 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlot-MLLM: Object-Centric Visual Tokenization for Multimodal LLM
May 26, 2025Recently, multimodal large language models (MLLMs) have emerged as a key approach in achieving artificial general intelligence. In particular, vision-language MLLMs have been developed to generate not only text but also visual outputs from multimodal inputs. This advancement requires efficient image tokens that LLMs can process effectively both in input and output. However, existing image tokenization methods for MLLMs typically capture only global abstract concepts or uniformly segmented image patches, restricting MLLMs' capability to effectively understand or generate detailed visual content, particularly at the object level. To address this limitation, we propose an object-centric visual tokenizer based on Slot Attention specifically for MLLMs. In particular, based on the Q-Former encoder, diffusion decoder, and residual vector quantization, our proposed discretized slot tokens can encode local visual details while maintaining high-level semantics, and also align with textual data to be integrated seamlessly within a unified next-token prediction framework of LLMs. The resulting Slot-MLLM demonstrates significant performance improvements over baselines with previous visual tokenizers across various vision-language tasks that entail local detailed comprehension and generation. Notably, this work is the first demonstration of the feasibility of object-centric slot attention performed with MLLMs and in-the-wild natural images.
Duplex: A Device for Large Language Models with Mixture of Experts, Grouped Query Attention, and Continuous Batching
Sep 02, 2024



Large language models (LLMs) have emerged due to their capability to generate high-quality content across diverse contexts. To reduce their explosively increasing demands for computing resources, a mixture of experts (MoE) has emerged. The MoE layer enables exploiting a huge number of parameters with less computation. Applying state-of-the-art continuous batching increases throughput; however, it leads to frequent DRAM access in the MoE and attention layers. We observe that conventional computing devices have limitations when processing the MoE and attention layers, which dominate the total execution time and exhibit low arithmetic intensity (Op/B). Processing MoE layers only with devices targeting low-Op/B such as processing-in-memory (PIM) architectures is challenging due to the fluctuating Op/B in the MoE layer caused by continuous batching. To address these challenges, we propose Duplex, which comprises xPU tailored for high-Op/B and Logic-PIM to effectively perform low-Op/B operation within a single device. Duplex selects the most suitable processor based on the Op/B of each layer within LLMs. As the Op/B of the MoE layer is at least 1 and that of the attention layer has a value of 4-8 for grouped query attention, prior PIM architectures are not efficient, which place processing units inside DRAM dies and only target extremely low-Op/B (under one) operations. Based on recent trends, Logic-PIM adds more through-silicon vias (TSVs) to enable high-bandwidth communication between the DRAM die and the logic die and place powerful processing units on the logic die, which is best suited for handling low-Op/B operations ranging from few to a few dozens. To maximally utilize the xPU and Logic-PIM, we propose expert and attention co-processing.
