 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Optical Computation-in-Communication enables low-latency, high-fidelity perception in telesurgery
Oct 15, 2025Artificial intelligence (AI) holds significant promise for enhancing intraoperative perception and decision-making in telesurgery, where physical separation impairs sensory feedback and control. Despite advances in medical AI and surgical robotics, conventional electronic AI architectures remain fundamentally constrained by the compounded latency from serial processing of inference and communication. This limitation is especially critical in latency-sensitive procedures such as endovascular interventions, where delays over 200 ms can compromise real-time AI reliability and patient safety. Here, we introduce an Optical Computation-in-Communication (OCiC) framework that reduces end-to-end latency significantly by performing AI inference concurrently with optical communication. OCiC integrates Optical Remote Computing Units (ORCUs) directly into the optical communication pathway, with each ORCU experimentally achieving up to 69 tera-operations per second per channel through spectrally efficient two-dimensional photonic convolution. The system maintains ultrahigh inference fidelity within 0.1% of CPU/GPU baselines on classification and coronary angiography segmentation, while intrinsically mitigating cumulative error propagation, a longstanding barrier to deep optical network scalability. We validated the robustness of OCiC through outdoor dark fibre deployments, confirming consistent and stable performance across varying environmental conditions. When scaled globally, OCiC transforms long-haul fibre infrastructure into a distributed photonic AI fabric with exascale potential, enabling reliable, low-latency telesurgery across distances up to 10,000 km and opening a new optical frontier for distributed medical intelligence.
Mobile Manipulation Planning for Tabletop Rearrangement
May 24, 2025
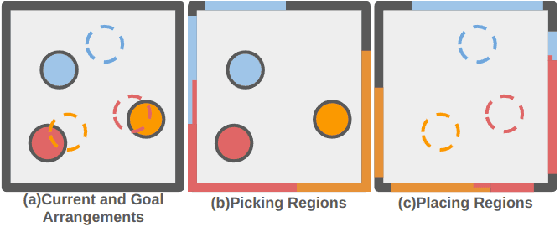
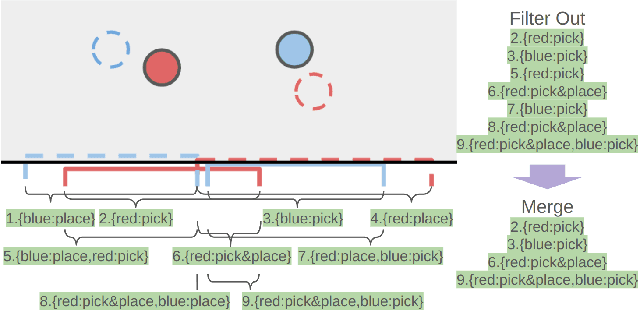
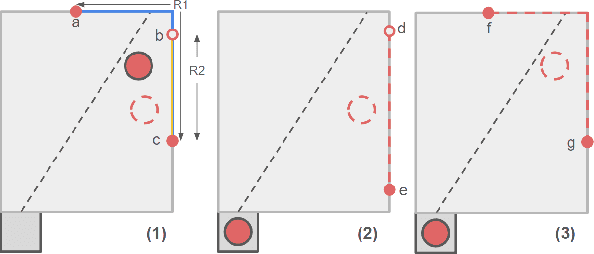
Efficient tabletop rearrangement planning seeks to find high-quality solutions while minimizing total cost. However, the task is challenging due to object dependencies and limited buffer space for temporary placements. The complexity increases for mobile robots, which must navigate around the table with restricted access. A*-based methods yield high-quality solutions, but struggle to scale as the number of objects increases. Monte Carlo Tree Search (MCTS) has been introduced as an anytime algorithm, but its convergence speed to high-quality solutions remains slow. Previous work~\cite{strap2024} accelerated convergence but required the robot to move to the closest position to the object for each pick and place operation, leading to inefficiencies. To address these limitations, we extend the planner by introducing a more efficient strategy for mobile robots. Instead of selecting the nearest available location for each action, our approach allows multiple operations (e.g., pick-and-place) from a single standing position, reducing unnecessary movement. Additionally, we incorporate state re-exploration to further improve plan quality. Experimental results show that our planner outperforms existing planners both in terms of solution quality and planning time.
