 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Problem Generation via Symbolic Representations
Feb 22, 2026We present a method for generating training data for reinforcement learning with verifiable rewards to improve small open-weights language models on mathematical tasks. Existing data generation approaches rely on open-loop pipelines and fixed modifications that do not adapt to the model's capabilities. Furthermore, they typically operate directly on word problems, limiting control over problem structure. To address this, we perform modifications in a symbolic problem space, representing each problem as a set of symbolic variables and constraints (e.g., via algebraic frameworks such as SymPy or SMT formulations). This representation enables precise control over problem structure, automatic generation of ground-truth solutions, and decouples mathematical reasoning from linguistic realization. We also show that this results in more diverse generations. To adapt the problem difficulty to the model, we introduce a closed-loop framework that learns modification strategies through prompt optimization in symbolic space. Experimental results demonstrate that both adaptive problem generation and symbolic representation modifications contribute to improving the model's math solving ability.
Towards Adaptive Environment Generation for Training Embodied Agents
Feb 06, 2026Embodied agents struggle to generalize to new environments, even when those environments share similar underlying structures to their training settings. Most current approaches to generating these training environments follow an open-loop paradigm, without considering the agent's current performance. While procedural generation methods can produce diverse scenes, diversity without feedback from the agent is inefficient. The generated environments may be trivially easy, providing limited learning signal. To address this, we present a proof-of-concept for closed-loop environment generation that adapts difficulty to the agent's current capabilities. Our system employs a controllable environment representation, extracts fine-grained performance feedback beyond binary success or failure, and implements a closed-loop adaptation mechanism that translates this feedback into environment modifications. This feedback-driven approach generates training environments that more challenging in the ways the agent needs to improve, enabling more efficient learning and better generalization to novel settings.
An Analysis of Model Robustness across Concurrent Distribution Shifts
Jan 08, 2025


