 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecTune: Effective Steering of Black-Box LLMs with Guide Models
Apr 09, 2026For large language models deployed through black-box APIs, recurring inference costs often exceed one-time training costs. This motivates composed agentic systems that amortize expensive reasoning into reusable intermediate representations. We study a broad class of such systems, termed Guide-Core Policies (GCoP), in which a guide model generates a structured strategy that is executed by a black-box core model. This abstraction subsumes base, supervised, and advisor-style approaches, which differ primarily in how the guide is trained. We formalize GCoP under a cost-sensitive utility objective and show that end-to-end performance is governed by guide-averaged executability: the probability that a strategy generated by the guide can be faithfully executed by the core. Our analysis shows that existing GCoP instantiations often fail to optimize executability under deployment constraints, resulting in brittle strategies and inefficient computation. Motivated by these insights, we propose ExecTune, a principled training recipe that combines teacher-guided acceptance sampling, supervised fine-tuning, and structure-aware reinforcement learning to directly optimize syntactic validity, execution success, and cost efficiency. Across mathematical reasoning and code-generation benchmarks, GCoP with ExecTune improves accuracy by up to 9.2% over prior state-of-the-art baselines while reducing inference cost by up to 22.4%. It enables Claude Haiku 3.5 to outperform Sonnet 3.5 on both math and code tasks, and to come within 1.7% absolute accuracy of Sonnet 4 at 38% lower cost. Beyond efficiency, GCoP also supports modular adaptation by updating the guide without retraining the core.
ELLA: Efficient Lifelong Learning for Adapters in Large Language Models
Jan 07, 2026Large Language Models (LLMs) suffer severe catastrophic forgetting when adapted sequentially to new tasks in a continual learning (CL) setting. Existing approaches are fundamentally limited: replay-based methods are impractical and privacy-violating, while strict orthogonality-based methods collapse under scale: each new task is projected onto an orthogonal complement, progressively reducing the residual degrees of freedom and eliminating forward transfer by forbidding overlap in shared representations. In this work, we introduce ELLA, a training framework built on the principle of selective subspace de-correlation. Rather than forbidding all overlap, ELLA explicitly characterizes the structure of past updates and penalizes alignments along their high-energy, task-specific directions, while preserving freedom in the low-energy residual subspaces to enable transfer. Formally, this is realized via a lightweight regularizer on a single aggregated update matrix. We prove this mechanism corresponds to an anisotropic shrinkage operator that bounds interference, yielding a penalty that is both memory- and compute-constant regardless of task sequence length. ELLA requires no data replay, no architectural expansion, and negligible storage. Empirically, it achieves state-of-the-art CL performance on three popular benchmarks, with relative accuracy gains of up to $9.6\%$ and a $35\times$ smaller memory footprint. Further, ELLA scales robustly across architectures and actively enhances the model's zero-shot generalization performance on unseen tasks, establishing a principled and scalable solution for constructive lifelong LLM adaptation.
Tagging-Augmented Generation: Assisting Language Models in Finding Intricate Knowledge In Long Contexts
Oct 27, 2025Recent investigations into effective context lengths of modern flagship large language models (LLMs) have revealed major limitations in effective question answering (QA) and reasoning over long and complex contexts for even the largest and most impressive cadre of models. While approaches like retrieval-augmented generation (RAG) and chunk-based re-ranking attempt to mitigate this issue, they are sensitive to chunking, embedding and retrieval strategies and models, and furthermore, rely on extensive pre-processing, knowledge acquisition and indexing steps. In this paper, we propose Tagging-Augmented Generation (TAG), a lightweight data augmentation strategy that boosts LLM performance in long-context scenarios, without degrading and altering the integrity and composition of retrieved documents. We validate our hypothesis by augmenting two challenging and directly relevant question-answering benchmarks -- NoLima and NovelQA -- and show that tagging the context or even just adding tag definitions into QA prompts leads to consistent performance gains over the baseline -- up to 17% for 32K token contexts, and 2.9% in complex reasoning question-answering for multi-hop queries requiring knowledge across a wide span of text. Additional details are available at https://sites.google.com/view/tag-emnlp.