UniGen: Enhanced Training & Test-Time Strategies for Unified Multimodal Understanding and Generation
May 20, 2025We introduce UniGen, a unified multimodal large language model (MLLM) capable of image understanding and generation. We study the full training pipeline of UniGen from a data-centric perspective, including multi-stage pre-training, supervised fine-tuning, and direct preference optimization. More importantly, we propose a new Chain-of-Thought Verification (CoT-V) strategy for test-time scaling, which significantly boosts UniGen's image generation quality using a simple Best-of-N test-time strategy. Specifically, CoT-V enables UniGen to act as both image generator and verifier at test time, assessing the semantic alignment between a text prompt and its generated image in a step-by-step CoT manner. Trained entirely on open-source datasets across all stages, UniGen achieves state-of-the-art performance on a range of image understanding and generation benchmarks, with a final score of 0.78 on GenEval and 85.19 on DPG-Bench. Through extensive ablation studies, our work provides actionable insights and addresses key challenges in the full life cycle of building unified MLLMs, contributing meaningful directions to the future research.
cpRRTC: GPU-Parallel RRT-Connect for Constrained Motion Planning
May 11, 2025Motion planning is a fundamental problem in robotics that involves generating feasible trajectories for a robot to follow. Recent advances in parallel computing, particularly through CPU and GPU architectures, have significantly reduced planning times to the order of milliseconds. However, constrained motion planning especially using sampling based methods on GPUs remains underexplored. Prior work such as pRRTC leverages a tracking compiler with a CUDA backend to accelerate forward kinematics and collision checking. While effective in simple settings, their approach struggles with increased complexity in robot models or environments. In this paper, we propose a novel GPU based framework utilizing NVRTC for runtime compilation, enabling efficient handling of high complexity scenarios and supporting constrained motion planning. Experimental results demonstrate that our method achieves superior performance compared to existing approaches.
Federated Learning Strategies for Coordinated Beamforming in Multicell ISAC
Jan 28, 2025We propose two cooperative beamforming frameworks based on federated learning (FL) for multi-cell integrated sensing and communications (ISAC) systems. Our objective is to address the following dilemma in multicell ISAC: 1) Beamforming strategies that rely solely on local channel information risk generating significant inter-cell interference (ICI), which degrades network performance for both communication users and sensing receivers in neighboring cells; 2) conversely centralized beamforming strategies can mitigate ICI by leveraging global channel information, but they come with substantial transmission overhead and latency that can be prohibitive for latency-sensitive and source-constrained applications. To tackle these challenges, we first propose a partially decentralized training framework motivated by the vertical federated learning (VFL) paradigm. In this framework, the participating base stations (BSs) collaboratively design beamforming matrices under the guidance of a central server. The central server aggregates local information from the BSs and provides feedback, allowing BSs to implicitly manage ICI without accessing the global channel information. To make the solution scalable for densely deployed wireless networks, we take further steps to reduce communication overhead by presenting a fully decentralized design based on the horizontal federated learning (HFL). Specifically, we develop a novel loss function to control the interference leakage power, enabling a more efficient training process by entirely eliminating local channel information exchange. Numerical results show that the proposed solutions can achieve significant performance improvements comparable to the benchmarks in terms of both communication and radar information rates.
Planning for Tabletop Object Rearrangement
Nov 16, 2024



Finding an high-quality solution for the tabletop object rearrangement planning is a challenging problem. Compared to determining a goal arrangement, rearrangement planning is challenging due to the dependencies between objects and the buffer capacity available to hold objects. Although orla* has proposed an A* based searching strategy with lazy evaluation for the high-quality solution, it is not scalable, with the success rate decreasing as the number of objects increases. To overcome this limitation, we propose an enhanced A*-based algorithm that improves state representation and employs incremental goal attempts with lazy evaluation at each iteration. This approach aims to enhance scalability while maintaining solution quality. Our evaluation demonstrates that our algorithm can provide superior solutions compared to orla*, in a shorter time, for both stationary and mobile robots.
