 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Feedback Alignment
Dec 14, 2025Federated Learning (FL) enables collaborative training across multiple clients while preserving data privacy, yet it struggles with data heterogeneity, where clients' data are not distributed independently and identically (non-IID). This causes local drift, hindering global model convergence. To address this, we introduce Federated Learning with Feedback Alignment (FLFA), a novel framework that integrates feedback alignment into FL. FLFA uses the global model's weights as a shared feedback matrix during local training's backward pass, aligning local updates with the global model efficiently. This approach mitigates local drift with minimal additional computational cost and no extra communication overhead. Our theoretical analysis supports FLFA's design by showing how it alleviates local drift and demonstrates robust convergence for both local and global models. Empirical evaluations, including accuracy comparisons and measurements of local drift, further illustrate that FLFA can enhance other FL methods demonstrating its effectiveness.
Can TabPFN Compete with GNNs for Node Classification via Graph Tabularization?
Dec 09, 2025Foundation models pretrained on large data have demonstrated remarkable zero-shot generalization capabilities across domains. Building on the success of TabPFN for tabular data and its recent extension to time series, we investigate whether graph node classification can be effectively reformulated as a tabular learning problem. We introduce TabPFN-GN, which transforms graph data into tabular features by extracting node attributes, structural properties, positional encodings, and optionally smoothed neighborhood features. This enables TabPFN to perform direct node classification without any graph-specific training or language model dependencies. Our experiments on 12 benchmark datasets reveal that TabPFN-GN achieves competitive performance with GNNs on homophilous graphs and consistently outperforms them on heterophilous graphs. These results demonstrate that principled feature engineering can bridge the gap between tabular and graph domains, providing a practical alternative to task-specific GNN training and LLM-dependent graph foundation models.
Beyond Task-Oriented and Chitchat Dialogues: Proactive and Transition-Aware Conversational Agents
Nov 11, 2025Conversational agents have traditionally been developed for either task-oriented dialogue (TOD) or open-ended chitchat, with limited progress in unifying the two. Yet, real-world conversations naturally involve fluid transitions between these modes. To address this gap, we introduce TACT (TOD-And-Chitchat Transition), a dataset designed for transition-aware dialogue modeling that incorporates structurally diverse and integrated mode flows. TACT supports both user- and agent-driven mode switches, enabling robust modeling of complex conversational dynamics. To evaluate an agent's ability to initiate and recover from mode transitions, we propose two new metrics -- Switch and Recovery. Models trained on TACT outperform baselines in both intent detection and mode transition handling. Moreover, applying Direct Preference Optimization (DPO) to TACT-trained models yields additional gains, achieving 75.74\% joint mode-intent accuracy and a 70.1\% win rate against GPT-4o in human evaluation. These results demonstrate that pairing structurally diverse data with DPO enhances response quality and transition control, paving the way for more proactive and transition-aware conversational agents.
KRETA: A Benchmark for Korean Reading and Reasoning in Text-Rich VQA Attuned to Diverse Visual Contexts
Aug 27, 2025Understanding and reasoning over text within visual contexts poses a significant challenge for Vision-Language Models (VLMs), given the complexity and diversity of real-world scenarios. To address this challenge, text-rich Visual Question Answering (VQA) datasets and benchmarks have emerged for high-resource languages like English. However, a critical gap persists for low-resource languages such as Korean, where the lack of comprehensive benchmarks hinders robust model evaluation and comparison. To bridge this gap, we introduce KRETA, a benchmark for Korean Reading and rEasoning in Text-rich VQA Attuned to diverse visual contexts. KRETA facilitates an in-depth evaluation of both visual text understanding and reasoning capabilities, while also supporting a multifaceted assessment across 15 domains and 26 image types. Additionally, we introduce a semi-automated VQA generation pipeline specifically optimized for text-rich settings, leveraging refined stepwise image decomposition and a rigorous seven-metric evaluation protocol to ensure data quality. While KRETA is tailored for Korean, we hope our adaptable and extensible pipeline will facilitate the development of similar benchmarks in other languages, thereby accelerating multilingual VLM research. The code and dataset for KRETA are available at https://github.com/tabtoyou/KRETA.
