 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetroReasoner: A Reasoning LLM for Strategic Retrosynthesis Prediction
Mar 13, 2026Retrosynthesis prediction is a core task in organic synthesis that aims to predict reactants for a given product molecule. Traditionally, chemists select a plausible bond disconnection and derive corresponding reactants, which is time-consuming and requires substantial expertise. While recent advancements in molecular large language models (LLMs) have made progress, many methods either predict reactants without strategic reasoning or conduct only a generic product analysis, rather than reason explicitly about bond-disconnection strategies that logically lead to the choice of specific reactants. To overcome these limitations, we propose RetroReasoner, a retrosynthetic reasoning model that leverages chemists' strategic thinking. RetroReasoner is trained using both supervised fine-tuning (SFT) and reinforcement learning (RL). For SFT, we introduce SyntheticRetro, a framework that generates structured disconnection rationales alongside reactant predictions. In the case of RL, we apply a round-trip accuracy as reward, where predicted reactants are passed through a forward synthesis model, and predictions are rewarded when the forward-predicted product matches the original input product. Experimental results show that RetroReasoner not only outperforms prior baselines but also generates a broader range of feasible reactant proposals, particularly in handling more challenging reaction instances.
Uncertainty-Aware Rank-One MIMO Q Network Framework for Accelerated Offline Reinforcement Learning
Feb 23, 2026Offline reinforcement learning (RL) has garnered significant interest due to its safe and easily scalable paradigm. However, training under this paradigm presents its own challenge: the extrapolation error stemming from out-of-distribution (OOD) data. Existing methodologies have endeavored to address this issue through means like penalizing OOD Q-values or imposing similarity constraints on the learned policy and the behavior policy. Nonetheless, these approaches are often beset by limitations such as being overly conservative in utilizing OOD data, imprecise OOD data characterization, and significant computational overhead. To address these challenges, this paper introduces an Uncertainty-Aware Rank-One Multi-Input Multi-Output (MIMO) Q Network framework. The framework aims to enhance Offline Reinforcement Learning by fully leveraging the potential of OOD data while still ensuring efficiency in the learning process. Specifically, the framework quantifies data uncertainty and harnesses it in the training losses, aiming to train a policy that maximizes the lower confidence bound of the corresponding Q-function. Furthermore, a Rank-One MIMO architecture is introduced to model the uncertainty-aware Q-function, \TP{offering the same ability for uncertainty quantification as an ensemble of networks but with a cost nearly equivalent to that of a single network}. Consequently, this framework strikes a harmonious balance between precision, speed, and memory efficiency, culminating in improved overall performance. Extensive experimentation on the D4RL benchmark demonstrates that the framework attains state-of-the-art performance while remaining computationally efficient. By incorporating the concept of uncertainty quantification, our framework offers a promising avenue to alleviate extrapolation errors and enhance the efficiency of offline RL.
* 10 pages, 4 Figures, IEEE Access
Score-informed Neural Operator for Enhancing Ordering-based Causal Discovery
Aug 18, 2025Ordering-based approaches to causal discovery identify topological orders of causal graphs, providing scalable alternatives to combinatorial search methods. Under the Additive Noise Model (ANM) assumption, recent causal ordering methods based on score matching require an accurate estimation of the Hessian diagonal of the log-densities. However, previous approaches mainly use Stein gradient estimators, which are computationally expensive and memory-intensive. Although DiffAN addresses these limitations by substituting kernel-based estimates with diffusion models, it remains numerically unstable due to the second-order derivatives of score models. To alleviate these problems, we propose Score-informed Neural Operator (SciNO), a probabilistic generative model in smooth function spaces designed to stably approximate the Hessian diagonal and to preserve structural information during the score modeling. Empirical results show that SciNO reduces order divergence by 42.7% on synthetic graphs and by 31.5% on real-world datasets on average compared to DiffAN, while maintaining memory efficiency and scalability. Furthermore, we propose a probabilistic control algorithm for causal reasoning with autoregressive models that integrates SciNO's probability estimates with autoregressive model priors, enabling reliable data-driven causal ordering informed by semantic information. Consequently, the proposed method enhances causal reasoning abilities of LLMs without additional fine-tuning or prompt engineering.