4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities
Jun 14, 2024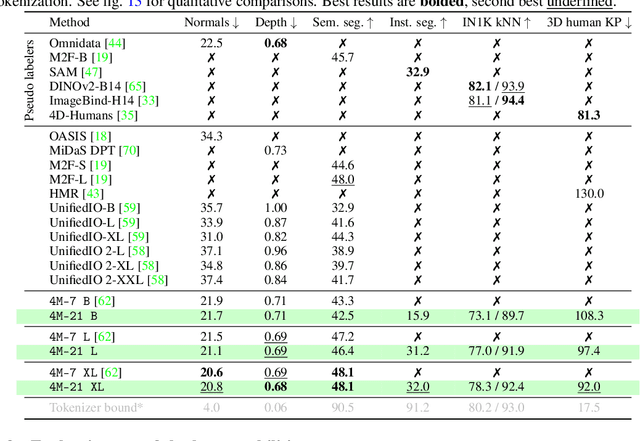

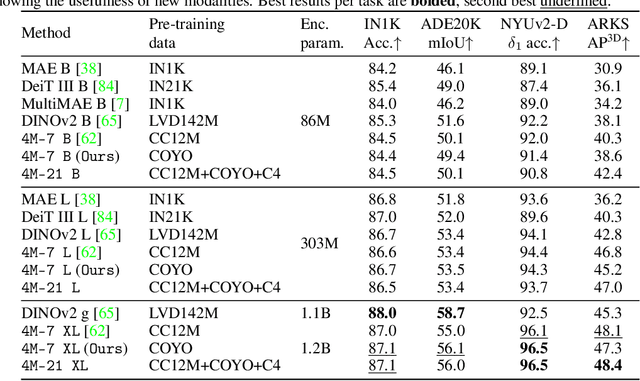
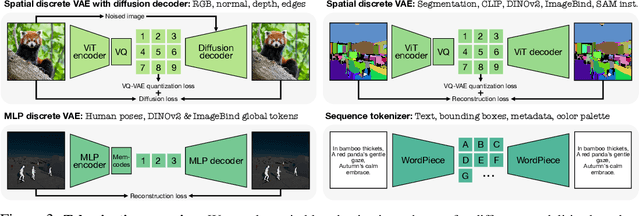
Current multimodal and multitask foundation models like 4M or UnifiedIO show promising results, but in practice their out-of-the-box abilities to accept diverse inputs and perform diverse tasks are limited by the (usually rather small) number of modalities and tasks they are trained on. In this paper, we expand upon the capabilities of them by training a single model on tens of highly diverse modalities and by performing co-training on large-scale multimodal datasets and text corpora. This includes training on several semantic and geometric modalities, feature maps from recent state of the art models like DINOv2 and ImageBind, pseudo labels of specialist models like SAM and 4DHumans, and a range of new modalities that allow for novel ways to interact with the model and steer the generation, for example image metadata or color palettes. A crucial step in this process is performing discrete tokenization on various modalities, whether they are image-like, neural network feature maps, vectors, structured data like instance segmentation or human poses, or data that can be represented as text. Through this, we expand on the out-of-the-box capabilities of multimodal models and specifically show the possibility of training one model to solve at least 3x more tasks/modalities than existing ones and doing so without a loss in performance. This enables more fine-grained and controllable multimodal generation capabilities and allows us to study the distillation of models trained on diverse data and objectives into a unified model. We successfully scale the training to a three billion parameter model using tens of modalities and different datasets. The resulting models and training code are open sourced at 4m.epfl.ch.
Household navigation and manipulation for everyday object rearrangement tasks
Dec 11, 2023



We consider the problem of building an assistive robotic system that can help humans in daily household cleanup tasks. Creating such an autonomous system in real-world environments is inherently quite challenging, as a general solution may not suit the preferences of a particular customer. Moreover, such a system consists of multi-objective tasks comprising -- (i) Detection of misplaced objects and prediction of their potentially correct placements, (ii) Fine-grained manipulation for stable object grasping, and (iii) Room-to-room navigation for transferring objects in unseen environments. This work systematically tackles each component and integrates them into a complete object rearrangement pipeline. To validate our proposed system, we conduct multiple experiments on a real robotic platform involving multi-room object transfer, user preference-based placement, and complex pick-and-place tasks. Project page: https://sites.google.com/eng.ucsd.edu/home-robot
An Experience-based TAMP Framework for Foliated Manifolds
Oct 12, 2023



Due to their complexity, foliated structure problems often pose intricate challenges to task and motion planning in robotics manipulation. To counter this, our study presents the ``Foliated Repetition Roadmap.'' This roadmap assists task and motion planners by transforming the complex foliated structure problem into a more accessible graph format. By leveraging query experiences from different foliated manifolds, our framework can dynamically and efficiently update this graph. The refined graph can generate distribution sets, optimizing motion planning performance in foliated structure problems. In our paper, we lay down the theoretical groundwork and illustrate its practical applications through real-world examples.