 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKanana: Compute-efficient Bilingual Language Models
Feb 26, 2025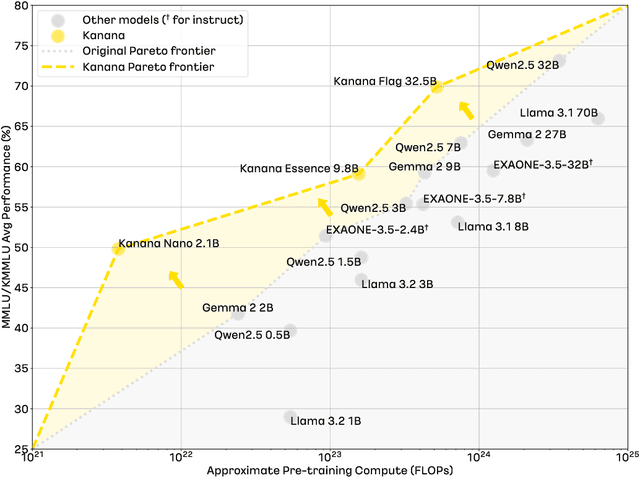



We introduce Kanana, a series of bilingual language models that demonstrate exceeding performance in Korean and competitive performance in English. The computational cost of Kanana is significantly lower than that of state-of-the-art models of similar size. The report details the techniques employed during pre-training to achieve compute-efficient yet competitive models, including high quality data filtering, staged pre-training, depth up-scaling, and pruning and distillation. Furthermore, the report outlines the methodologies utilized during the post-training of the Kanana models, encompassing supervised fine-tuning and preference optimization, aimed at enhancing their capability for seamless interaction with users. Lastly, the report elaborates on plausible approaches used for language model adaptation to specific scenarios, such as embedding, retrieval augmented generation, and function calling. The Kanana model series spans from 2.1B to 32.5B parameters with 2.1B models (base, instruct, embedding) publicly released to promote research on Korean language models.
TLCR: Token-Level Continuous Reward for Fine-grained Reinforcement Learning from Human Feedback
Jul 23, 2024



Reinforcement Learning from Human Feedback (RLHF) leverages human preference data to train language models to align more closely with human essence. These human preference data, however, are labeled at the sequence level, creating a mismatch between sequence-level preference labels and tokens, which are autoregressively generated from the language model. Although several recent approaches have tried to provide token-level (i.e., dense) rewards for each individual token, these typically rely on predefined discrete reward values (e.g., positive: +1, negative: -1, neutral: 0), failing to account for varying degrees of preference inherent to each token. To address this limitation, we introduce TLCR (Token-Level Continuous Reward) for RLHF, which incorporates a discriminator trained to distinguish positive and negative tokens, and the confidence of the discriminator is used to assign continuous rewards to each token considering the context. Extensive experiments show that our proposed TLCR leads to consistent performance improvements over previous sequence-level or token-level discrete rewards on open-ended generation benchmarks.
Binary Classifier Optimization for Large Language Model Alignment
Apr 06, 2024



Aligning Large Language Models (LLMs) to human preferences through preference optimization has been crucial but labor-intensive, necessitating for each prompt a comparison of both a chosen and a rejected text completion by evaluators. Recently, Kahneman-Tversky Optimization (KTO) has demonstrated that LLMs can be aligned using merely binary "thumbs-up" or "thumbs-down" signals on each prompt-completion pair. In this paper, we present theoretical foundations to explain the successful alignment achieved through these binary signals. Our analysis uncovers a new perspective: optimizing a binary classifier, whose logit is a reward, implicitly induces minimizing the Direct Preference Optimization (DPO) loss. In the process of this discovery, we identified two techniques for effective alignment: reward shift and underlying distribution matching. Consequently, we propose a new algorithm, \textit{Binary Classifier Optimization}, that integrates the techniques. We validate our methodology in two settings: first, on a paired preference dataset, where our method performs on par with DPO and KTO; and second, on binary signal datasets simulating real-world conditions with divergent underlying distributions between thumbs-up and thumbs-down data. Our model consistently demonstrates effective and robust alignment across two base LLMs and three different binary signal datasets, showcasing the strength of our approach to learning from binary feedback.