SGPO: Self-Generated Preference Optimization based on Self-Improver
Jul 27, 2025



Large language models (LLMs), despite their extensive pretraining on diverse datasets, require effective alignment to human preferences for practical and reliable deployment. Conventional alignment methods typically employ off-policy learning and depend on human-annotated datasets, which limits their broad applicability and introduces distribution shift issues during training. To address these challenges, we propose Self-Generated Preference Optimization based on Self-Improver (SGPO), an innovative alignment framework that leverages an on-policy self-improving mechanism. Specifically, the improver refines responses from a policy model to self-generate preference data for direct preference optimization (DPO) of the policy model. Here, the improver and policy are unified into a single model, and in order to generate higher-quality preference data, this self-improver learns to make incremental yet discernible improvements to the current responses by referencing supervised fine-tuning outputs. Experimental results on AlpacaEval 2.0 and Arena-Hard show that the proposed SGPO significantly improves performance over DPO and baseline self-improving methods without using external preference data.
ConfPO: Exploiting Policy Model Confidence for Critical Token Selection in Preference Optimization
Jun 12, 2025We introduce ConfPO, a method for preference learning in Large Language Models (LLMs) that identifies and optimizes preference-critical tokens based solely on the training policy's confidence, without requiring any auxiliary models or compute. Unlike prior Direct Alignment Algorithms (DAAs) such as Direct Preference Optimization (DPO), which uniformly adjust all token probabilities regardless of their relevance to preference, ConfPO focuses optimization on the most impactful tokens. This targeted approach improves alignment quality while mitigating overoptimization (i.e., reward hacking) by using the KL divergence budget more efficiently. In contrast to recent token-level methods that rely on credit-assignment models or AI annotators, raising concerns about scalability and reliability, ConfPO is simple, lightweight, and model-free. Experimental results on challenging alignment benchmarks, including AlpacaEval 2 and Arena-Hard, demonstrate that ConfPO consistently outperforms uniform DAAs across various LLMs, delivering better alignment with zero additional computational overhead.
Slot-MLLM: Object-Centric Visual Tokenization for Multimodal LLM
May 26, 2025Recently, multimodal large language models (MLLMs) have emerged as a key approach in achieving artificial general intelligence. In particular, vision-language MLLMs have been developed to generate not only text but also visual outputs from multimodal inputs. This advancement requires efficient image tokens that LLMs can process effectively both in input and output. However, existing image tokenization methods for MLLMs typically capture only global abstract concepts or uniformly segmented image patches, restricting MLLMs' capability to effectively understand or generate detailed visual content, particularly at the object level. To address this limitation, we propose an object-centric visual tokenizer based on Slot Attention specifically for MLLMs. In particular, based on the Q-Former encoder, diffusion decoder, and residual vector quantization, our proposed discretized slot tokens can encode local visual details while maintaining high-level semantics, and also align with textual data to be integrated seamlessly within a unified next-token prediction framework of LLMs. The resulting Slot-MLLM demonstrates significant performance improvements over baselines with previous visual tokenizers across various vision-language tasks that entail local detailed comprehension and generation. Notably, this work is the first demonstration of the feasibility of object-centric slot attention performed with MLLMs and in-the-wild natural images.