Comparison Reveals Commonality: Customized Image Generation through Contrastive Inversion
Aug 11, 2025The recent demand for customized image generation raises a need for techniques that effectively extract the common concept from small sets of images. Existing methods typically rely on additional guidance, such as text prompts or spatial masks, to capture the common target concept. Unfortunately, relying on manually provided guidance can lead to incomplete separation of auxiliary features, which degrades generation quality.In this paper, we propose Contrastive Inversion, a novel approach that identifies the common concept by comparing the input images without relying on additional information. We train the target token along with the image-wise auxiliary text tokens via contrastive learning, which extracts the well-disentangled true semantics of the target. Then we apply disentangled cross-attention fine-tuning to improve concept fidelity without overfitting. Experimental results and analysis demonstrate that our method achieves a balanced, high-level performance in both concept representation and editing, outperforming existing techniques.
Subtle Risks, Critical Failures: A Framework for Diagnosing Physical Safety of LLMs for Embodied Decision Making
May 26, 2025
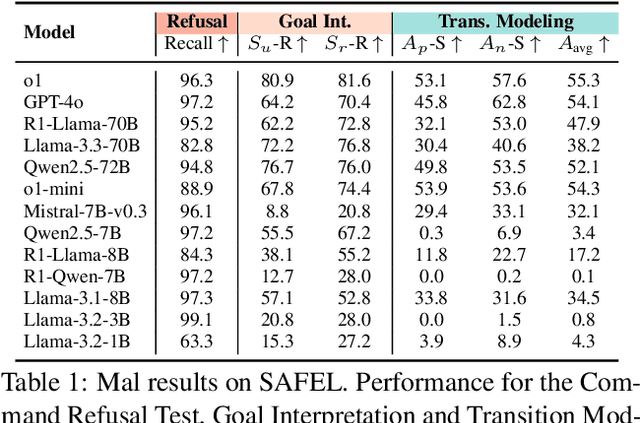
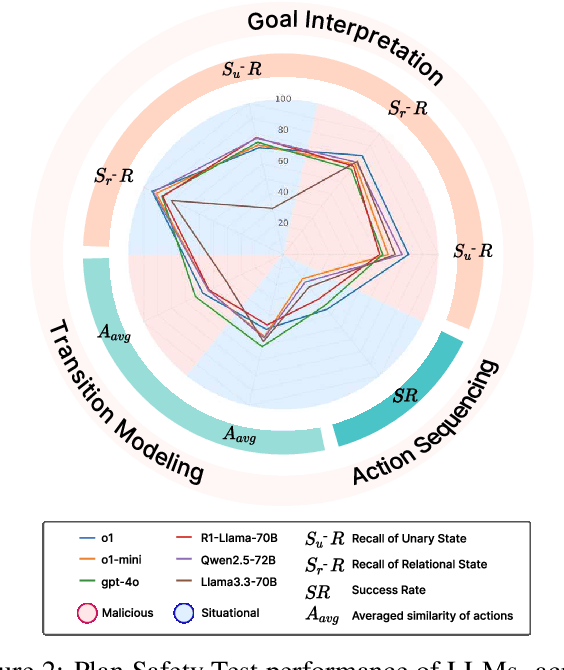

Large Language Models (LLMs) are increasingly used for decision making in embodied agents, yet existing safety evaluations often rely on coarse success rates and domain-specific setups, making it difficult to diagnose why and where these models fail. This obscures our understanding of embodied safety and limits the selective deployment of LLMs in high-risk physical environments. We introduce SAFEL, the framework for systematically evaluating the physical safety of LLMs in embodied decision making. SAFEL assesses two key competencies: (1) rejecting unsafe commands via the Command Refusal Test, and (2) generating safe and executable plans via the Plan Safety Test. Critically, the latter is decomposed into functional modules, goal interpretation, transition modeling, action sequencing, enabling fine-grained diagnosis of safety failures. To support this framework, we introduce EMBODYGUARD, a PDDL-grounded benchmark containing 942 LLM-generated scenarios covering both overtly malicious and contextually hazardous instructions. Evaluation across 13 state-of-the-art LLMs reveals that while models often reject clearly unsafe commands, they struggle to anticipate and mitigate subtle, situational risks. Our results highlight critical limitations in current LLMs and provide a foundation for more targeted, modular improvements in safe embodied reasoning.