NeuJeans: Private Neural Network Inference with Joint Optimization of Convolution and Bootstrapping
Dec 07, 2023Fully homomorphic encryption (FHE) is a promising cryptographic primitive for realizing private neural network inference (PI) services by allowing a client to fully offload the inference task to a cloud server while keeping the client data oblivious to the server. This work proposes NeuJeans, an FHE-based solution for the PI of deep convolutional neural networks (CNNs). NeuJeans tackles the critical problem of the enormous computational cost for the FHE evaluation of convolutional layers (conv2d), mainly due to the high cost of data reordering and bootstrapping. We first propose an encoding method introducing nested structures inside encoded vectors for FHE, which enables us to develop efficient conv2d algorithms with reduced data reordering costs. However, the new encoding method also introduces additional computations for conversion between encoding methods, which could negate its advantages. We discover that fusing conv2d with bootstrapping eliminates such computations while reducing the cost of bootstrapping. Then, we devise optimized execution flows for various types of conv2d and apply them to end-to-end implementation of CNNs. NeuJeans accelerates the performance of conv2d by up to 5.68 times compared to state-of-the-art FHE-based PI work and performs the PI of a CNN at the scale of ImageNet (ResNet18) within a mere few seconds
MAGVLT: Masked Generative Vision-and-Language Transformer
Mar 21, 2023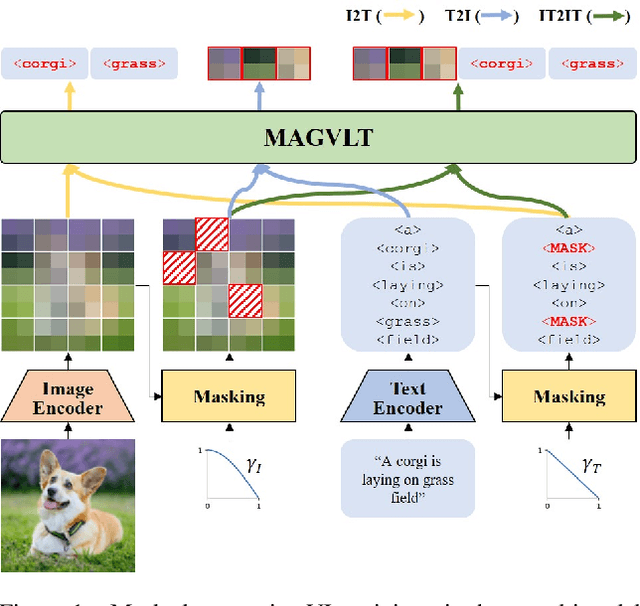
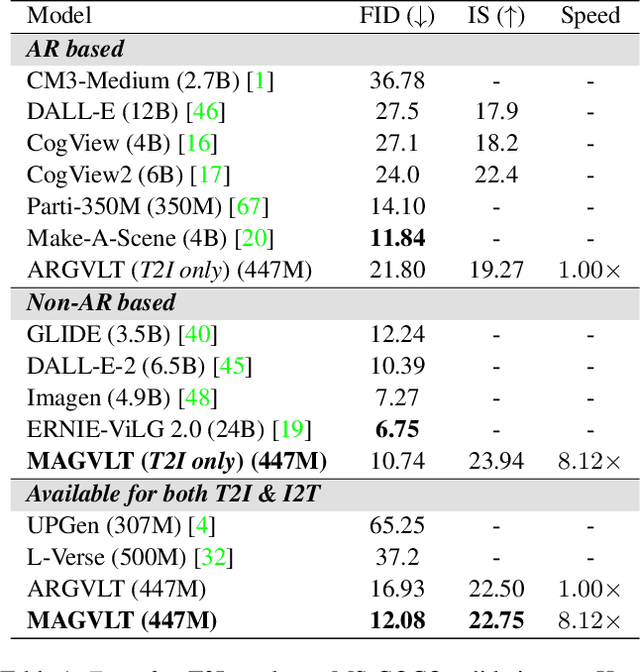
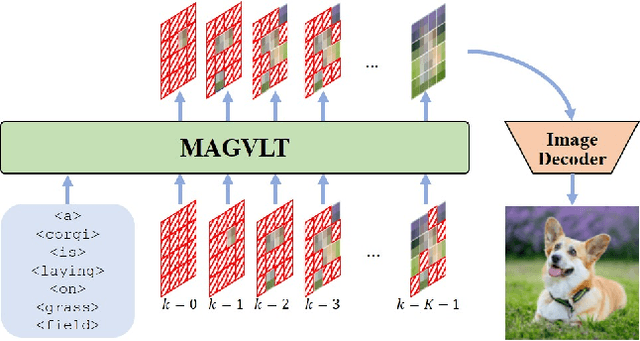
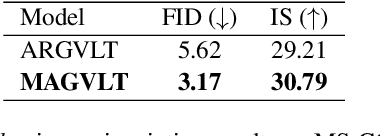
While generative modeling on multimodal image-text data has been actively developed with large-scale paired datasets, there have been limited attempts to generate both image and text data by a single model rather than a generation of one fixed modality conditioned on the other modality. In this paper, we explore a unified generative vision-and-language (VL) model that can produce both images and text sequences. Especially, we propose a generative VL transformer based on the non-autoregressive mask prediction, named MAGVLT, and compare it with an autoregressive generative VL transformer (ARGVLT). In comparison to ARGVLT, the proposed MAGVLT enables bidirectional context encoding, fast decoding by parallel token predictions in an iterative refinement, and extended editing capabilities such as image and text infilling. For rigorous training of our MAGVLT with image-text pairs from scratch, we combine the image-to-text, text-to-image, and joint image-and-text mask prediction tasks. Moreover, we devise two additional tasks based on the step-unrolled mask prediction and the selective prediction on the mixture of two image-text pairs. Experimental results on various downstream generation tasks of VL benchmarks show that our MAGVLT outperforms ARGVLT by a large margin even with significant inference speedup. Particularly, MAGVLT achieves competitive results on both zero-shot image-to-text and text-to-image generation tasks from MS-COCO by one moderate-sized model (fewer than 500M parameters) even without the use of monomodal data and networks.