The Empirical Impact of Data Sanitization on Language Models
Nov 08, 2024



Data sanitization in the context of language modeling involves identifying sensitive content, such as personally identifiable information (PII), and redacting them from a dataset corpus. It is a common practice used in natural language processing (NLP) to maintain privacy. Nevertheless, the impact of data sanitization on the language understanding capability of a language model remains less studied. This paper empirically analyzes the effects of data sanitization across several benchmark language-modeling tasks including comprehension question answering (Q&A), entailment, sentiment analysis, and text classification. Our experiments cover a wide spectrum comprising finetuning small-scale language models, to prompting large language models (LLMs), on both original and sanitized datasets, and comparing their performance across the tasks. Interestingly, our results suggest that for some tasks such as sentiment analysis or entailment, the impact of redaction is quite low, typically around 1-5%, while for tasks such as comprehension Q&A there is a big drop of >25% in performance observed in redacted queries as compared to the original. For tasks that have a higher impact, we perform a deeper dive to inspect the presence of task-critical entities. Finally, we investigate correlation between performance and number of redacted entities, and also suggest a strategy to repair an already redacted dataset by means of content-based subsampling. Additional details are available at https://sites.google.com/view/datasan.
Household navigation and manipulation for everyday object rearrangement tasks
Dec 11, 2023



We consider the problem of building an assistive robotic system that can help humans in daily household cleanup tasks. Creating such an autonomous system in real-world environments is inherently quite challenging, as a general solution may not suit the preferences of a particular customer. Moreover, such a system consists of multi-objective tasks comprising -- (i) Detection of misplaced objects and prediction of their potentially correct placements, (ii) Fine-grained manipulation for stable object grasping, and (iii) Room-to-room navigation for transferring objects in unseen environments. This work systematically tackles each component and integrates them into a complete object rearrangement pipeline. To validate our proposed system, we conduct multiple experiments on a real robotic platform involving multi-room object transfer, user preference-based placement, and complex pick-and-place tasks. Project page: https://sites.google.com/eng.ucsd.edu/home-robot
FashionNTM: Multi-turn Fashion Image Retrieval via Cascaded Memory
Aug 20, 2023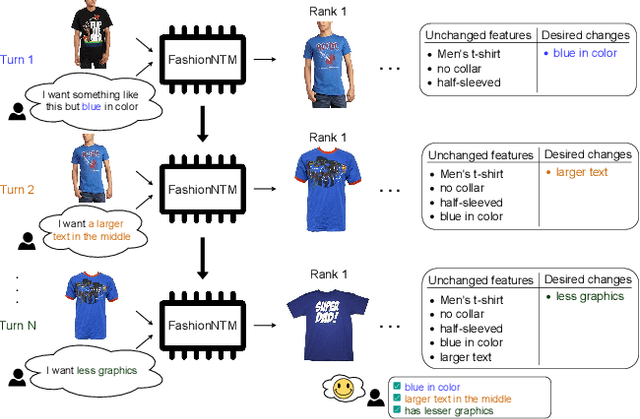
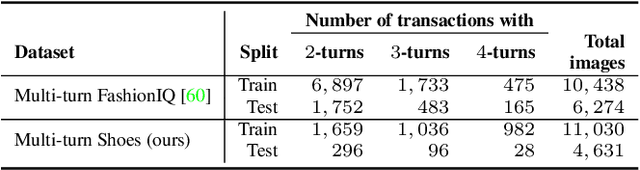
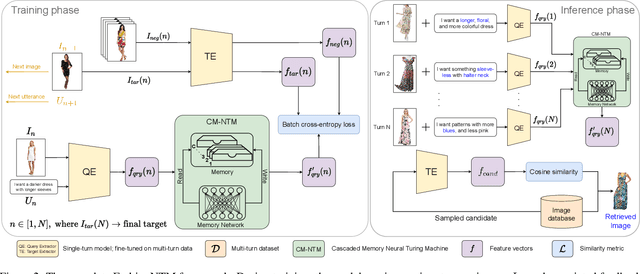
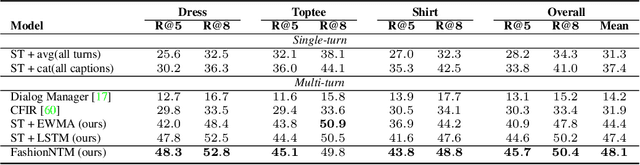