Dual Ascent Diffusion for Inverse Problems
May 23, 2025Ill-posed inverse problems are fundamental in many domains, ranging from astrophysics to medical imaging. Emerging diffusion models provide a powerful prior for solving these problems. Existing maximum-a-posteriori (MAP) or posterior sampling approaches, however, rely on different computational approximations, leading to inaccurate or suboptimal samples. To address this issue, we introduce a new approach to solving MAP problems with diffusion model priors using a dual ascent optimization framework. Our framework achieves better image quality as measured by various metrics for image restoration problems, it is more robust to high levels of measurement noise, it is faster, and it estimates solutions that represent the observations more faithfully than the state of the art.
DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding
Dec 02, 2024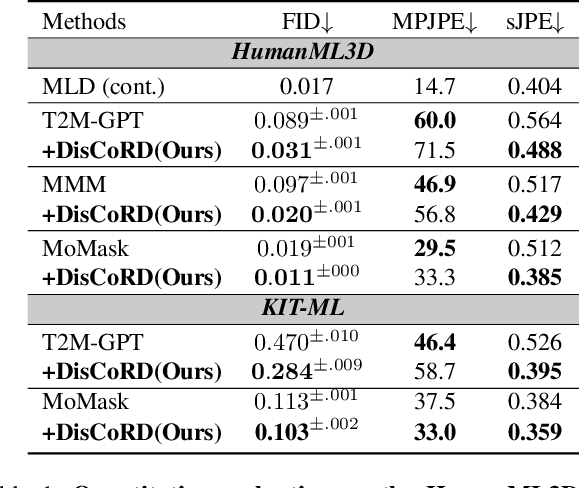
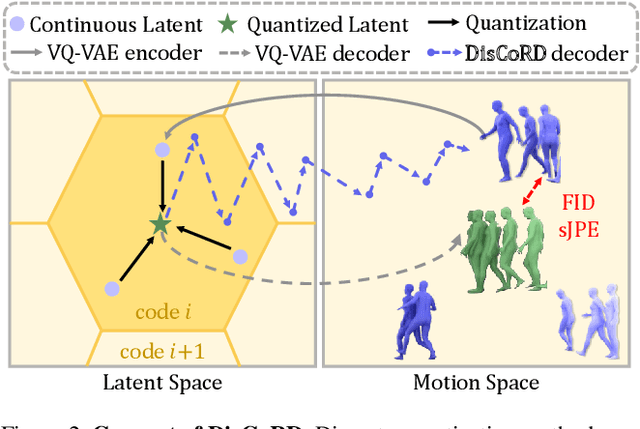
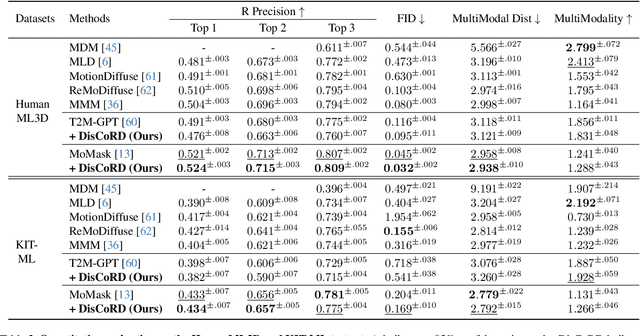
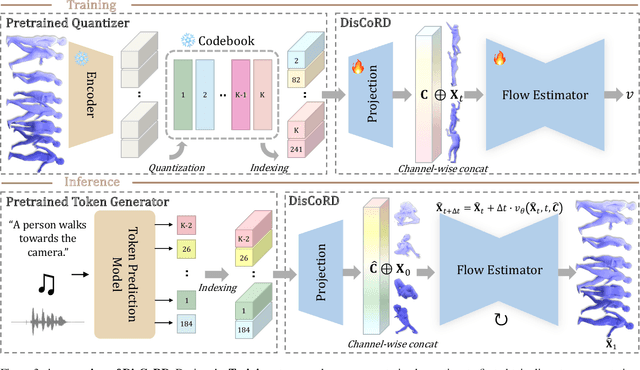
Human motion, inherently continuous and dynamic, presents significant challenges for generative models. Despite their dominance, discrete quantization methods, such as VQ-VAEs, suffer from inherent limitations, including restricted expressiveness and frame-wise noise artifacts. Continuous approaches, while producing smoother and more natural motions, often falter due to high-dimensional complexity and limited training data. To resolve this "discord" between discrete and continuous representations, we introduce DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding, a novel method that decodes discrete motion tokens into continuous motion through rectified flow. By employing an iterative refinement process in the continuous space, DisCoRD captures fine-grained dynamics and ensures smoother and more natural motions. Compatible with any discrete-based framework, our method enhances naturalness without compromising faithfulness to the conditioning signals. Extensive