HyPHEN: A Hybrid Packing Method and Optimizations for Homomorphic Encryption-Based Neural Networks
Feb 05, 2023Convolutional neural network (CNN) inference using fully homomorphic encryption (FHE) is a promising private inference (PI) solution due to the capability of FHE that enables offloading the whole computation process to the server while protecting the privacy of sensitive user data. However, prior FHEbased CNN (HCNN) implementations are far from being practical due to the high computational and memory overheads of FHE. To overcome this limitation, we present HyPHEN, a deep HCNN construction that features an efficient FHE convolution algorithm, data packing methods (hybrid packing and image slicing), and FHE-specific optimizations. Such enhancements enable HyPHEN to substantially reduce the memory footprint and the number of expensive homomorphic operations, such as ciphertext rotation and bootstrapping. As a result, HyPHEN brings the latency of HCNN CIFAR-10 inference down to a practical level at 1.40s (ResNet20) and demonstrates HCNN ImageNet inference for the first time at 16.87s (ResNet18).
LECO: Learnable Episodic Count for Task-Specific Intrinsic Reward
Oct 11, 2022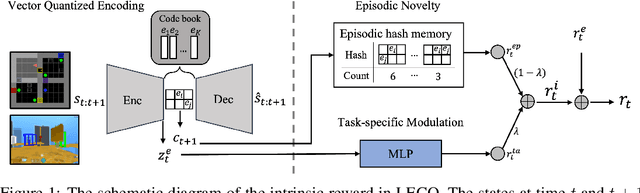
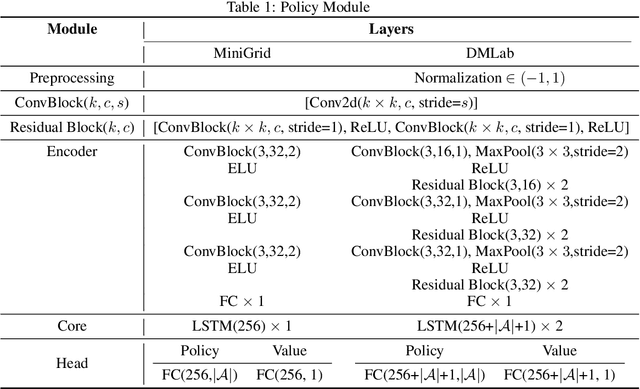
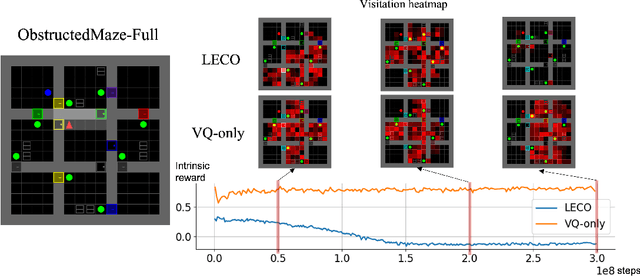
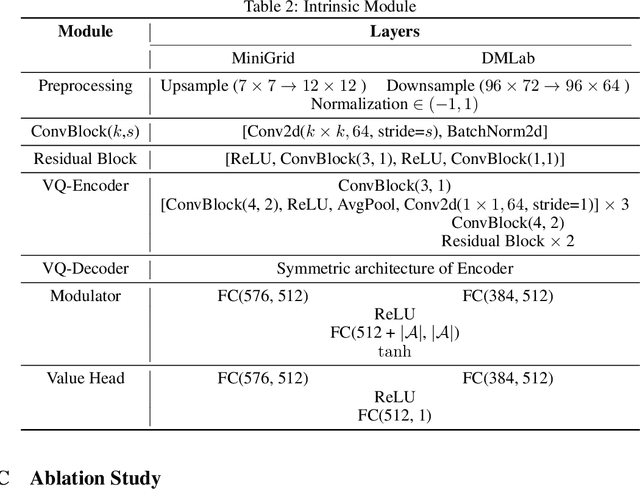
Episodic count has been widely used to design a simple yet effective intrinsic motivation for reinforcement learning with a sparse reward. However, the use of episodic count in a high-dimensional state space as well as over a long episode time requires a thorough state compression and fast hashing, which hinders rigorous exploitation of it in such hard and complex exploration environments. Moreover, the interference from task-irrelevant observations in the episodic count may cause its intrinsic motivation