 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Residual Connections: Orthogonal Updates for Stable and Efficient Deep Networks
May 17, 2025Residual connections are pivotal for deep neural networks, enabling greater depth by mitigating vanishing gradients. However, in standard residual updates, the module's output is directly added to the input stream. This can lead to updates that predominantly reinforce or modulate the existing stream direction, potentially underutilizing the module's capacity for learning entirely novel features. In this work, we introduce Orthogonal Residual Update: we decompose the module's output relative to the input stream and add only the component orthogonal to this stream. This design aims to guide modules to contribute primarily new representational directions, fostering richer feature learning while promoting more efficient training. We demonstrate that our orthogonal update strategy improves generalization accuracy and training stability across diverse architectures (ResNetV2, Vision Transformers) and datasets (CIFARs, TinyImageNet, ImageNet-1k), achieving, for instance, a +4.3\%p top-1 accuracy gain for ViT-B on ImageNet-1k.
An Analysis of Model Robustness across Concurrent Distribution Shifts
Jan 08, 2025Machine learning models, meticulously optimized for source data, often fail to predict target data when faced with distribution shifts (DSs). Previous benchmarking studies, though extensive, have mainly focused on simple DSs. Recognizing that DSs often occur in more complex forms in real-world scenarios, we broadened our study to include multiple concurrent shifts, such as unseen domain shifts combined with spurious correlations. We evaluated 26 algorithms that range from simple heuristic augmentations to zero-shot inference using foundation models, across 168 source-target pairs from eight datasets. Our analysis of over 100K models reveals that (i) concurrent DSs typically worsen performance compared to a single shift, with certain exceptions, (ii) if a model improves generalization for one distribution shift, it tends to be effective for others, and (iii) heuristic data augmentations achieve the best overall performance on both synthetic and real-world datasets.
MMVA: Multimodal Matching Based on Valence and Arousal across Images, Music, and Musical Captions
Jan 02, 2025



We introduce Multimodal Matching based on Valence and Arousal (MMVA), a tri-modal encoder framework designed to capture emotional content across images, music, and musical captions. To support this framework, we expand the Image-Music-Emotion-Matching-Net (IMEMNet) dataset, creating IMEMNet-C which includes 24,756 images and 25,944 music clips with corresponding musical captions. We employ multimodal matching scores based on the continuous valence (emotional positivity) and arousal (emotional intensity) values. This continuous matching score allows for random sampling of image-music pairs during training by computing similarity scores from the valence-arousal values across different modalities. Consequently, the proposed approach achieves state-of-the-art performance in valence-arousal prediction tasks. Furthermore, the framework demonstrates its efficacy in various zeroshot tasks, highlighting the potential of valence and arousal predictions in downstream applications.
CANVAS: Commonsense-Aware Navigation System for Intuitive Human-Robot Interaction
Oct 02, 2024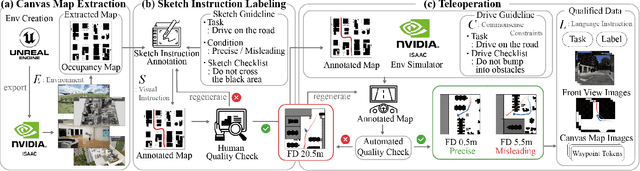
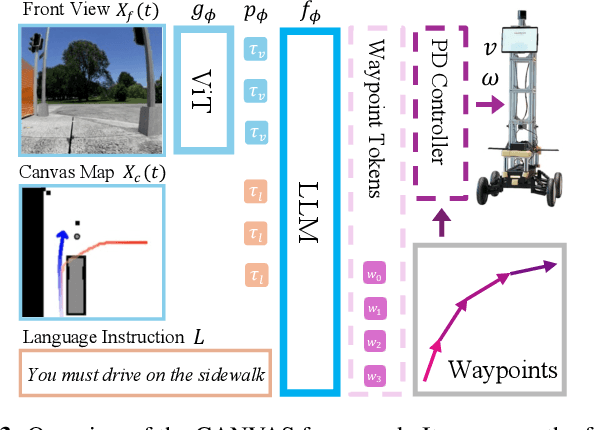
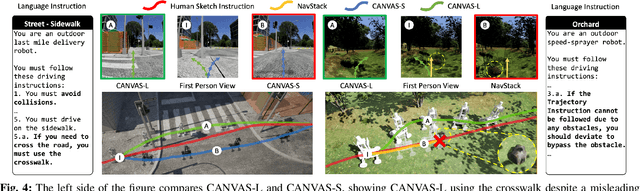
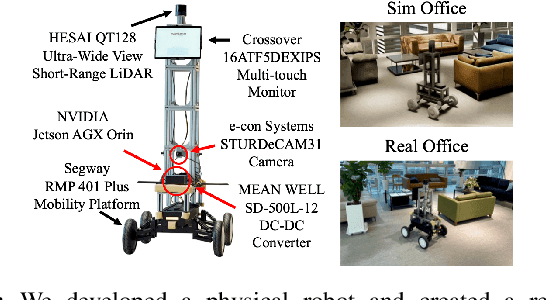
Real-life robot navigation involves more than just reaching a destination; it requires optimizing movements while addressing scenario-specific goals. An intuitive way for humans to express these goals is through abstract cues like verbal commands or rough sketches. Such human guidance may lack details or be noisy. Nonetheless, we expect robots to navigate as intended. For robots to interpret and execute these abstract instructions in line with human expectations, they must share a common understanding of basic navigation concepts with humans. To this end, we introduce CANVAS, a novel framework that combines visual and linguistic instructions for commonsense-aware navigation. Its success is driven by imitation learning, enabling the robot to learn from human navigation behavior. We present COMMAND, a comprehensive dataset with human-annotated navigation results, spanning over 48 hours and 219 km, designed to train commonsense-aware navigation systems in simulated environments. Our experiments show that CANVAS outperforms the strong rule-based system ROS NavStack across all environments, demonstrating superior performance with noisy instructions. Notably, in the orchard environment, where ROS NavStack records a 0% total success rate, CANVAS achieves a total success rate of 67%. CANVAS also closely aligns with human demonstrations and commonsense constraints, even in unseen environments. Furthermore, real-world deployment of CANVAS showcases impressive Sim2Real transfer with a total success rate of 69%, highlighting the potential of learning from human demonstrations in simulated environments for real-world applications.
Exploiting Semantic Reconstruction to Mitigate Hallucinations in Vision-Language Models
Mar 26, 2024Hallucinations in vision-language models pose a significant challenge to their reliability, particularly in the generation of long captions. Current methods fall short of accurately identifying and mitigating these hallucinations. To address this issue, we introduce ESREAL, a novel unsupervised learning framework designed to suppress the generation of hallucinations through accurate localization and penalization of hallucinated tokens. Initially, ESREAL creates a reconstructed image based on the generated caption and aligns its corresponding regions with those of the original image. This semantic reconstruction aids in identifying both the presence and type of token-level hallucinations within the generated caption. Subsequently, ESREAL computes token-level hallucination scores by assessing the semantic similarity of aligned regions based on the type of hallucination. Finally, ESREAL employs a proximal policy optimization algorithm, where it selectively penalizes hallucinated tokens according to their token-level hallucination scores. Our framework notably reduces hallucinations in LLaVA, InstructBLIP, and mPLUG-Owl2 by 32.81%, 27.08%, and 7.46% on the CHAIR metric. This improvement is achieved solely through signals derived from the image itself, without the need for any image-text pairs.