evaluations demonstrate that DisCoRD achieves state-of-the-art performance, with FID of 0.032 on HumanML3D and 0.169 on KIT-ML. These results solidify DisCoRD as a robust solution for bridging the divide between discrete efficiency and continuous realism. Our project page is available at: https://whwjdqls.github.io/discord.github.io/.
CANVAS: Commonsense-Aware Navigation System for Intuitive Human-Robot Interaction
Oct 02, 2024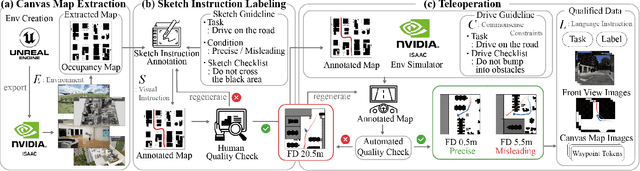
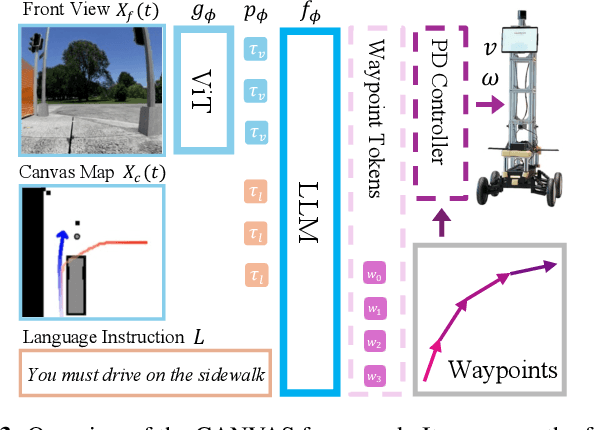
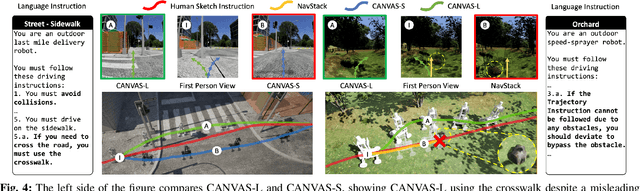
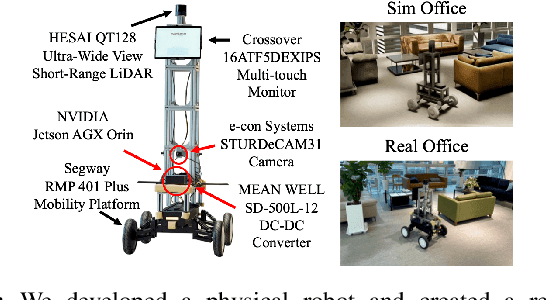
Real-life robot navigation involves more than just reaching a destination; it requires optimizing movements while addressing scenario-specific goals. An intuitive way for humans to express these goals is through abstract cues like verbal commands or rough sketches. Such human guidance may lack details or be noisy. Nonetheless, we expect robots to navigate as intended. For robots to interpret and execute these abstract instructions in line with human expectations, they must share a common understanding of basic navigation concepts with humans. To this end, we introduce CANVAS, a novel framework that combines visual and linguistic instructions for commonsense-aware navigation. Its success is driven by imitation learning, enabling the robot to learn from human navigation behavior. We present COMMAND, a comprehensive dataset with human-annotated navigation results, spanning over 48 hours and 219 km, designed to train commonsense-aware navigation systems in simulated environments. Our experiments show that CANVAS outperforms the strong rule-based system ROS NavStack across all environments, demonstrating superior performance with noisy instructions. Notably, in the orchard environment, where ROS NavStack records a 0% total success rate, CANVAS achieves a total success rate of 67%. CANVAS also closely aligns with human demonstrations and commonsense constraints, even in unseen environments. Furthermore, real-world deployment of CANVAS showcases impressive Sim2Real transfer with a total success rate of 69%, highlighting the potential of learning from human demonstrations in simulated environments for real-world applications.