Multi-turn textual feedback-based fashion image retrieval focuses on a real-world setting, where users can iteratively provide information to refine retrieval results until they find an item that fits all their requirements. In this work, we present a novel memory-based method, called FashionNTM, for such a multi-turn system. Our framework incorporates a new Cascaded Memory Neural Turing Machine (CM-NTM) approach for implicit state management, thereby learning to integrate information across all past turns to retrieve new images, for a given turn. Unlike vanilla Neural Turing Machine (NTM), our CM-NTM operates on multiple inputs, which interact with their respective memories via individual read and write heads, to learn complex relationships. Extensive evaluation results show that our proposed method outperforms the previous state-of-the-art algorithm by 50.5%, on Multi-turn FashionIQ -- the only existing multi-turn fashion dataset currently, in addition to having a relative improvement of 12.6% on Multi-turn Shoes -- an extension of the single-turn Shoes dataset that we created in this work. Further analysis of the model in a real-world interactive setting demonstrates two important capabilities of our model -- memory retention across turns, and agnosticity to turn order for non-contradictory feedback. Finally, user study results show that images retrieved by FashionNTM were favored by 83.1% over other multi-turn models. Project page: https://sites.google.com/eng.ucsd.edu/fashionntm
Role of reward shaping in object-goal navigation
Jul 16, 2022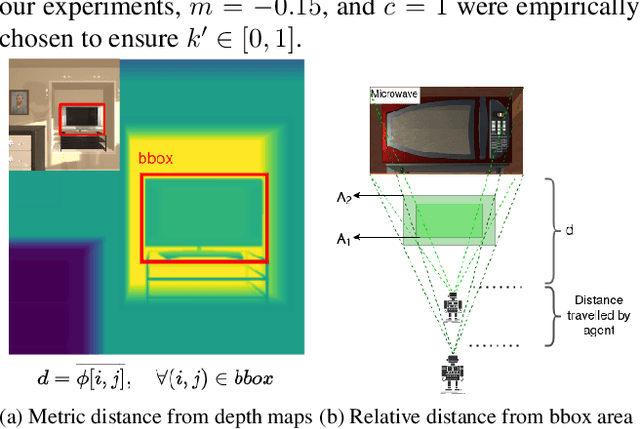

Deep reinforcement learning approaches have been a popular method for visual navigation tasks in the computer vision and robotics community of late. In most cases, the reward function has a binary structure, i.e., a large positive reward is provided when the agent reaches goal state, and a negative step penalty is assigned for every other state in the environment. A sparse signal like this makes the learning process challenging, specially in big environments, where a large number of sequential actions need to be taken to reach the target. We introduce a reward shaping mechanism which gradually adjusts the reward signal based on distance to the goal. Detailed experiments conducted using the AI2-THOR simulation environment demonstrate the efficacy of the proposed approach for object-goal navigation tasks.
Target driven visual navigation exploiting object relationships
Mar 15, 2020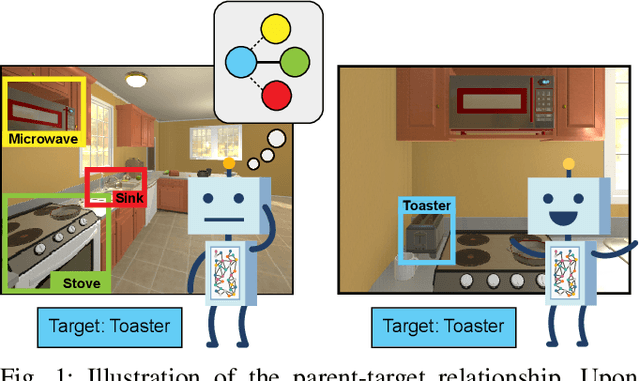
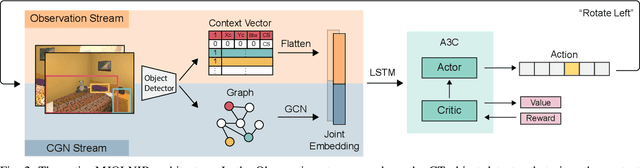
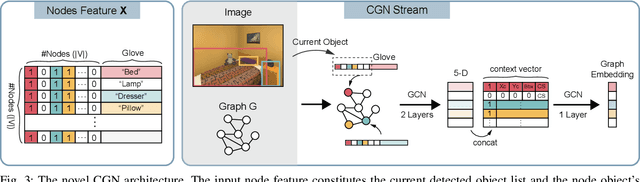
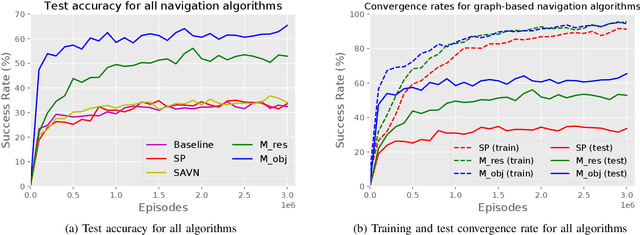
Recently target driven visual navigation strategies have gained a lot of popularity in the computer vision and reinforcement learning community. Unfortunately, most of the current research tends to incorporate sensory input into a reward-based learning approach, with the hope that a robot can implicitly learn its optimal actions through recursive trials. These methods seldom generalize across domains as they fail to exploit natural environment object