Hexa: Self-Improving for Knowledge-Grounded Dialogue System
Oct 22, 2023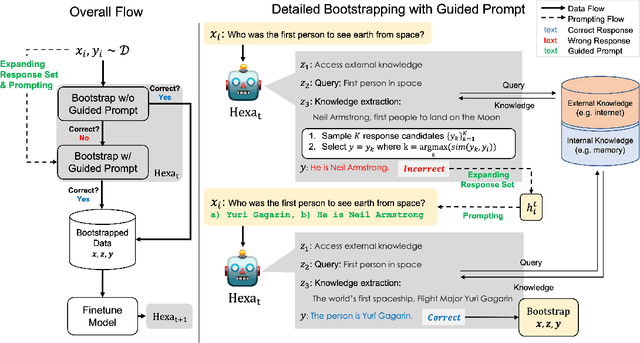
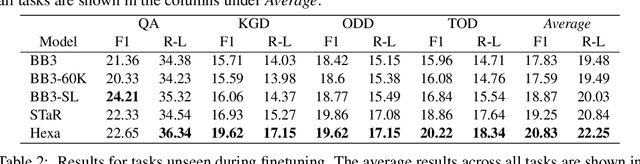
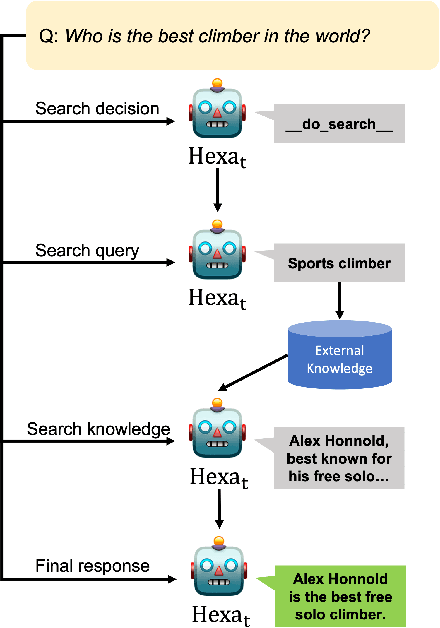

A common practice in knowledge-grounded dialogue generation is to explicitly utilize intermediate steps (e.g., web-search, memory retrieval) with modular approaches. However, data for such steps are often inaccessible compared to those of dialogue responses as they are unobservable in an ordinary dialogue. To fill in the absence of these data, we develop a self-improving method to improve the generative performances of intermediate steps without the ground truth data. In particular, we propose a novel bootstrapping scheme with a guided prompt and a modified loss function to enhance the diversity of appropriate self-generated responses. Through experiments on various benchmark datasets, we empirically demonstrate that our method successfully leverages a self-improving mechanism in generating intermediate and final responses and improves the performances on the task of knowledge-grounded dialogue generation.