Machine learning models, meticulously optimized for source data, often fail to predict target data when faced with distribution shifts (DSs). Previous benchmarking studies, though extensive, have mainly focused on simple DSs. Recognizing that DSs often occur in more complex forms in real-world scenarios, we broadened our study to include multiple concurrent shifts, such as unseen domain shifts combined with spurious correlations. We evaluated 26 algorithms that range from simple heuristic augmentations to zero-shot inference using foundation models, across 168 source-target pairs from eight datasets. Our analysis of over 100K models reveals that (i) concurrent DSs typically worsen performance compared to a single shift, with certain exceptions, (ii) if a model improves generalization for one distribution shift, it tends to be effective for others, and (iii) heuristic data augmentations achieve the best overall performance on both synthetic and real-world datasets.
ViPer: Visual Personalization of Generative Models via Individual Preference Learning
Jul 24, 2024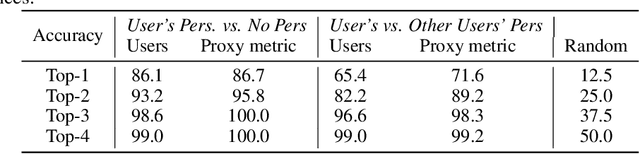
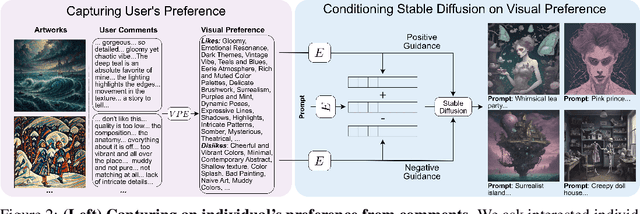
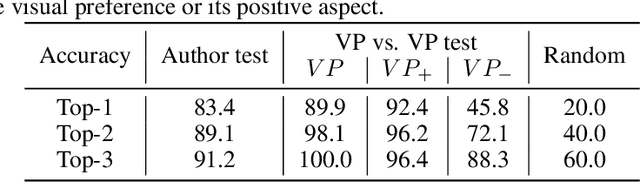
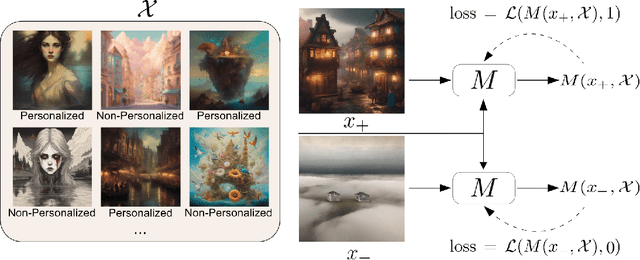
Different users find different images generated for the same prompt desirable. This gives rise to personalized image generation which involves creating images aligned with an individual's visual preference. Current generative models are, however, unpersonalized, as they are tuned to produce outputs that appeal to a broad audience. Using them to generate images aligned with individual users relies on iterative manual prompt engineering by the user which is inefficient and undesirable. We propose to personalize the image generation process by first capturing the generic preferences of the user in a one-time process by inviting them to comment on a small selection of images, explaining why they like or dislike each. Based on these comments, we infer a user's structured liked and disliked visual attributes, i.e., their visual preference, using a large language model. These attributes are used to guide a text-to-image model toward producing images that are tuned towards the individual user's visual preference. Through a series of user studies and large language model guided evaluations, we demonstrate that the proposed method results in generations that are well aligned with individual users' visual preferences.
Controlled Training Data Generation with Diffusion Models
Mar 22, 2024In this work, we present a method to control a text-to-image generative model to produce training data specifically "useful" for supervised learning. Unlike previous works that employ an open-loop approach and pre-define prompts to generate new data using either a language model or human expertise, we develop an automated closed-loop system which involves two feedback mechanisms. The first mechanism uses feedback from a given supervised model and finds adversarial prompts that result in image generations that maximize the model loss. While these adversarial prompts result in diverse data informed by the model, they are not informed of the target distribution, which can be inefficient. Therefore, we introduce the second feedback mechanism that guides the generation process towards a certain target distribution. We call the method combining these two mechanisms Guided Adversarial Prompts. We perform our evaluations on different tasks, datasets and architectures, with different types of distribution shifts (spuriously correlated data, unseen domains) and demonstrate the efficiency of the proposed feedback mechanisms compared to open-loop approaches.
4M: Massively Multimodal Masked Modeling
Dec 11, 2023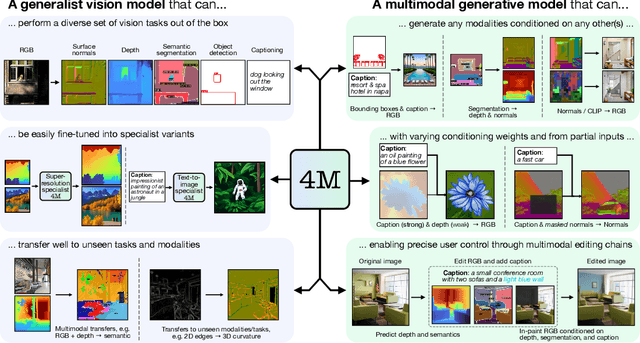

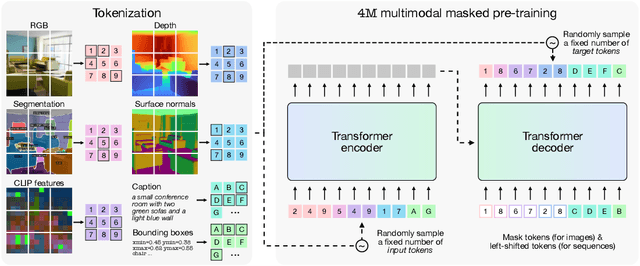

Current machine learning models for vision are often highly specialized and limited to a single modality and task. In contrast, recent large language models exhibit a wide range of capabilities, hinting at a possibility for similarly versatile models in computer vision. In this paper, we take a step in this direction and propose a multimodal training scheme called 4M. It consists of training a single unified Transformer encoder-decoder using a masked modeling objective across a wide range of input/output modalities - including text, images, geometric, and semantic modalities, as well as neural network feature maps. 4M achieves scalability by unifying the representation space of all modalities through mapping them into discrete tokens and performing multimodal masked modeling on a small randomized subset of tokens. 4M leads to models that exhibit several key capabilities: (1) they can perform a diverse set of vision tasks out of the box, (2) they excel when fine-tuned for unseen downstream tasks or new input modalities, and (3) they can function as a generative model that can be conditioned on arbitrary modalities, enabling a wide variety of expressive multimodal editing capabilities with remarkable flexibility. Through experimental analyses, we demonstrate the potential of 4M for training versatile and scalable foundation models for vision tasks, setting the stage for further exploration in multimodal learning for vision and other domains.
Rapid Network Adaptation: Learning to Adapt Neural Networks Using Test-Time Feedback
Sep 27, 2023We propose a method for adapting neural networks to distribution shifts at test-time. In contrast to training-time robustness mechanisms that attempt to anticipate and counter the shift, we create a closed-loop system and make use of a test-time feedback signal to adapt a network on the fly. We show that this loop can be effectively implemented using a learning-based function, which realizes an amortized optimizer for the network. This leads to an adaptation method, named Rapid Network Adaptation (RNA), that is notably more flexible and orders of magnitude faster than the baselines. Through a broad set of experiments using various adaptation signals and target tasks, we study the efficiency and flexibility of this method. We perform the evaluations using various datasets (Taskonomy, Replica, ScanNet, Hypersim, COCO, ImageNet), tasks (depth, optical flow, semantic segmentation, classification), and distribution shifts (Cross-datasets, 2D and 3D Common Corruptions) with promising results. We end with a discussion on general formulations for handling distribution shifts and our observations from comparing with similar approaches from other domains.
Task Discovery: Finding the Tasks that Neural Networks Generalize on
Dec 01, 2022