to overlook task-related important changes of states, and the novelty in an episodic manner can lead to repeatedly revisit the familiar states across episodes. In order to resolve these issues, in this paper, we propose a learnable hash-based episodic count, which we name LECO, that efficiently performs as a task-specific intrinsic reward in hard exploration problems. In particular, the proposed intrinsic reward consists of the episodic novelty and the task-specific modulation where the former employs a vector quantized variational autoencoder to automatically obtain the discrete state codes for fast counting while the latter regulates the episodic novelty by learning a modulator to optimize the task-specific extrinsic reward. The proposed LECO specifically enables the automatic transition from exploration to exploitation during reinforcement learning. We experimentally show that in contrast to the previous exploration methods LECO successfully solves hard exploration problems and also scales to large state spaces through the most difficult tasks in MiniGrid and DMLab environments.
Insights From the NeurIPS 2021 NetHack Challenge
Mar 22, 2022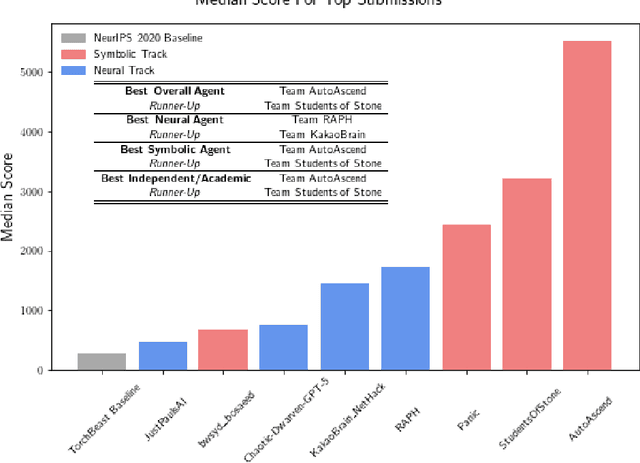

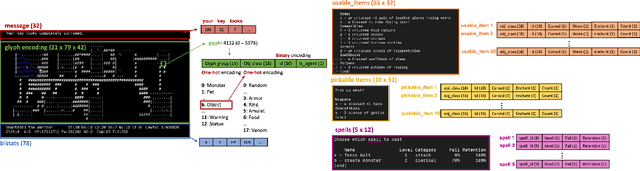
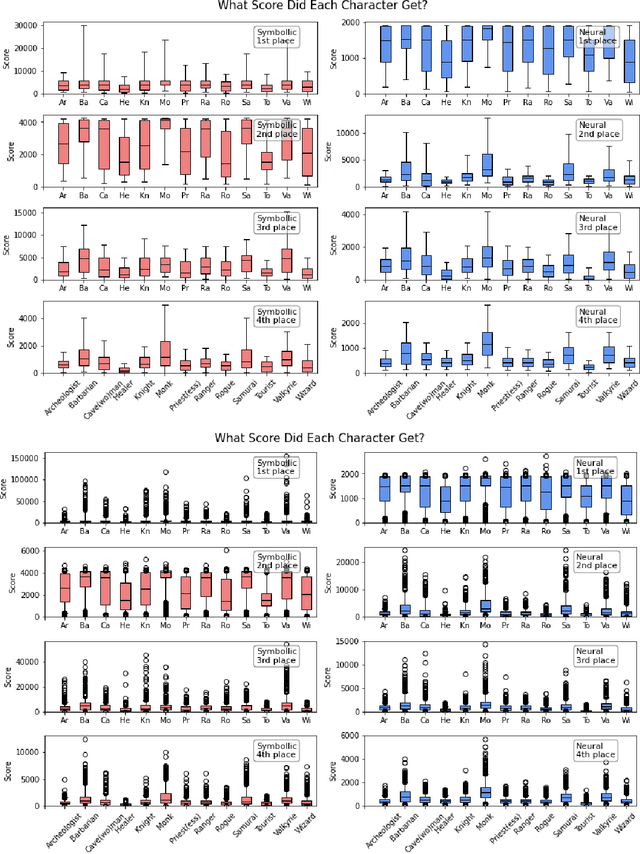
In this report, we summarize the takeaways from the first NeurIPS 2021 NetHack Challenge. Participants were tasked with developing a program or agent that can win (i.e., 'ascend' in) the popular dungeon-crawler game of NetHack by interacting with the NetHack Learning Environment (NLE), a scalable, procedurally generated, and challenging Gym environment for reinforcement learning (RL). The challenge showcased community-driven progress in AI with many diverse approaches significantly beating the previously best results on NetHack. Furthermore, it served as a direct comparison between