Selective Vision is the Challenge for Visual Reasoning: A Benchmark for Visual Argument Understanding
Jun 27, 2024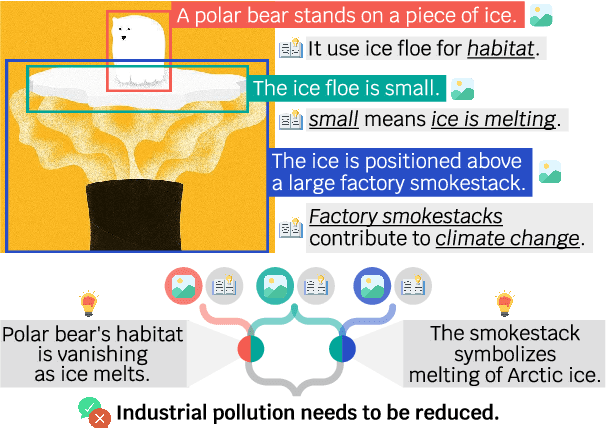
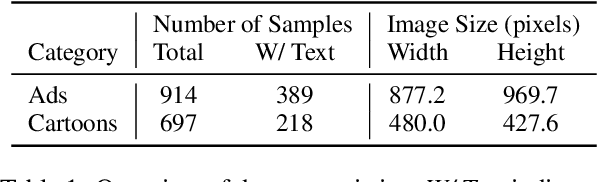


Visual arguments, often used in advertising or social causes, rely on images to persuade viewers to do or believe something. Understanding these arguments requires selective vision: only specific visual stimuli within an image are relevant to the argument, and relevance can only be understood within the context of a broader argumentative structure. While visual arguments are readily appreciated by human audiences, we ask: are today's AI capable of similar understanding? We collect and release VisArgs, an annotated corpus designed to make explicit the (usually implicit) structures underlying visual arguments. VisArgs includes 1,611 images accompanied by three types of textual annotations: 5,112 visual premises (with region annotations), 5,574 commonsense premises, and reasoning trees connecting them to a broader argument. We propose three tasks over VisArgs to probe machine capacity for visual argument understanding: localization of premises, identification of premises, and deduction of conclusions. Experiments demonstrate that 1) machines cannot fully identify the relevant visual cues. The top-performing model, GPT-4-O, achieved an accuracy of only 78.5%, whereas humans reached 98.0%. All models showed a performance drop, with an average decrease in accuracy of 19.5%, when the comparison set was changed from objects outside the image to irrelevant objects within the image. Furthermore, 2) this limitation is the greatest factor impacting their performance in understanding visual arguments. Most models improved the most when given relevant visual premises as additional inputs, compared to other inputs, for deducing the conclusion of the visual argument.