 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoFlexTok: Flexible-Length Coarse-to-Fine Video Tokenization
Apr 14, 2026Visual tokenizers map high-dimensional raw pixels into a compressed representation for downstream modeling. Beyond compression, tokenizers dictate what information is preserved and how it is organized. A de facto standard approach to video tokenization is to represent a video as a spatiotemporal 3D grid of tokens, each capturing the corresponding local information in the original signal. This requires the downstream model that consumes the tokens, e.g., a text-to-video model, to learn to predict all low-level details "pixel-by-pixel" irrespective of the video's inherent complexity, leading to high learning complexity. We present VideoFlexTok, which represents videos with a variable-length sequence of tokens structured in a coarse-to-fine manner -- where the first tokens (emergently) capture abstract information, such as semantics and motion, and later tokens add fine-grained details. The generative flow decoder enables realistic video reconstructions from any token count. This representation structure allows adapting the token count according to downstream needs and encoding videos longer than the baselines with the same budget. We evaluate VideoFlexTok on class- and text-to-video generative tasks and show that it leads to more efficient training compared to 3D grid tokens, e.g., achieving comparable generation quality (gFVD and ViCLIP Score) with a 5x smaller model (1.1B vs 5.2B). Finally, we demonstrate how VideoFlexTok can enable long video generation without prohibitive computational cost by training a text-to-video model on 10-second 81-frame videos with only 672 tokens, 8x fewer than a comparable 3D grid tokenizer.
How Well Does GPT-4o Understand Vision? Evaluating Multimodal Foundation Models on Standard Computer Vision Tasks
Jul 02, 2025Multimodal foundation models, such as GPT-4o, have recently made remarkable progress, but it is not clear where exactly these models stand in terms of understanding vision. In this paper, we benchmark the performance of popular multimodal foundation models (GPT-4o, o4-mini, Gemini 1.5 Pro and Gemini 2.0 Flash, Claude 3.5 Sonnet, Qwen2-VL, Llama 3.2) on standard computer vision tasks (semantic segmentation, object detection, image classification, depth and surface normal prediction) using established datasets (e.g., COCO, ImageNet and its variants, etc). The main challenges to performing this are: 1) most models are trained to output text and cannot natively express versatile domains, such as segments or 3D geometry, and 2) many leading models are proprietary and accessible only at an API level, i.e., there is no weight access to adapt them. We address these challenges by translating standard vision tasks into equivalent text-promptable and API-compatible tasks via prompt chaining to create a standardized benchmarking framework. We observe that 1) the models are not close to the state-of-the-art specialist models at any task. However, 2) they are respectable generalists; this is remarkable as they are presumably trained on primarily image-text-based tasks. 3) They perform semantic tasks notably better than geometric ones. 4) While the prompt-chaining techniques affect performance, better models exhibit less sensitivity to prompt variations. 5) GPT-4o performs the best among non-reasoning models, securing the top position in 4 out of 6 tasks, 6) reasoning models, e.g. o3, show improvements in geometric tasks, and 7) a preliminary analysis of models with native image generation, like the latest GPT-4o, shows they exhibit quirks like hallucinations and spatial misalignments.
FlexTok: Resampling Images into 1D Token Sequences of Flexible Length
Feb 19, 2025Image tokenization has enabled major advances in autoregressive image generation by providing compressed, discrete representations that are more efficient to process than raw pixels. While traditional approaches use 2D grid tokenization, recent methods like TiTok have shown that 1D tokenization can achieve high generation quality by eliminating grid redundancies. However, these methods typically use a fixed number of tokens and thus cannot adapt to an image's inherent complexity. We introduce FlexTok, a tokenizer that projects 2D images into variable-length, ordered 1D token sequences. For example, a 256x256 image can be resampled into anywhere from 1 to 256 discrete tokens, hierarchically and semantically compressing its information. By training a rectified flow model as the decoder and using nested dropout, FlexTok produces plausible reconstructions regardless of the chosen token sequence length. We evaluate our approach in an autoregressive generation setting using a simple GPT-style Transformer. On ImageNet, this approach achieves an FID<2 across 8 to 128 tokens, outperforming TiTok and matching state-of-the-art methods with far fewer tokens. We further extend the model to support to text-conditioned image generation and examine how FlexTok relates to traditional 2D tokenization. A key finding is that FlexTok enables next-token prediction to describe images in a coarse-to-fine "visual vocabulary", and that the number of tokens to generate depends on the complexity of the generation task.
