AND" and "Accumulate" operations. On average, Bishop achieves a 5.91x speedup and 6.11x improvement in energy efficiency over previous SNN accelerators, while delivering higher accuracy across multiple datasets.
Trimming Down Large Spiking Vision Transformers via Heterogeneous Quantization Search
Dec 07, 2024



Spiking Neural Networks (SNNs) are amenable to deployment on edge devices and neuromorphic hardware due to their lower dissipation. Recently, SNN-based transformers have garnered significant interest, incorporating attention mechanisms akin to their counterparts in Artificial Neural Networks (ANNs) while demonstrating excellent performance. However, deploying large spiking transformer models on resource-constrained edge devices such as mobile phones, still poses significant challenges resulted from the high computational demands of large uncompressed high-precision models. In this work, we introduce a novel heterogeneous quantization method for compressing spiking transformers through layer-wise quantization. Our approach optimizes the quantization of each layer using one of two distinct quantization schemes, i.e., uniform or power-of-two quantification, with mixed bit resolutions. Our heterogeneous quantization demonstrates the feasibility of maintaining high performance for spiking transformers while utilizing an average effective resolution of 3.14-3.67 bits with less than a 1% accuracy drop on DVS Gesture and CIFAR10-DVS datasets. It attains a model compression rate of 8.71x-10.19x for standard floating-point spiking transformers. Moreover, the proposed approach achieves a significant energy reduction of 5.69x, 8.72x, and 10.2x while maintaining high accuracy levels of 85.3%, 97.57%, and 80.4% on N-Caltech101, DVS-Gesture, and CIFAR10-DVS datasets, respectively.
Towards 3D Acceleration for low-power Mixture-of-Experts and Multi-Head Attention Spiking Transformers
Dec 07, 2024Spiking Neural Networks(SNNs) provide a brain-inspired and event-driven mechanism that is believed to be critical to unlock energy-efficient deep learning. The mixture-of-experts approach mirrors the parallel distributed processing of nervous systems, introducing conditional computation policies and expanding model capacity without scaling up the number of computational operations. Additionally, spiking mixture-of-experts self-attention mechanisms enhance representation capacity, effectively capturing diverse patterns of entities and dependencies between visual or linguistic tokens. However, there is currently a lack of hardware support for highly parallel distributed processing needed by spiking transformers, which embody a brain-inspired computation. This paper introduces the first 3D hardware architecture and design methodology for Mixture-of-Experts and Multi-Head Attention spiking transformers. By leveraging 3D integration with memory-on-logic and logic-on-logic stacking, we explore such brain-inspired accelerators with spatially stackable circuitry, demonstrating significant optimization of energy efficiency and latency compared to conventional 2D CMOS integration.
Spiking Transformer Hardware Accelerators in 3D Integration
Nov 11, 2024Spiking neural networks (SNNs) are powerful models of spatiotemporal computation and are well suited for deployment on resource-constrained edge devices and neuromorphic hardware due to their low power consumption. Leveraging attention mechanisms similar to those found in their artificial neural network counterparts, recently emerged spiking transformers have showcased promising performance and efficiency by capitalizing on the binary nature of spiking operations. Recognizing the current lack of dedicated hardware support for spiking transformers, this paper presents the first work on 3D spiking transformer hardware architecture and design methodology. We present an architecture and physical design co-optimization approach tailored specifically for spiking transformers. Through memory-on-logic and logic-on-logic stacking enabled by 3D integration, we demonstrate significant energy and delay improvements compared to conventional 2D CMOS integration.