neural (e.g., deep RL) and symbolic AI, as well as hybrid systems, demonstrating that on NetHack symbolic bots currently outperform deep RL by a large margin. Lastly, no agent got close to winning the game, illustrating NetHack's suitability as a long-term benchmark for AI research.
Automated Learning Rate Scheduler for Large-batch Training
Jul 13, 2021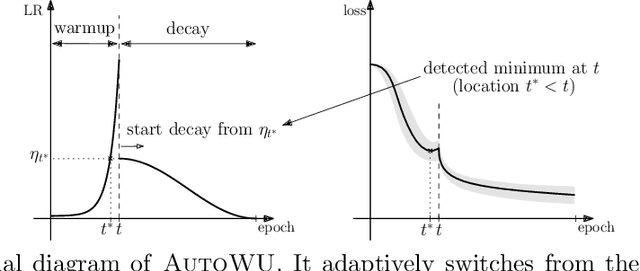
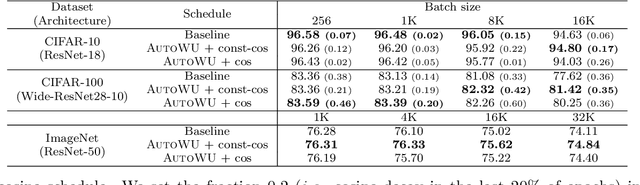
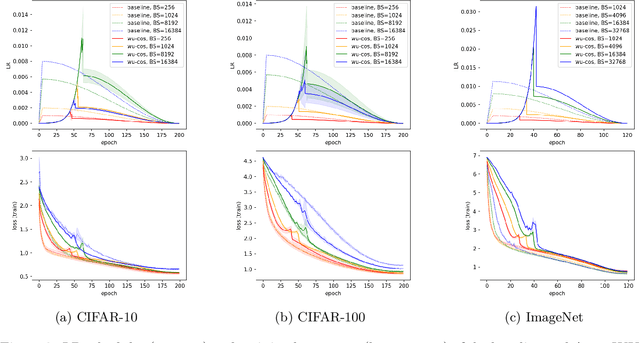

Large-batch training has been essential in leveraging large-scale datasets and models in deep learning. While it is computationally beneficial to use large batch sizes, it often requires a specially designed learning rate (LR) schedule to achieve a comparable level of performance as in smaller batch training. Especially, when the number of training epochs is constrained, the use of a large LR and a warmup strategy is critical in the final performance of large-batch training due to the reduced number of updating steps. In this work, we propose an automated LR scheduling algorithm which is effective for neural network training with a large batch size under the given epoch budget. In specific, the whole schedule consists of two phases: adaptive warmup and predefined decay, where the LR is increased until the training loss no longer decreases and decreased to zero until the end of training. Here, whether the training loss has reached the minimum value is robustly checked with Gaussian process smoothing in an online manner with a low computational burden. Coupled with adaptive stochastic optimizers such as AdamP and LAMB, the proposed scheduler successfully adjusts the LRs without cumbersome hyperparameter tuning and achieves comparable or better performances than tuned baselines on various image classification benchmarks and architectures with a wide range of batch sizes.
