 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEGAS: Mitigating Hallucinations in Large Vision-Language Models via Vision-Encoder Attention Guided Adaptive Steering
Dec 12, 2025Large vision-language models (LVLMs) exhibit impressive ability to jointly reason over visual and textual inputs. However, they often produce outputs that are linguistically fluent but factually inconsistent with the visual evidence, i.e., they hallucinate. Despite growing efforts to mitigate such hallucinations, a key question remains: what form of visual attention can effectively suppress hallucinations during decoding? In this work, we provide a simple answer: the vision encoder's own attention map. We show that LVLMs tend to hallucinate when their final visual-attention maps fail to concentrate on key image objects, whereas the vision encoder's more concentrated attention maps substantially reduce hallucinations. To further investigate the cause, we analyze vision-text conflicts during decoding and find that these conflicts peak in the language model's middle layers. Injecting the vision encoder's attention maps into these layers effectively suppresses hallucinations. Building on these insights, we introduce VEGAS, a simple yet effective inference-time method that integrates the vision encoder's attention maps into the language model's mid-layers and adaptively steers tokens which fail to concentrate on key image objects. Extensive experiments across multiple benchmarks demonstrate that VEGAS consistently achieves state-of-the-art performance in reducing hallucinations.
Khan-GCL: Kolmogorov-Arnold Network Based Graph Contrastive Learning with Hard Negatives
May 21, 2025Graph contrastive learning (GCL) has demonstrated great promise for learning generalizable graph representations from unlabeled data. However, conventional GCL approaches face two critical limitations: (1) the restricted expressive capacity of multilayer perceptron (MLP) based encoders, and (2) suboptimal negative samples that either from random augmentations-failing to provide effective 'hard negatives'-or generated hard negatives without addressing the semantic distinctions crucial for discriminating graph data. To this end, we propose Khan-GCL, a novel framework that integrates the Kolmogorov-Arnold Network (KAN) into the GCL encoder architecture, substantially enhancing its representational capacity. Furthermore, we exploit the rich information embedded within KAN coefficient parameters to develop two novel critical feature identification techniques that enable the generation of semantically meaningful hard negative samples for each graph representation. These strategically constructed hard negatives guide the encoder to learn more discriminative features by emphasizing critical semantic differences between graphs. Extensive experiments demonstrate that our approach achieves state-of-the-art performance compared to existing GCL methods across a variety of datasets and tasks.
On Learning Discriminative Features from Synthesized Data for Self-Supervised Fine-Grained Visual Recognition
Jul 19, 2024Self-Supervised Learning (SSL) has become a prominent approach for acquiring visual representations across various tasks, yet its application in fine-grained visual recognition (FGVR) is challenged by the intricate task of distinguishing subtle differences between categories. To overcome this, we introduce an novel strategy that boosts SSL's ability to extract critical discriminative features vital for FGVR. This approach creates synthesized data pairs to guide the model to focus on discriminative features critical for FGVR during SSL. We start by identifying non-discriminative features using two main criteria: features with low variance that fail to effectively separate data and those deemed less important by Grad-CAM induced from the SSL loss. We then introduce perturbations to these non-discriminative features while preserving discriminative ones. A decoder is employed to reconstruct images from both perturbed and original feature vectors to create data pairs. An encoder is trained on such generated data pairs to become invariant to variations in non-discriminative dimensions while focusing on discriminative features, thereby improving the model's performance in FGVR tasks. We demonstrate the promising FGVR performance of the proposed approach through extensive evaluation on a wide variety of datasets.
PID Control-Based Self-Healing to Improve the Robustness of Large Language Models
Mar 31, 2024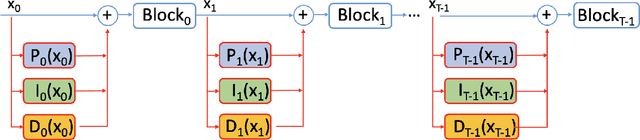
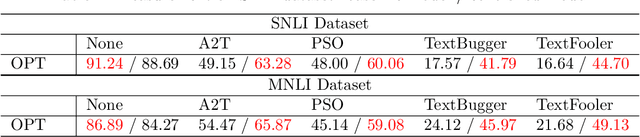
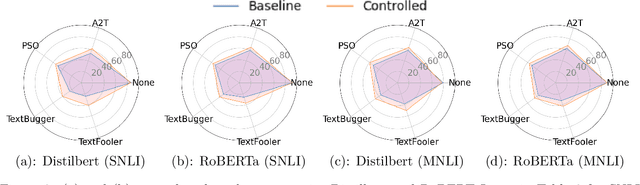

Despite the effectiveness of deep neural networks in numerous natural language processing applications, recent findings have exposed the vulnerability of these language models when minor perturbations are introduced. While appearing semantically indistinguishable to humans, these perturbations can significantly reduce the performance of well-trained language models, raising concerns about the reliability of deploying them in safe-critical situations. In this work, we construct a computationally efficient self-healing process to correct undesired model behavior during online inference when perturbations are applied to input data. This is formulated as a trajectory optimization problem in which the internal states of the neural network layers are automatically corrected using a PID (Proportional-Integral-Derivative) control mechanism. The P controller targets immediate state adjustments, while the I and D controllers consider past states and future dynamical trends, respectively. We leverage the geometrical properties of the training data to design effective linear PID controllers. This approach reduces the computational cost to that of using just the P controller, instead of the full PID control. Further, we introduce an analytical method for approximating the optimal control solutions, enhancing the real-time inference capabilities of this controlled system. Moreover, we conduct a theoretical error analysis of the analytic solution in a simplified setting. The proposed PID control-based self-healing is a low cost framework that improves the robustness of pre-trained large language models, whether standard or robustly trained, against a wide range of perturbations. A detailed implementation can be found in:https://github.com/zhuotongchen/PID-Control-Based-Self-Healing-to-Improve-the-Robustness-of-Large-Language-Models.
Contrastive Learning with Consistent Representations
Feb 03, 2023



Contrastive learning demonstrates great promise for representation learning. Data augmentations play a critical role in contrastive learning by providing informative views of the data without needing the labels. However, the performance of the existing works heavily relies on the quality of the employed data augmentation (DA) functions, which are typically hand picked from a restricted set of choices. While exploiting a diverse set of data augmentations is appealing, the intricacies of DAs and representation learning may lead to performance degradation. To address this challenge and allow for a systemic use of large numbers of data augmentations, this paper proposes Contrastive Learning with Consistent Representations (CoCor). At the core of CoCor is a new consistency measure, DA consistency, which dictates the mapping of augmented input data to the representation space such that these instances are mapped to optimal locations in a way consistent to the intensity of the DA applied. Furthermore, a data-driven approach is proposed to learn the optimal mapping locations as a function of DA while maintaining a desired monotonic property with respect to DA intensity. The proposed techniques give rise to a semi-supervised learning framework based on bi-level optimization, achieving new state-of-the-art results for image recognition.