 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDE-RRD: A Knowledge Distillation Framework for Recommender System
Paper and Code


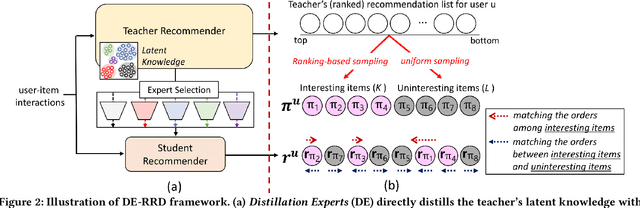

Recent recommender systems have started to employ knowledge distillation, which is a model compression technique distilling knowledge from a cumbersome model (teacher) to a compact model (student), to reduce inference latency while maintaining performance. The state-of-the-art methods have only focused on making the student model accurately imitate the predictions of the teacher model. They have a limitation in that the prediction results incompletely reveal the teacher's knowledge. In this paper, we propose a novel knowledge distillation framework for recommender system, called DE-RRD, which enables the student model to learn from the latent knowledge encoded in the teacher model as well as from the teacher's predictions. Concretely, DE-RRD consists of two methods: 1) Distillation Experts (DE) that directly transfers the latent knowledge from the teacher model. DE exploits "experts" and a novel expert selection strategy for effectively distilling the vast teacher's knowledge to the student with limited capacity. 2) Relaxed Ranking Distillation (RRD) that transfers the knowledge revealed from the teacher's prediction with consideration of the relaxed ranking orders among items. Our extensive experiments show that DE-RRD outperforms the state-of-the-art competitors and achieves comparable or even better performance to that of the teacher model with faster inference time.