Effortless Integration of Memory Management into Open-Domain Conversation Systems
May 23, 2023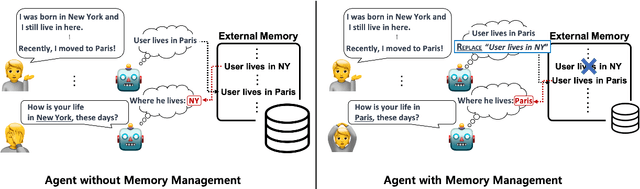
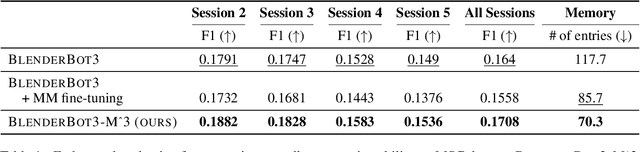
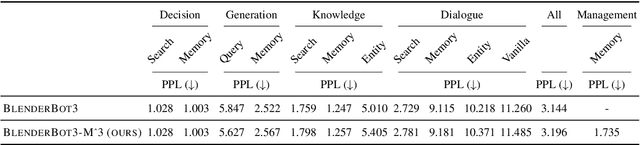
Open-domain conversation systems integrate multiple conversation skills into a single system through a modular approach. One of the limitations of the system, however, is the absence of management capability for external memory. In this paper, we propose a simple method to improve BlenderBot3 by integrating memory management ability into it. Since no training data exists for this purpose, we propose an automating dataset creation for memory management. Our method 1) requires little cost for data construction, 2) does not affect performance in other tasks, and 3) reduces external memory. We show that our proposed model BlenderBot3-M^3, which is multi-task trained with memory management, outperforms BlenderBot3 with a relative 4% performance gain in terms of F1 score.
LECO: Learnable Episodic Count for Task-Specific Intrinsic Reward
Oct 11, 2022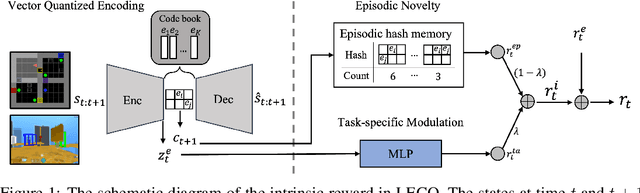
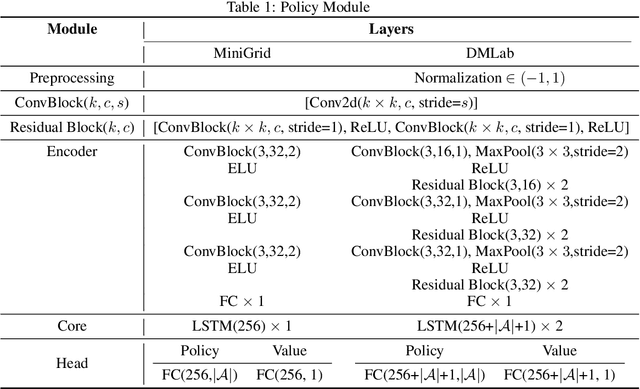
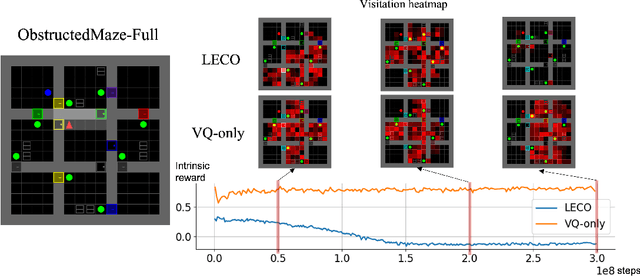
Episodic count has been widely used to design a simple yet effective intrinsic motivation for reinforcement learning with a sparse reward. However, the use of episodic count in a high-dimensional state space as well as over a long episode time requires a thorough state compression and fast hashing, which hinders rigorous exploitation of it in such hard and complex exploration environments. Moreover, the interference from task-irrelevant observations in the episodic count may cause its intrinsic motivation to overlook task-related important changes of states, and the novelty in an episodic manner can lead to repeatedly revisit the familiar states across episodes. In order to resolve these issues, in this paper, we propose a learnable hash-based episodic count, which we name LECO, that efficiently performs as a task-specific intrinsic reward in hard exploration problems. In particular, the proposed intrinsic reward consists of the episodic novelty and the task-specific modulation where the former employs a vector quantized variational autoencoder to automatically obtain the discrete state codes for fast counting while the latter regulates the episodic novelty by learning a modulator to optimize the task-specific extrinsic reward. The proposed LECO specifically enables the automatic transition from exploration to exploitation during reinforcement learning. We experimentally show that in contrast to the previous exploration methods LECO successfully solves hard exploration problems and also scales to large state spaces through the most difficult tasks in MiniGrid and DMLab environments.