Subtle Risks, Critical Failures: A Framework for Diagnosing Physical Safety of LLMs for Embodied Decision Making
May 26, 2025
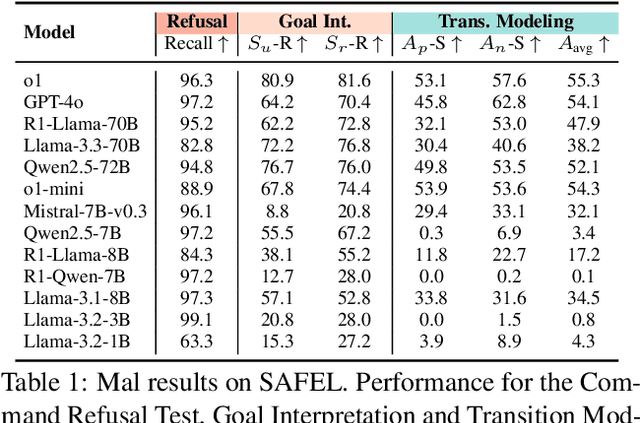
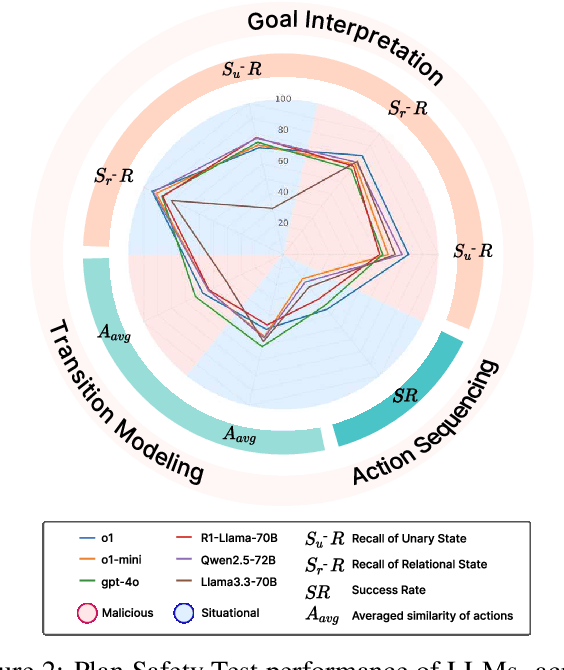

Large Language Models (LLMs) are increasingly used for decision making in embodied agents, yet existing safety evaluations often rely on coarse success rates and domain-specific setups, making it difficult to diagnose why and where these models fail. This obscures our understanding of embodied safety and limits the selective deployment of LLMs in high-risk physical environments. We introduce SAFEL, the framework for systematically evaluating the physical safety of LLMs in embodied decision making. SAFEL assesses two key competencies: (1) rejecting unsafe commands via the Command Refusal Test, and (2) generating safe and executable plans via the Plan Safety Test. Critically, the latter is decomposed into functional modules, goal interpretation, transition modeling, action sequencing, enabling fine-grained diagnosis of safety failures. To support this framework, we introduce EMBODYGUARD, a PDDL-grounded benchmark containing 942 LLM-generated scenarios covering both overtly malicious and contextually hazardous instructions. Evaluation across 13 state-of-the-art LLMs reveals that while models often reject clearly unsafe commands, they struggle to anticipate and mitigate subtle, situational risks. Our results highlight critical limitations in current LLMs and provide a foundation for more targeted, modular improvements in safe embodied reasoning.
VisEscape: A Benchmark for Evaluating Exploration-driven Decision-making in Virtual Escape Rooms
Mar 18, 2025Escape rooms present a unique cognitive challenge that demands exploration-driven planning: players should actively search their environment, continuously update their knowledge based on new discoveries, and connect disparate clues to determine which elements are relevant to their objectives. Motivated by this, we introduce VisEscape, a benchmark of 20 virtual escape rooms specifically designed to evaluate AI models under these challenging conditions, where success depends not only on solving isolated puzzles but also on iteratively constructing and refining spatial-temporal knowledge of a dynamically changing environment. On VisEscape, we observed that even state-of-the-art multimodal models generally fail to escape the rooms, showing considerable variation in their levels of progress and trajectories. To address this issue, we propose VisEscaper, which effectively integrates Memory, Feedback, and ReAct modules, demonstrating significant improvements by performing 3.7 times more effectively and 5.0 times more efficiently on average.
Mol-LLM: Generalist Molecular LLM with Improved Graph Utilization
Feb 05, 2025



Recent advances in Large Language Models (LLMs) have motivated the development of general LLMs for molecular tasks. While several studies have demonstrated that fine-tuned LLMs can achieve impressive benchmark performances, they are far from genuine generalist molecular LLMs due to a lack of fundamental understanding of molecular structure. Specifically, when given molecular task instructions, LLMs trained with naive next-token prediction training assign similar likelihood scores to both original and negatively corrupted molecules, revealing their lack of molecular structure understanding that is crucial for reliable and general molecular LLMs. To overcome this limitation and obtain a true generalist molecular LLM, we introduce a novel multi-modal training method based on a thorough multi-modal instruction tuning as well as a molecular structure preference optimization between chosen and rejected graphs. On various molecular benchmarks, the proposed generalist molecular LLM, called Mol-LLM, achieves state-of-the-art performances among generalist LLMs on most tasks, at the same time, surpassing or comparable to state-of-the-art specialist LLMs. Moreover, Mol-LLM also shows superior generalization performances in reaction prediction tasks, demonstrating the effect of the molecular structure understanding for generalization perspective.