4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities
Jun 14, 2024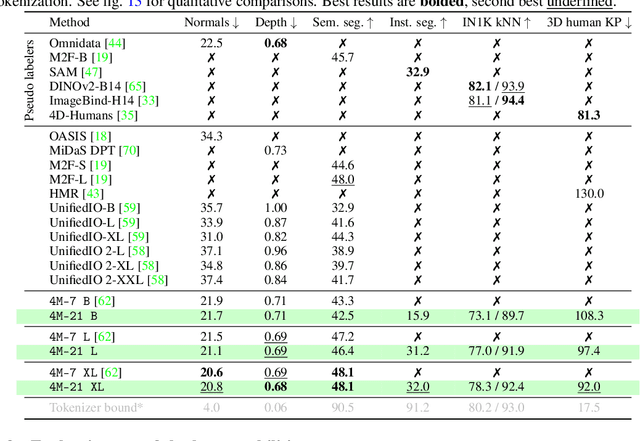

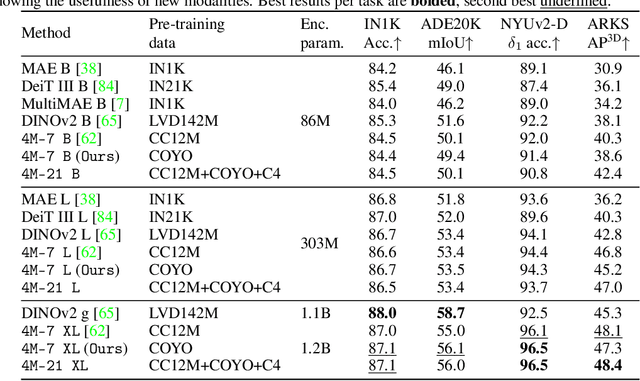
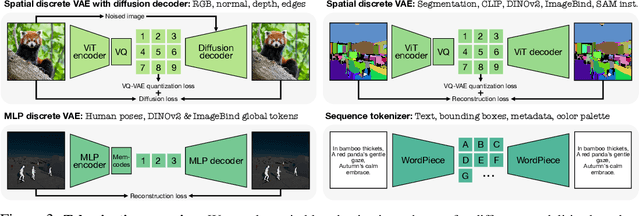
Current multimodal and multitask foundation models like 4M or UnifiedIO show promising results, but in practice their out-of-the-box abilities to accept diverse inputs and perform diverse tasks are limited by the (usually rather small) number of modalities and tasks they are trained on. In this paper, we expand upon the capabilities of them by training a single model on tens of highly diverse modalities and by performing co-training on large-scale multimodal datasets and text corpora. This includes training on several semantic and geometric modalities, feature maps from recent state of the art models like DINOv2 and ImageBind, pseudo labels of specialist models like SAM and 4DHumans, and a range of new modalities that allow for novel ways to interact with the model and steer the generation, for example image metadata or color palettes. A crucial step in this process is performing discrete tokenization on various modalities, whether they are image-like, neural network feature maps, vectors, structured data like instance segmentation or human poses, or data that can be represented as text. Through this, we expand on the out-of-the-box capabilities of multimodal models and specifically show the possibility of training one model to solve at least 3x more tasks/modalities than existing ones and doing so without a loss in performance. This enables more fine-grained and controllable multimodal generation capabilities and allows us to study the distillation of models trained on diverse data and objectives into a unified model. We successfully scale the training to a three billion parameter model using tens of modalities and different datasets. The resulting models and training code are open sourced at 4m.epfl.ch.