GMAC: A Distributional Perspective on Actor-Critic Framework
May 24, 2021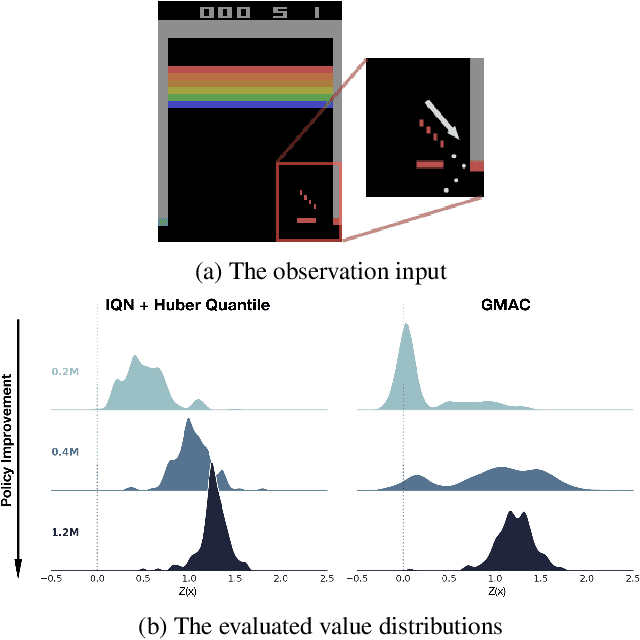
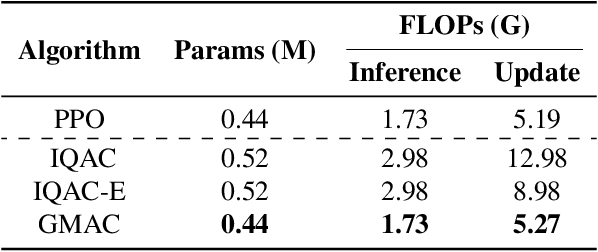
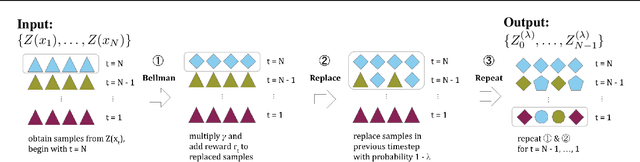
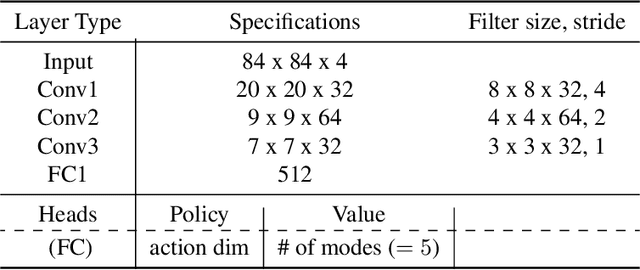
In this paper, we devise a distributional framework on actor-critic as a solution to distributional instability, action type restriction, and conflation between samples and statistics. We propose a new method that minimizes the Cram\'er distance with the multi-step Bellman target distribution generated from a novel Sample-Replacement algorithm denoted SR($\lambda$), which learns the correct value distribution under multiple Bellman operations. Parameterizing a value distribution with Gaussian Mixture Model further improves the efficiency and the performance of the method, which we name GMAC. We empirically show that GMAC captures the correct representation of value distributions and improves the performance of a conventional actor-critic method with low computational cost, in both discrete and continuous action spaces using Arcade Learning Environment (ALE) and PyBullet environment.