 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKanana: Compute-efficient Bilingual Language Models
Feb 26, 2025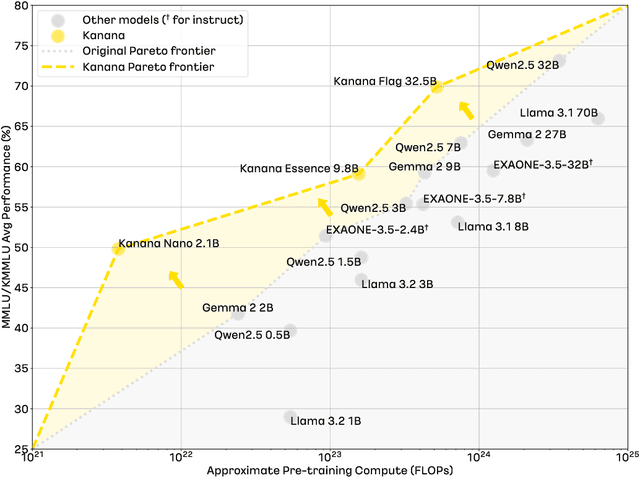



We introduce Kanana, a series of bilingual language models that demonstrate exceeding performance in Korean and competitive performance in English. The computational cost of Kanana is significantly lower than that of state-of-the-art models of similar size. The report details the techniques employed during pre-training to achieve compute-efficient yet competitive models, including high quality data filtering, staged pre-training, depth up-scaling, and pruning and distillation. Furthermore, the report outlines the methodologies utilized during the post-training of the Kanana models, encompassing supervised fine-tuning and preference optimization, aimed at enhancing their capability for seamless interaction with users. Lastly, the report elaborates on plausible approaches used for language model adaptation to specific scenarios, such as embedding, retrieval augmented generation, and function calling. The Kanana model series spans from 2.1B to 32.5B parameters with 2.1B models (base, instruct, embedding) publicly released to promote research on Korean language models.
CXR-CLIP: Toward Large Scale Chest X-ray Language-Image Pre-training
Oct 20, 2023A large-scale image-text pair dataset has greatly contributed to the development of vision-language pre-training (VLP) models, which enable zero-shot or few-shot classification without costly annotation. However, in the medical domain, the scarcity of data remains a significant challenge for developing a powerful VLP model. In this paper, we tackle the lack of image-text data in chest X-ray by expanding image-label pair as image-text pair via general prompt and utilizing multiple images and multiple sections in a radiologic report. We also design two contrastive losses, named ICL and TCL, for learning study-level characteristics of medical images and reports, respectively. Our model outperforms the state-of-the-art models trained under the same conditions. Also, enlarged dataset improve the discriminative power of our pre-trained model for classification, while sacrificing marginal retrieval performance. Code is available at https://github.com/kakaobrain/cxr-clip.
An Empirical Study of Invariant Risk Minimization
Apr 10, 2020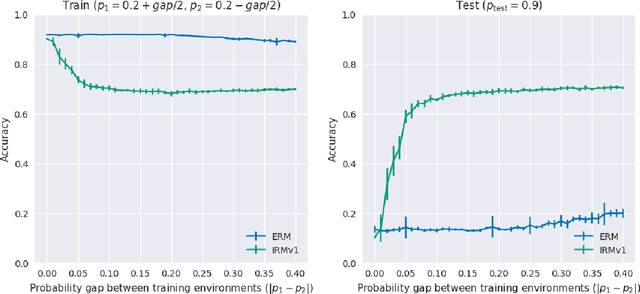
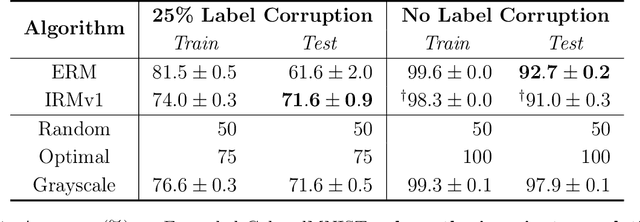
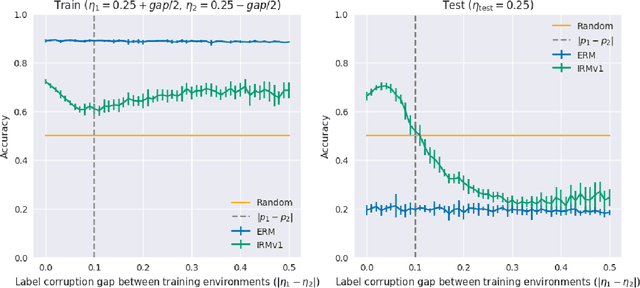

Invariant risk minimization (IRM; Arjovsky et al., 2019) is a recently proposed framework designed for learning predictors that are invariant to spurious correlations across different training environments. Because IRM does not assume that the test data is identically distributed as the training data, it can allow models to learn invariances that generalize well on unseen and out-of-distribution (OOD) samples. Yet, despite this theoretical justification, IRM has not been extensively tested across various settings. In an attempt to gain a better understanding of IRM, we empirically investigate several research questions using IRMv1, which is the first practical algorithm proposed in (Arjovsky et al., 2019) to approximately solve IRM. By extending the ColoredMNIST experiment from (Arjovsky et al., 2019) in multiple ways, we find that IRMv1 (i) performs better as the spurious correlation varies more widely between training environments, (ii) learns an approximately invariant predictor when the underlying relationship is approximately invariant, and (iii) can be extended to multiple environments, multiple outcomes, and different modalities (i.e., text). We hope that this work will shed light on the characteristics of IRM and help with applying IRM to real-world OOD generalization tasks.
