 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Improve When Pretraining Data Matches Target Tasks
Jul 16, 2025Every data selection method inherently has a target. In practice, these targets often emerge implicitly through benchmark-driven iteration: researchers develop selection strategies, train models, measure benchmark performance, then refine accordingly. This raises a natural question: what happens when we make this optimization explicit? To explore this, we propose benchmark-targeted ranking (BETR), a simple method that selects pretraining documents based on similarity to benchmark training examples. BETR embeds benchmark examples and a sample of pretraining documents in a shared space, scores this sample by similarity to benchmarks, then trains a lightweight classifier to predict these scores for the full corpus. We compare data selection methods by training over 500 models spanning $10^{19}$ to $10^{22}$ FLOPs and fitting scaling laws to them. From this, we find that simply aligning pretraining data to evaluation benchmarks using BETR achieves a 2.1x compute multiplier over DCLM-Baseline (4.7x over unfiltered data) and improves performance on 9 out of 10 tasks across all scales. BETR also generalizes well: when targeting a diverse set of benchmarks disjoint from our evaluation suite, it still matches or outperforms baselines. Our scaling analysis further reveals a clear trend: larger models require less aggressive filtering. Overall, our findings show that directly matching pretraining data to target tasks precisely shapes model capabilities and highlight that optimal selection strategies must adapt to model scale.
FlexTok: Resampling Images into 1D Token Sequences of Flexible Length
Feb 19, 2025Image tokenization has enabled major advances in autoregressive image generation by providing compressed, discrete representations that are more efficient to process than raw pixels. While traditional approaches use 2D grid tokenization, recent methods like TiTok have shown that 1D tokenization can achieve high generation quality by eliminating grid redundancies. However, these methods typically use a fixed number of tokens and thus cannot adapt to an image's inherent complexity. We introduce FlexTok, a tokenizer that projects 2D images into variable-length, ordered 1D token sequences. For example, a 256x256 image can be resampled into anywhere from 1 to 256 discrete tokens, hierarchically and semantically compressing its information. By training a rectified flow model as the decoder and using nested dropout, FlexTok produces plausible reconstructions regardless of the chosen token sequence length. We evaluate our approach in an autoregressive generation setting using a simple GPT-style Transformer. On ImageNet, this approach achieves an FID<2 across 8 to 128 tokens, outperforming TiTok and matching state-of-the-art methods with far fewer tokens. We further extend the model to support to text-conditioned image generation and examine how FlexTok relates to traditional 2D tokenization. A key finding is that FlexTok enables next-token prediction to describe images in a coarse-to-fine "visual vocabulary", and that the number of tokens to generate depends on the complexity of the generation task.
4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities
Jun 14, 2024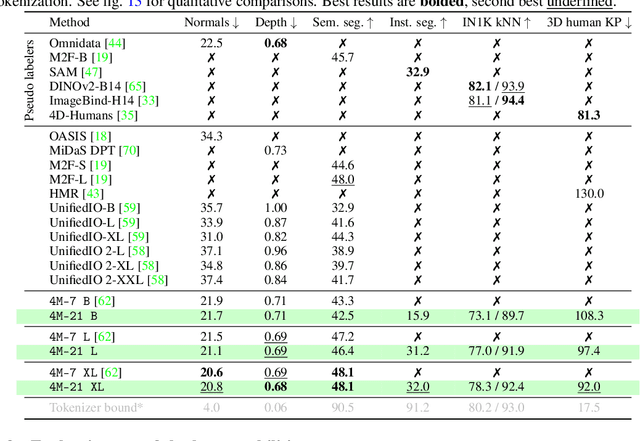

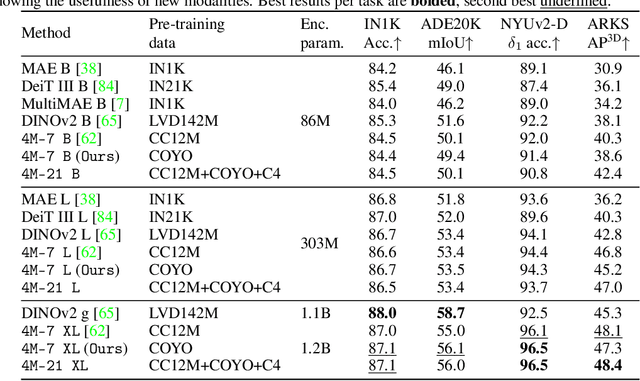
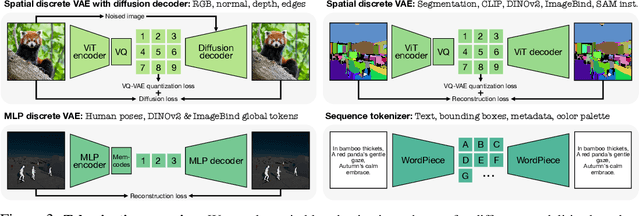
Current multimodal and multitask foundation models like 4M or UnifiedIO show promising results, but in practice their out-of-the-box abilities to accept diverse inputs and perform diverse tasks are limited by the (usually rather small) number of modalities and tasks they are trained on. In this paper, we expand upon the capabilities of them by training a single model on tens of highly diverse modalities and by performing co-training on large-scale multimodal datasets and text corpora. This includes training on several semantic and geometric modalities, feature maps from recent state of the art models like DINOv2 and ImageBind, pseudo labels of specialist models like SAM and 4DHumans, and a range of new modalities that allow for novel ways to interact with the model and steer the generation, for example image metadata or color palettes. A crucial step in this process is performing discrete tokenization on various modalities, whether they are image-like, neural network feature maps, vectors, structured data like instance segmentation or human poses, or data that can be represented as text. Through this, we expand on the out-of-the-box capabilities of multimodal models and specifically show the possibility of training one model to solve at least 3x more tasks/modalities than existing ones and doing so without a loss in performance. This enables more fine-grained and controllable multimodal generation capabilities and allows us to study the distillation of models trained on diverse data and objectives into a unified model. We successfully scale the training to a three billion parameter model using tens of modalities and different datasets. The resulting models and training code are open sourced at 4m.epfl.ch.
4M: Massively Multimodal Masked Modeling
Dec 11, 2023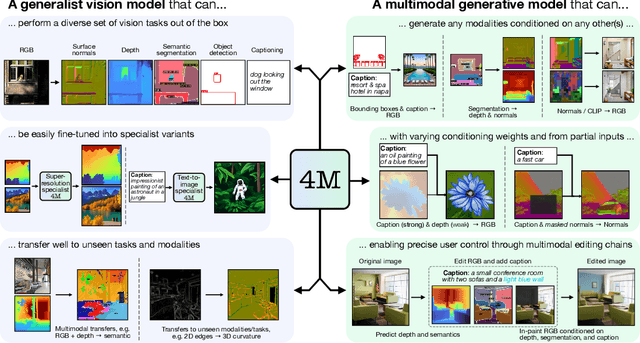