BRAVE: Broadening the visual encoding of vision-language models
Apr 10, 2024Vision-language models (VLMs) are typically composed of a vision encoder, e.g. CLIP, and a language model (LM) that interprets the encoded features to solve downstream tasks. Despite remarkable progress, VLMs are subject to several shortcomings due to the limited capabilities of vision encoders, e.g. "blindness" to certain image features, visual hallucination, etc. To address these issues, we study broadening the visual encoding capabilities of VLMs. We first comprehensively benchmark several vision encoders with different inductive biases for solving VLM tasks. We observe that there is no single encoding configuration that consistently achieves top performance across different tasks, and encoders with different biases can perform surprisingly similarly. Motivated by this, we introduce a method, named BRAVE, that consolidates features from multiple frozen encoders into a more versatile representation that can be directly fed as the input to a frozen LM. BRAVE achieves state-of-the-art performance on a broad range of captioning and VQA benchmarks and significantly reduces the aforementioned issues of VLMs, while requiring a smaller number of trainable parameters than existing methods and having a more compressed representation. Our results highlight the potential of incorporating different visual biases for a more broad and contextualized visual understanding of VLMs.
Unraveling the Key Components of OOD Generalization via Diversification
Dec 26, 2023Real-world datasets may contain multiple features that explain the training data equally well, i.e., learning any of them would lead to correct predictions on the training data. However, many of them can be spurious, i.e., lose their predictive power under a distribution shift and fail to generalize to out-of-distribution (OOD) data. Recently developed ``diversification'' methods approach this problem by finding multiple diverse hypotheses that rely on different features. This paper aims to study this class of methods and identify the key components contributing to their OOD generalization abilities. We show that (1) diversification methods are highly sensitive to the distribution of the unlabeled data used for diversification and can underperform significantly when away from a method-specific sweet spot. (2) Diversification alone is insufficient for OOD generalization. The choice of the used learning algorithm, e.g., the model's architecture and pretraining, is crucial, and using the second-best choice leads to an up to 20% absolute drop in accuracy.(3) The optimal choice of learning algorithm depends on the unlabeled data, and vice versa.Finally, we show that the above pitfalls cannot be alleviated by increasing the number of diverse hypotheses, allegedly the major feature of diversification methods. These findings provide a clearer understanding of the critical design factors influencing the OOD generalization of diversification methods. They can guide practitioners in how to use the existing methods best and guide researchers in developing new, better ones.
4M: Massively Multimodal Masked Modeling
Dec 11, 2023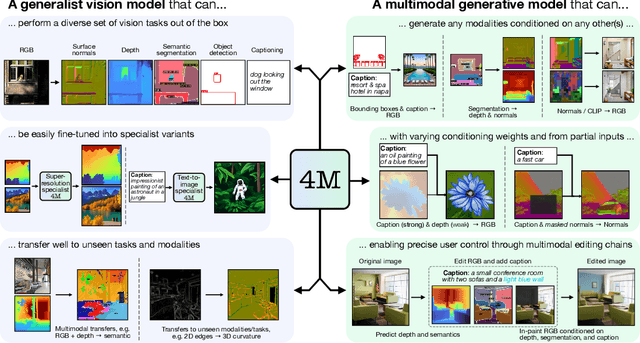

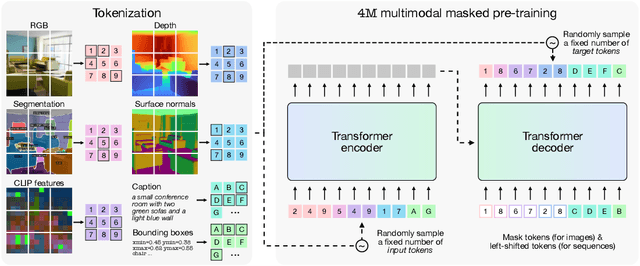

Current machine learning models for vision are often highly specialized and limited to a single modality and task. In contrast, recent large language models exhibit a wide range of capabilities, hinting at a possibility for similarly versatile models in computer vision. In this paper, we take a step in this direction and propose a multimodal training scheme called 4M. It consists of training a single unified Transformer encoder-decoder using a masked modeling objective across a wide range of input/output modalities - including text, images, geometric, and semantic modalities, as well as neural network feature maps. 4M achieves scalability by unifying the representation space of all modalities through mapping them into discrete tokens and performing multimodal masked modeling on a small randomized subset of tokens. 4M leads to models that exhibit several key capabilities: (1) they can perform a diverse set of vision tasks out of the box, (2) they excel when fine-tuned for unseen downstream tasks or new input modalities, and (3) they can function as a generative model that can be conditioned on arbitrary modalities, enabling a wide variety of expressive multimodal editing capabilities with remarkable flexibility. Through experimental analyses, we demonstrate the potential of 4M for training versatile and scalable foundation models for vision tasks, setting the stage for further exploration in multimodal learning for vision and other domains.