KorNLI and KorSTS: New Benchmark Datasets for Korean Natural Language Understanding
Apr 08, 2020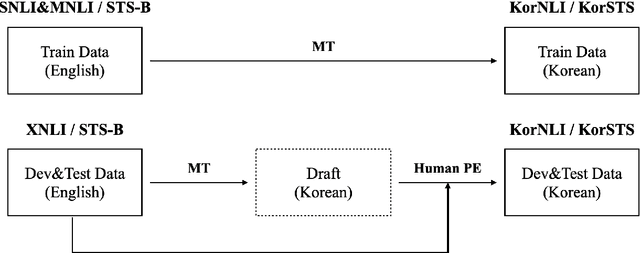
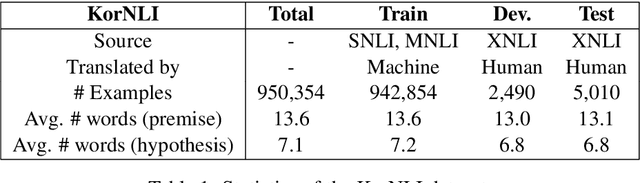
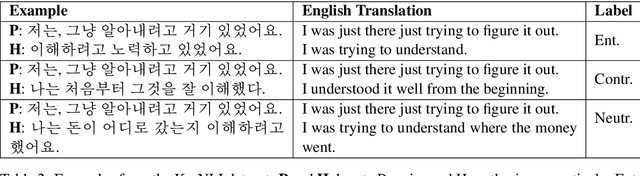
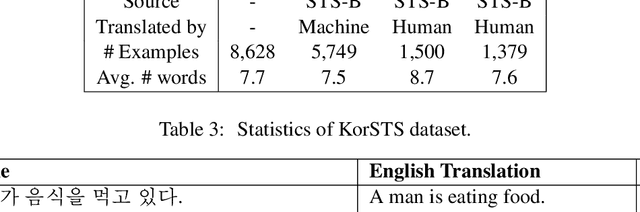
Natural language inference (NLI) and semantic textual similarity (STS) are key tasks in natural language understanding (NLU). Although several benchmark datasets for those tasks have been released in English and a few other languages, there are no publicly available NLI or STS datasets in the Korean language. Motivated by this, we construct and release new datasets for Korean NLI and STS, dubbed KorNLI and KorSTS, respectively. Following previous approaches, we machine-translate existing English training sets and manually translate development and test sets into Korean. To accelerate research on Korean NLU, we also establish baselines on KorNLI and KorSTS. Our datasets are made publicly available via our GitHub repository.
Jejueo Datasets for Machine Translation and Speech Synthesis
Nov 27, 2019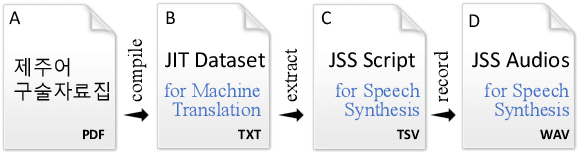
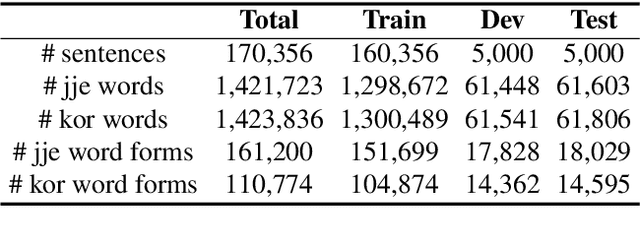
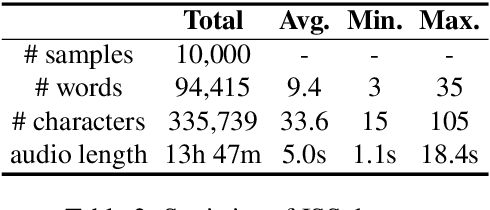
Jejueo was classified as critically endangered by UNESCO in 2010. Although diverse efforts to revitalize it have been made, there have been few computational approaches. Motivated by this, we construct two new Jejueo datasets: Jejueo Interview Transcripts (JIT) and Jejueo Single Speaker Speech (JSS). The JIT dataset is a parallel corpus containing 170k+ Jejueo-Korean sentences, and the JSS dataset consists of 10k high-quality audio files recorded by a native Jejueo speaker and a transcript file. Subsequently, we build neural systems of machine translation and speech synthesis using them. All resources are publicly available via our GitHub repository. We hope that these datasets will attract interest of both language and machine learning communities.