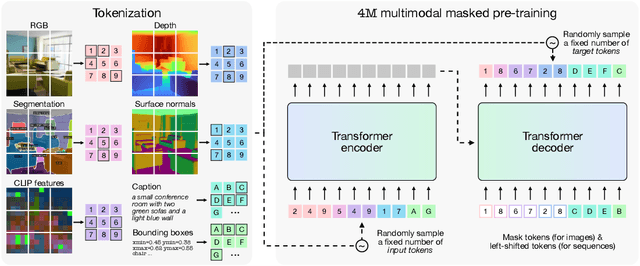

Current machine learning models for vision are often highly specialized and limited to a single modality and task. In contrast, recent large language models exhibit a wide range of capabilities, hinting at a possibility for similarly versatile models in computer vision. In this paper, we take a step in this direction and propose a multimodal training scheme called 4M. It consists of training a single unified Transformer encoder-decoder using a masked modeling objective across a wide range of input/output modalities - including text, images, geometric, and semantic modalities, as well as neural network feature maps. 4M achieves scalability by unifying the representation space of all modalities through mapping them into discrete tokens and performing multimodal masked modeling on a small randomized subset of tokens. 4M leads to models that exhibit several key capabilities: (1) they can perform a diverse set of vision tasks out of the box, (2) they excel when fine-tuned for unseen downstream tasks or new input modalities, and (3) they can function as a generative model that can be conditioned on arbitrary modalities, enabling a wide variety of expressive multimodal editing capabilities with remarkable flexibility. Through experimental analyses, we demonstrate the potential of 4M for training versatile and scalable foundation models for vision tasks, setting the stage for further exploration in multimodal learning for vision and other domains.
MultiMAE: Multi-modal Multi-task Masked Autoencoders
Apr 04, 2022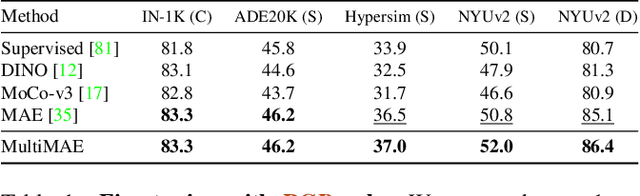
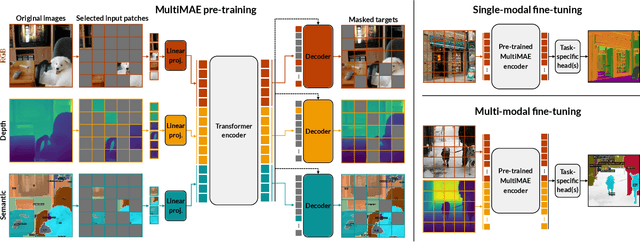

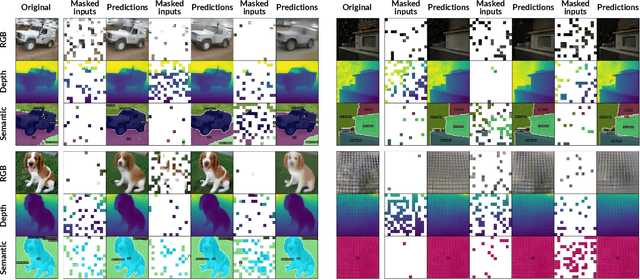
We propose a pre-training strategy called Multi-modal Multi-task Masked Autoencoders (MultiMAE). It differs from standard Masked Autoencoding in two key aspects: I) it can optionally accept additional modalities of information in the input besides the RGB image (hence "multi-modal"), and II) its training objective accordingly includes predicting multiple outputs besides the RGB image (hence "multi-task"). We make use of masking (across image patches and input modalities) to make training MultiMAE tractable as well as to ensure cross-modality predictive coding is indeed learned by the network. We show this pre-training strategy leads to a flexible, simple, and efficient framework with improved transfer results to downstream tasks. In particular, the same exact pre-trained network can be flexibly used when additional information besides RGB images is available or when no information other than RGB is available - in all configurations yielding competitive to or significantly better results than the baselines. To avoid needing training datasets with multiple modalities and tasks, we train MultiMAE entirely using pseudo labeling, which makes the framework widely applicable to any RGB dataset. The experiments are performed on multiple transfer tasks (image classification, semantic segmentation, depth estimation) and datasets (ImageNet, ADE20K, Taskonomy, Hypersim, NYUv2). The results show an intriguingly impressive capability by the model in cross-modal/task predictive coding and transfer.