When developing deep learning models, we usually decide what task we want to solve then search for a model that generalizes well on the task. An intriguing question would be: what if, instead of fixing the task and searching in the model space, we fix the model and search in the task space? Can we find tasks that the model generalizes on? How do they look, or do they indicate anything? These are the questions we address in this paper. We propose a task discovery framework that automatically finds examples of such tasks via optimizing a generalization-based quantity called agreement score. We demonstrate that one set of images can give rise to many tasks on which neural networks generalize well. These tasks are a reflection of the inductive biases of the learning framework and the statistical patterns present in the data, thus they can make a useful tool for analysing the neural networks and their biases. As an example, we show that the discovered tasks can be used to automatically create adversarial train-test splits which make a model fail at test time, without changing the pixels or labels, but by only selecting how the datapoints should be split between the train and test sets. We end with a discussion on human-interpretability of the discovered tasks.
3D Common Corruptions and Data Augmentation
Apr 04, 2022
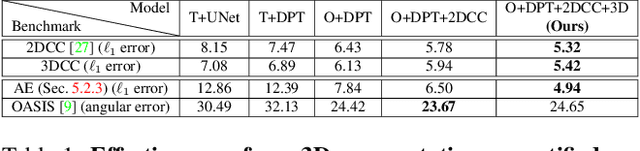

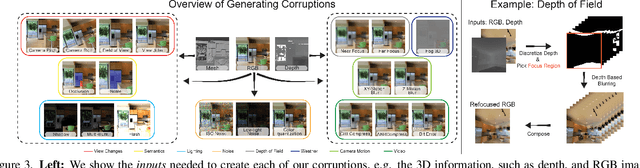
We introduce a set of image transformations that can be used as corruptions to evaluate the robustness of models as well as data augmentation mechanisms for training neural networks. The primary distinction of the proposed transformations is that, unlike existing approaches such as Common Corruptions, the geometry of the scene is incorporated in the transformations -- thus leading to corruptions that are more likely to occur in the real world. We also introduce a set of semantic corruptions (e.g. natural object occlusions). We show these transformations are `efficient' (can be computed on-the-fly), `extendable' (can be applied on most image datasets), expose vulnerability of existing models, and can effectively make models more robust when employed as `3D data augmentation' mechanisms. The evaluations on several tasks and datasets suggest incorporating 3D information into benchmarking and training opens up a promising direction for robustness research.
Robustness via Cross-Domain Ensembles
Mar 19, 2021
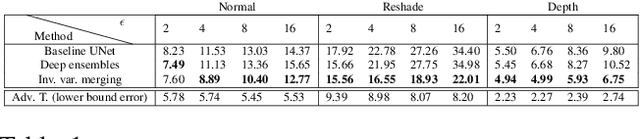


We present a method for making neural network predictions robust to shifts from the training data distribution. The proposed method is based on making predictions via a diverse set of cues (called 'middle domains') and ensembling them into one strong prediction. The premise of the idea is that predictions made via different cues respond differently to a distribution shift, hence one should be able to merge them into one robust final prediction. We perform the merging in a straightforward but principled manner based on the uncertainty associated with each prediction. The evaluations are performed using multiple tasks and datasets (Taskonomy, Replica, ImageNet, CIFAR) under a wide range of adversarial and non-adversarial distribution shifts which demonstrate the proposed method is considerably more robust than its standard learning counterpart, conventional deep ensembles, and several other baselines.