 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKLUE: Korean Language Understanding Evaluation
Jun 11, 2021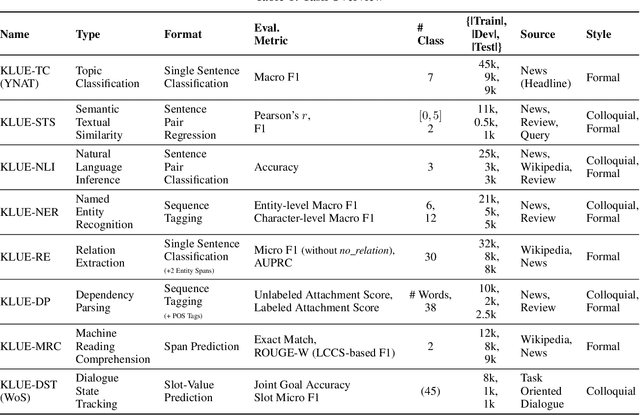
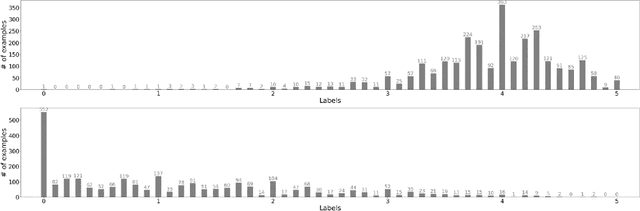
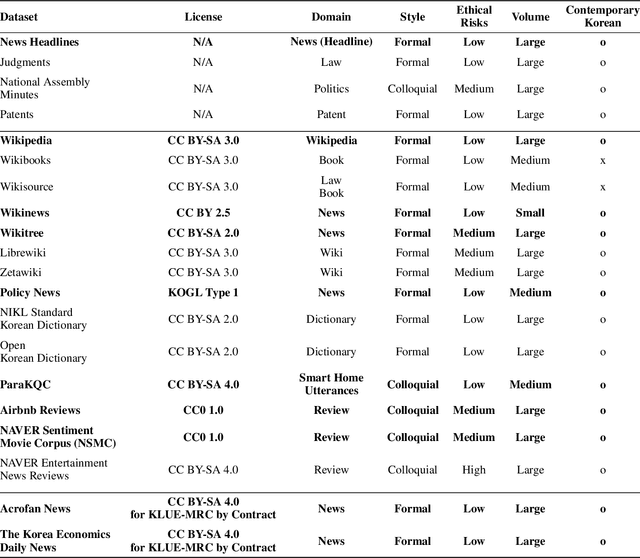
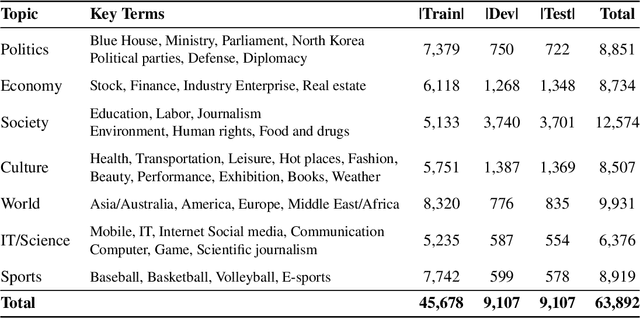
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.
An Empirical Study of Tokenization Strategies for Various Korean NLP Tasks
Oct 06, 2020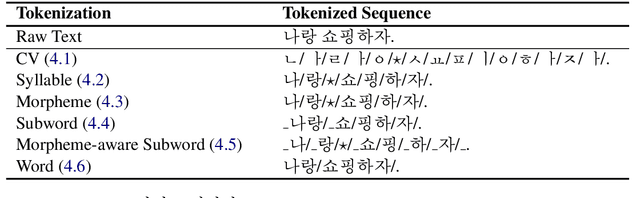
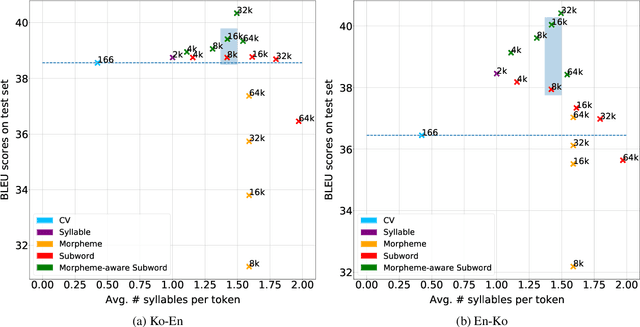
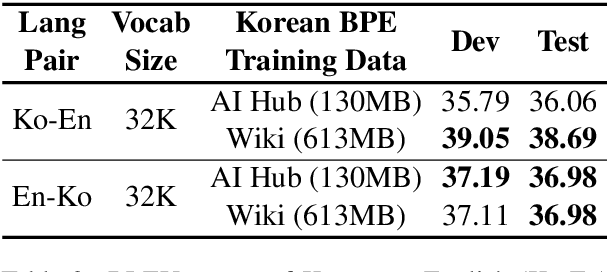
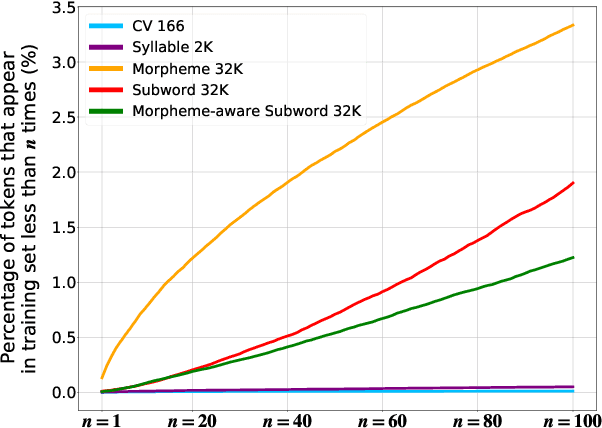
Typically, tokenization is the very first step in most text processing works. As a token serves as an atomic unit that embeds the contextual information of text, how to define a token plays a decisive role in the performance of a model.Even though Byte Pair Encoding (BPE) has been considered the de facto standard tokenization method due to its simplicity and universality, it still remains unclear whether BPE works best across all languages and tasks. In this paper, we test several tokenization strategies in order to answer our primary research question, that is, "What is the best tokenization strategy for Korean NLP tasks?" Experimental results demonstrate that a hybrid approach of morphological segmentation followed by BPE works best in Korean to/from English machine translation and natural language understanding tasks such as KorNLI, KorSTS, NSMC, and PAWS-X. As an exception, for KorQuAD, the Korean extension of SQuAD, BPE segmentation turns out to be the most effective.