relationships. We present Memory-utilized Joint hierarchical Object Learning for Navigation in Indoor Rooms (MJOLNIR), a target-driven visual navigation algorithm, which considers the inherent relationship between "target" objects, along with the more salient "parent" objects occurring in its surrounding. Extensive experiments conducted across multiple environment settings show $\approx \textbf{30 %}$ improvement over the existing state-of-the-art navigation methods in terms of the success rate. We also show that our model learns to converge much faster than other algorithms. We will make our code publicly available for use in the scientific community.
"Looking at the right stuff" -- Guided semantic-gaze for autonomous driving
Nov 24, 2019



In recent years, predicting driver's focus of attention has been a very active area of research in the autonomous driving community. Unfortunately, existing state-of-the-art techniques achieve this by relying only on human gaze information, thereby ignoring scene semantics. We propose a novel Semantics Augmented GazE (SAGE) detection approach that captures driving specific contextual information, in addition to the raw gaze. Such a combined attention mechanism serves as a powerful tool to focus on the relevant regions in an image frame in order to make driving both safe and efficient. Using this, we design a complete saliency prediction framework -- SAGE-Net, which modifies the initial prediction from SAGE by taking into account vital aspects such as distance to objects (depth), ego vehicle speed, and pedestrian crossing intent. Exhaustive experiments conducted through four popular saliency algorithms show that on 49/56 (87.5%) cases -- considering both the overall dataset and crucial driving scenarios, SAGE outperforms existing techniques without any additional computational overhead during the training process. The final paper will be accompanied by the release of our dataset and relevant code.
DEDUCE: Diverse scEne Detection methods in Unseen Challenging Environments
Aug 01, 2019
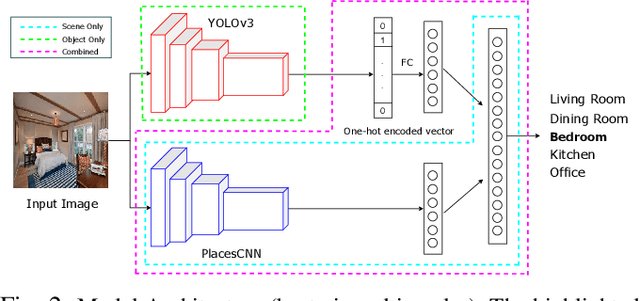
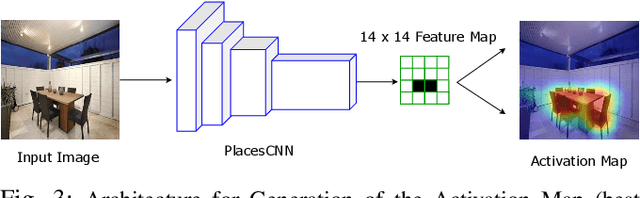

In recent years, there has been a rapid increase in the number of service robots deployed for aiding people in their daily activities. Unfortunately, most of these robots require human input for training in order to do tasks in indoor environments. Successful domestic navigation often requires access to semantic information about the environment, which can be learned without human guidance. In this paper, we propose a set of DEDUCE - Diverse scEne Detection methods in Unseen Challenging Environments algorithms which incorporate deep fusion models derived from scene recognition systems and object detectors. The five methods described here have been evaluated on several popular recent image datasets, as well as real-world videos acquired through multiple mobile platforms. The final results show an improvement over the existing state-of-the-art visual place recognition systems.