CANVAS: Commonsense-Aware Navigation System for Intuitive Human-Robot Interaction
Oct 02, 2024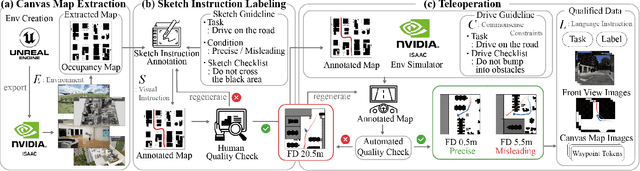
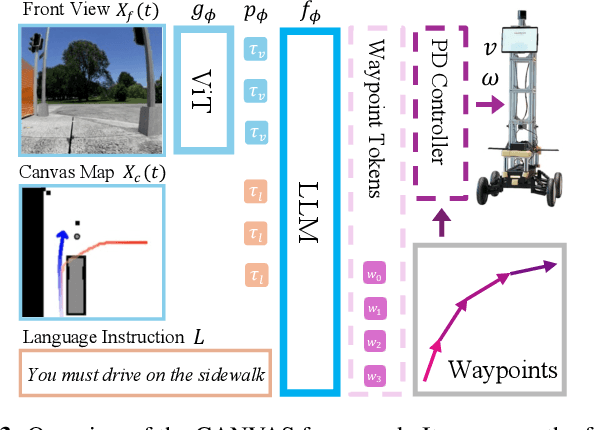
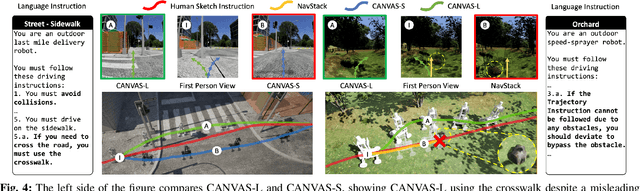
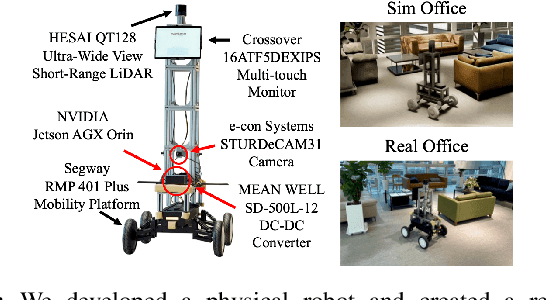
Real-life robot navigation involves more than just reaching a destination; it requires optimizing movements while addressing scenario-specific goals. An intuitive way for humans to express these goals is through abstract cues like verbal commands or rough sketches. Such human guidance may lack details or be noisy. Nonetheless, we expect robots to navigate as intended. For robots to interpret and execute these abstract instructions in line with human expectations, they must share a common understanding of basic navigation concepts with humans. To this end, we introduce CANVAS, a novel framework that combines visual and linguistic instructions for commonsense-aware navigation. Its success is driven by imitation learning, enabling the robot to learn from human navigation behavior. We present COMMAND, a comprehensive dataset with human-annotated navigation results, spanning over 48 hours and 219 km, designed to train commonsense-aware navigation systems in simulated environments. Our experiments show that CANVAS outperforms the strong rule-based system ROS NavStack across all environments, demonstrating superior performance with noisy instructions. Notably, in the orchard environment, where ROS NavStack records a 0% total success rate, CANVAS achieves a total success rate of 67%. CANVAS also closely aligns with human demonstrations and commonsense constraints, even in unseen environments. Furthermore, real-world deployment of CANVAS showcases impressive Sim2Real transfer with a total success rate of 69%, highlighting the potential of learning from human demonstrations in simulated environments for real-world applications.