Rapid Network Adaptation: Learning to Adapt Neural Networks Using Test-Time Feedback
Sep 27, 2023We propose a method for adapting neural networks to distribution shifts at test-time. In contrast to training-time robustness mechanisms that attempt to anticipate and counter the shift, we create a closed-loop system and make use of a test-time feedback signal to adapt a network on the fly. We show that this loop can be effectively implemented using a learning-based function, which realizes an amortized optimizer for the network. This leads to an adaptation method, named Rapid Network Adaptation (RNA), that is notably more flexible and orders of magnitude faster than the baselines. Through a broad set of experiments using various adaptation signals and target tasks, we study the efficiency and flexibility of this method. We perform the evaluations using various datasets (Taskonomy, Replica, ScanNet, Hypersim, COCO, ImageNet), tasks (depth, optical flow, semantic segmentation, classification), and distribution shifts (Cross-datasets, 2D and 3D Common Corruptions) with promising results. We end with a discussion on general formulations for handling distribution shifts and our observations from comparing with similar approaches from other domains.
3D Common Corruptions and Data Augmentation
Apr 04, 2022
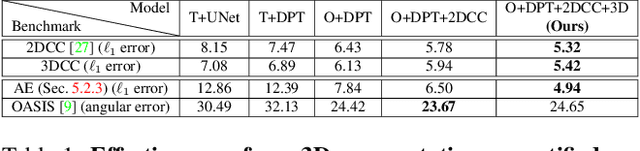

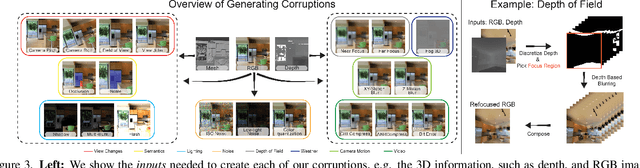
We introduce a set of image transformations that can be used as corruptions to evaluate the robustness of models as well as data augmentation mechanisms for training neural networks. The primary distinction of the proposed transformations is that, unlike existing approaches such as Common Corruptions, the geometry of the scene is incorporated in the transformations -- thus leading to corruptions that are more likely to occur in the real world. We also introduce a set of semantic corruptions (e.g. natural object occlusions). We show these transformations are `efficient' (can be computed on-the-fly), `extendable' (can be applied on most image datasets), expose vulnerability of existing models, and can effectively make models more robust when employed as `3D data augmentation' mechanisms. The evaluations on several tasks and datasets suggest incorporating 3D information into benchmarking and training opens up a promising direction for robustness research.
Robustness via Cross-Domain Ensembles
Mar 19, 2021
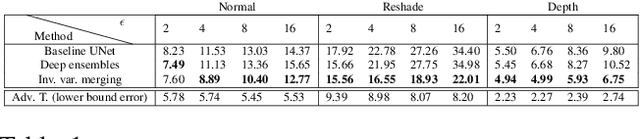


We present a method for making neural network predictions robust to shifts from the training data distribution. The proposed method is based on making predictions via a diverse set of cues (called 'middle domains') and ensembling them into one strong prediction. The premise of the idea is that predictions made via different cues respond differently to a distribution shift, hence one should be able to merge them into one robust final prediction. We perform the merging in a straightforward but principled manner based on the uncertainty associated with each prediction. The evaluations are performed using multiple tasks and datasets (Taskonomy, Replica, ImageNet, CIFAR) under a wide range of adversarial and non-adversarial distribution shifts which demonstrate the proposed method is considerably more robust than its standard learning counterpart, conventional deep ensembles, and several other baselines.