 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning with Consistent Representations
Feb 03, 2023



Contrastive learning demonstrates great promise for representation learning. Data augmentations play a critical role in contrastive learning by providing informative views of the data without needing the labels. However, the performance of the existing works heavily relies on the quality of the employed data augmentation (DA) functions, which are typically hand picked from a restricted set of choices. While exploiting a diverse set of data augmentations is appealing, the intricacies of DAs and representation learning may lead to performance degradation. To address this challenge and allow for a systemic use of large numbers of data augmentations, this paper proposes Contrastive Learning with Consistent Representations (CoCor). At the core of CoCor is a new consistency measure, DA consistency, which dictates the mapping of augmented input data to the representation space such that these instances are mapped to optimal locations in a way consistent to the intensity of the DA applied. Furthermore, a data-driven approach is proposed to learn the optimal mapping locations as a function of DA while maintaining a desired monotonic property with respect to DA intensity. The proposed techniques give rise to a semi-supervised learning framework based on bi-level optimization, achieving new state-of-the-art results for image recognition.
BlueFog: Make Decentralized Algorithms Practical for Optimization and Deep Learning
Nov 08, 2021



Decentralized algorithm is a form of computation that achieves a global goal through local dynamics that relies on low-cost communication between directly-connected agents. On large-scale optimization tasks involving distributed datasets, decentralized algorithms have shown strong, sometimes superior, performance over distributed algorithms with a central node. Recently, developing decentralized algorithms for deep learning has attracted great attention. They are considered as low-communication-overhead alternatives to those using a parameter server or the Ring-Allreduce protocol. However, the lack of an easy-to-use and efficient software package has kept most decentralized algorithms merely on paper. To fill the gap, we introduce BlueFog, a python library for straightforward, high-performance implementations of diverse decentralized algorithms. Based on a unified abstraction of various communication operations, BlueFog offers intuitive interfaces to implement a spectrum of decentralized algorithms, from those using a static, undirected graph for synchronous operations to those using dynamic and directed graphs for asynchronous operations. BlueFog also adopts several system-level acceleration techniques to further optimize the performance on the deep learning tasks. On mainstream DNN training tasks, BlueFog reaches a much higher throughput and achieves an overall $1.2\times \sim 1.8\times$ speedup over Horovod, a state-of-the-art distributed deep learning package based on Ring-Allreduce. BlueFog is open source at https://github.com/Bluefog-Lib/bluefog.
Exponential Graph is Provably Efficient for Decentralized Deep Training
Oct 26, 2021
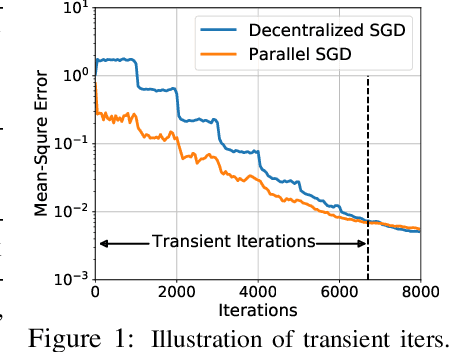
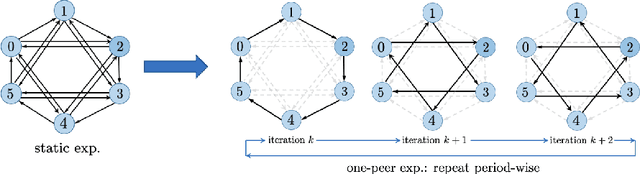
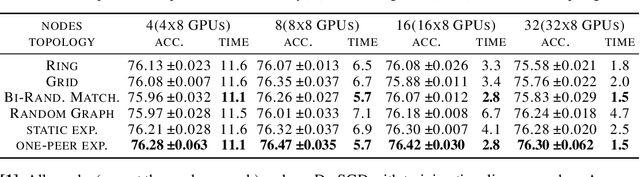
Decentralized SGD is an emerging training method for deep learning known for its much less (thus faster) communication per iteration, which relaxes the averaging step in parallel SGD to inexact averaging. The less exact the averaging is, however, the more the total iterations the training needs to take. Therefore, the key to making decentralized SGD efficient is to realize nearly-exact averaging using little communication. This requires a skillful choice of communication topology, which is an under-studied topic in decentralized optimization. In this paper, we study so-called exponential graphs where every node is connected to $O(\log(n))$ neighbors and $n$ is the total number of nodes. This work proves such graphs can lead to both fast communication and effective averaging simultaneously. We also discover that a sequence of $\log(n)$ one-peer exponential graphs, in which each node communicates to one single neighbor per iteration, can together achieve exact averaging. This favorable property enables one-peer exponential graph to average as effective as its static counterpart but communicates more efficiently. We apply these exponential graphs in decentralized (momentum) SGD to obtain the state-of-the-art balance between per-iteration communication and iteration complexity among all commonly-used topologies. Experimental results on a variety of tasks and models demonstrate that decentralized (momentum) SGD over exponential graphs promises both fast and high-quality training. Our code is implemented through BlueFog and available at https://github.com/Bluefog-Lib/NeurIPS2021-Exponential-Graph.
Global Adversarial Attacks for Assessing Deep Learning Robustness
Jun 19, 2019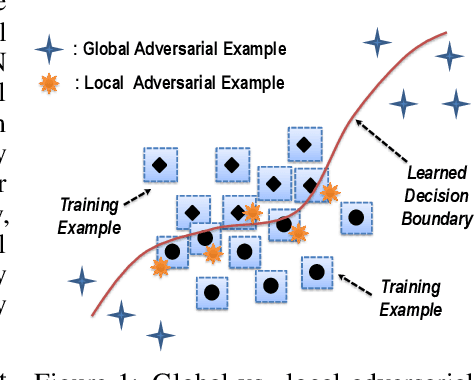
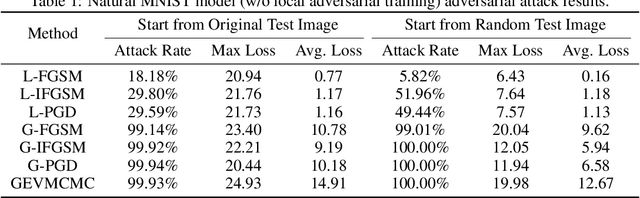
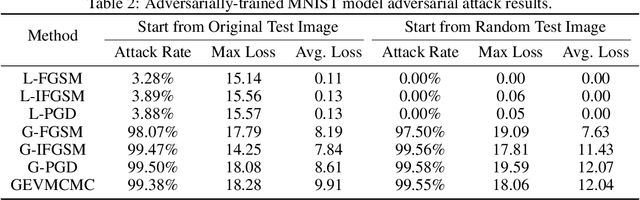

It has been shown that deep neural networks (DNNs) may be vulnerable to adversarial attacks, raising the concern on their robustness particularly for safety-critical applications. Recognizing the local nature and limitations of existing adversarial attacks, we present a new type of global adversarial attacks for assessing global DNN robustness. More specifically, we propose a novel concept of global adversarial example pairs in which each pair of two examples are close to each other but have different class labels predicted by the DNN. We further propose two families of global attack methods and show that our methods are able to generate diverse and intriguing adversarial example pairs at locations far from the training or testing data. Moreover, we demonstrate that DNNs hardened using the strong projected gradient descent (PGD) based (local) adversarial training are vulnerable to the proposed global adversarial example pairs, suggesting that global robustness must be considered while training robust deep learning networks.