Edge-labeling Graph Neural Network for Few-shot Learning
May 04, 2019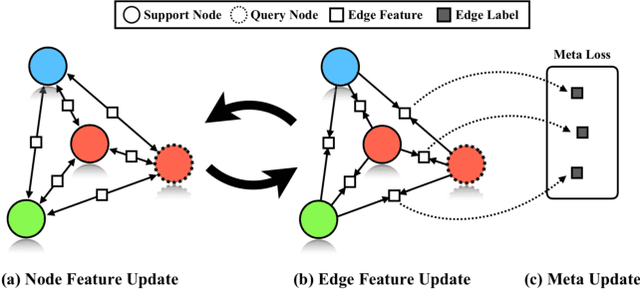
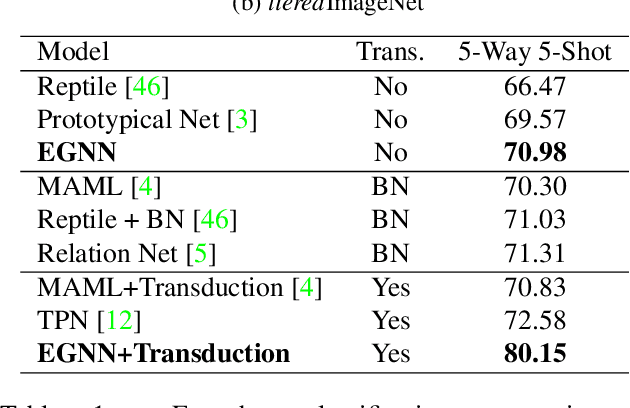
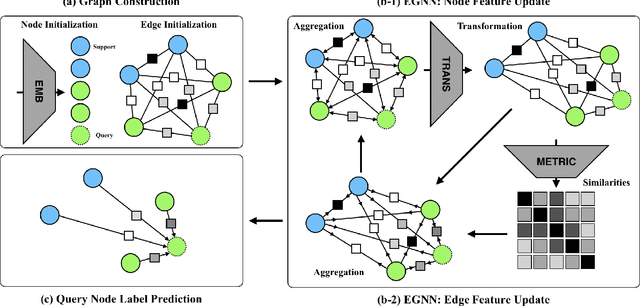
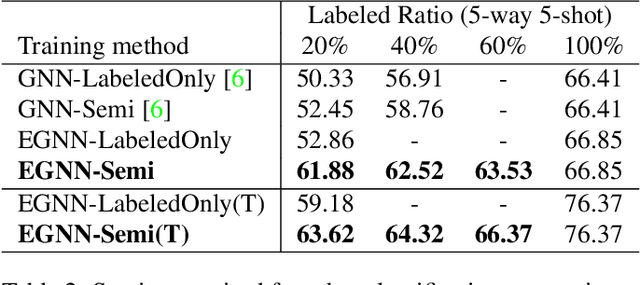
In this paper, we propose a novel edge-labeling graph neural network (EGNN), which adapts a deep neural network on the edge-labeling graph, for few-shot learning. The previous graph neural network (GNN) approaches in few-shot learning have been based on the node-labeling framework, which implicitly models the intra-cluster similarity and the inter-cluster dissimilarity. In contrast, the proposed EGNN learns to predict the edge-labels rather than the node-labels on the graph that enables the evolution of an explicit clustering by iteratively updating the edge-labels with direct exploitation of both intra-cluster similarity and the inter-cluster dissimilarity. It is also well suited for performing on various numbers of classes without retraining, and can be easily extended to perform a transductive inference. The parameters of the EGNN are learned by episodic training with an edge-labeling loss to obtain a well-generalizable model for unseen low-data problem. On both of the supervised and semi-supervised few-shot image classification tasks with two benchmark datasets, the proposed EGNN significantly improves the performances over the existing GNNs.