A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
Jul 02, 2019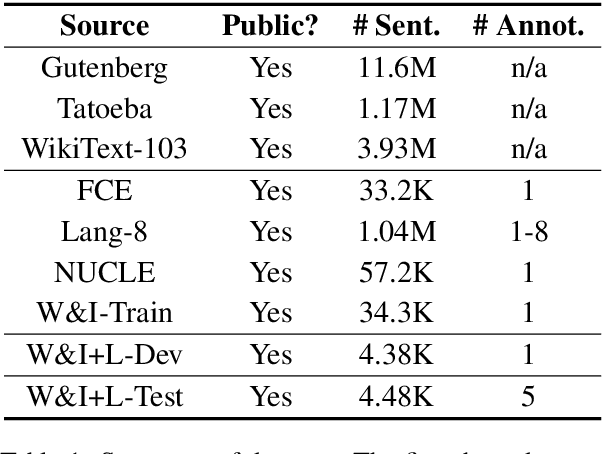

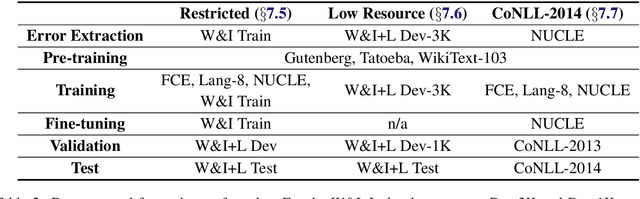
Grammatical error correction can be viewed as a low-resource sequence-to-sequence task, because publicly available parallel corpora are limited. To tackle this challenge, we first generate erroneous versions of large unannotated corpora using a realistic noising function. The resulting parallel corpora are subsequently used to pre-train Transformer models. Then, by sequentially applying transfer learning, we adapt these models to the domain and style of the test set. Combined with a context-aware neural spellchecker, our system achieves competitive results in both restricted and low resource tracks in ACL 2019 BEA Shared Task. We release all of our code and materials for reproducibility.
Predicting drug-target interaction using 3D structure-embedded graph representations from graph neural networks
Apr 17, 2019
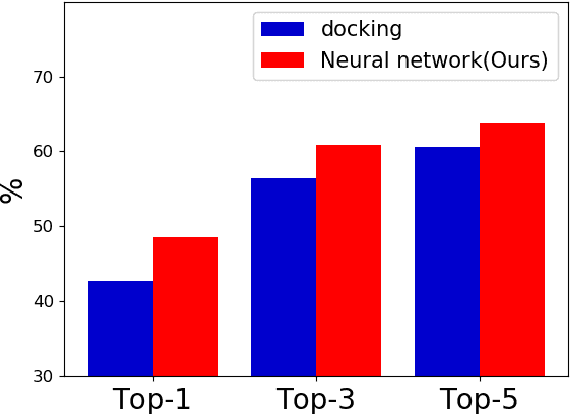

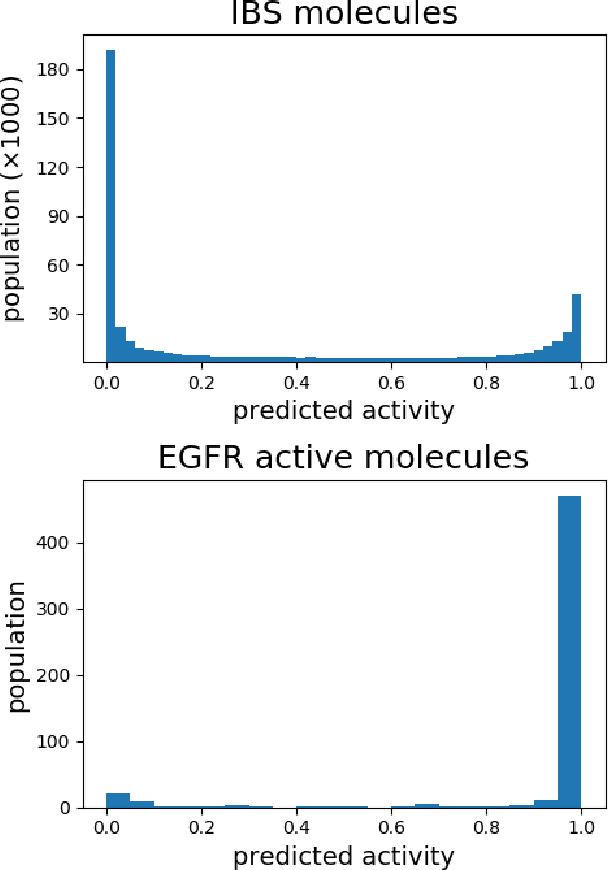
Accurate prediction of drug-target interaction (DTI) is essential for in silico drug design. For the purpose, we propose a novel approach for predicting DTI using a GNN that directly incorporates the 3D structure of a protein-ligand complex. We also apply a distance-aware graph attention algorithm with gate augmentation to increase the performance of our model. As a result, our model shows better performance than docking and other deep learning methods for both virtual screening and pose prediction. In addition, our model can reproduce the natural population distribution of active molecules and inactive molecules.