Semantic Relation Classification via Bidirectional LSTM Networks with Entity-aware Attention using Latent Entity Typing
Jan 23, 2019
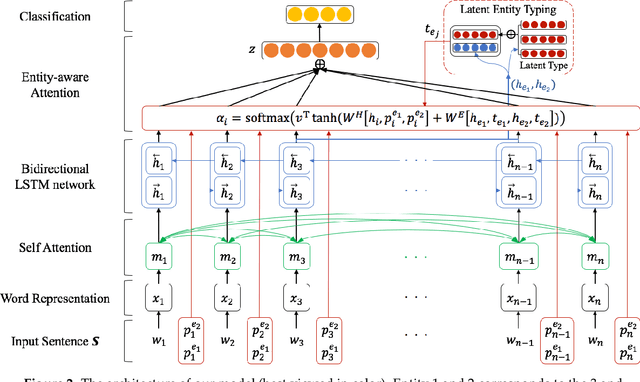
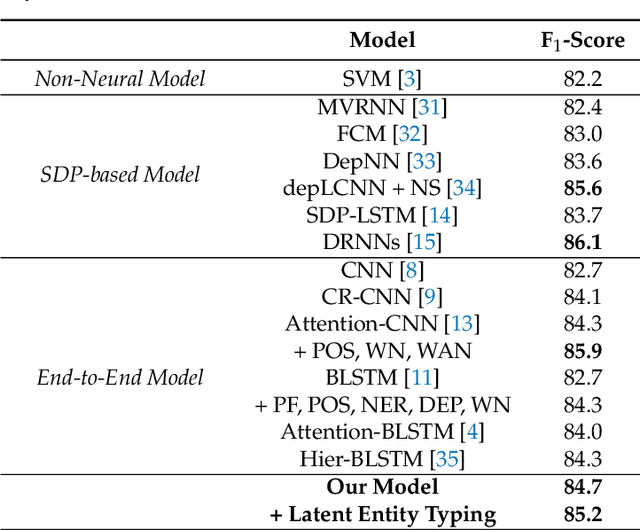
Classifying semantic relations between entity pairs in sentences is an important task in Natural Language Processing (NLP). Most previous models for relation classification rely on the high-level lexical and syntactic features obtained by NLP tools such as WordNet, dependency parser, part-of-speech (POS) tagger, and named entity recognizers (NER). In addition, state-of-the-art neural models based on attention mechanisms do not fully utilize information of entity that may be the most crucial features for relation classification. To address these issues, we propose a novel end-to-end recurrent neural model which incorporates an entity-aware attention mechanism with a latent entity typing (LET) method. Our model not only utilizes entities and their latent types as features effectively but also is more interpretable by visualizing attention mechanisms applied to our model and results of LET. Experimental results on the SemEval-2010 Task 8, one of the most popular relation classification task, demonstrate that our model outperforms existing state-of-the-art models without any high-level features.
A Tool for Spatio-Temporal Analysis of Social Anxiety with Twitter Data
Jan 23, 2019

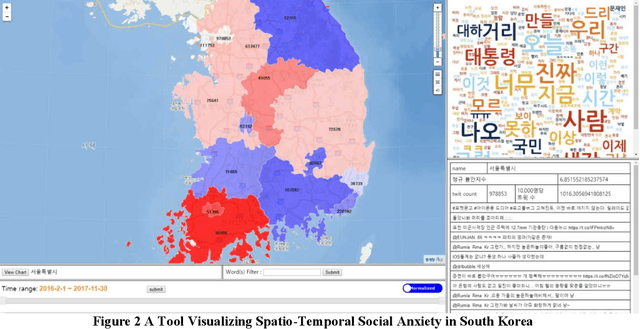
In this paper, we present a tool for analyzing spatio-temporal distribution of social anxiety. Twitter, one of the most popular social network services, has been chosen as data source for analysis of social anxiety. Tweets (posted on the Twitter) contain various emotions and thus these individual emotions reflect social atmosphere and public opinion, which are often dependent on spatial and temporal factors. The reason why we choose anxiety among various emotions is that anxiety is very important emotion that is useful for observing and understanding social events of communities. We develop a machine learning based tool to analyze the changes of social atmosphere spatially and temporally. Our tool classifies whether each Tweet contains anxious content or not, and also estimates degree of Tweet anxiety. Furthermore, it also visualizes spatio-temporal distribution of anxiety as a form of web application, which is incorporated with physical map, word cloud, search engine and chart viewer. Our tool is applied to a big tweet data in South Korea to illustrate its usefulness for exploring social atmosphere and public opinion spatio-temporally.