 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEDUCE: Diverse scEne Detection methods in Unseen Challenging Environments
Paper and Code

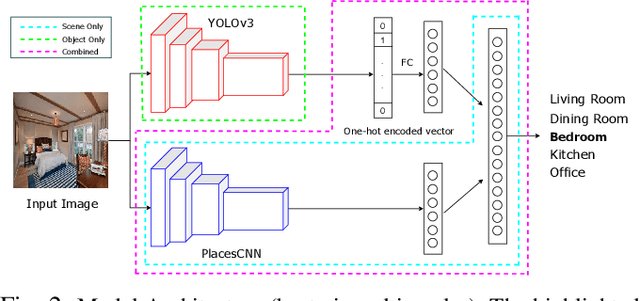
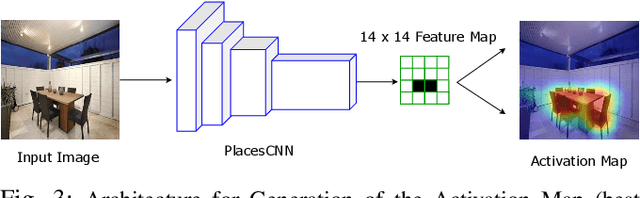

In recent years, there has been a rapid increase in the number of service robots deployed for aiding people in their daily activities. Unfortunately, most of these robots require human input for training in order to do tasks in indoor environments. Successful domestic navigation often requires access to semantic information about the environment, which can be learned without human guidance. In this paper, we propose a set of DEDUCE - Diverse scEne Detection methods in Unseen Challenging Environments algorithms which incorporate deep fusion models derived from scene recognition systems and object detectors. The five methods described here have been evaluated on several popular recent image datasets, as well as real-world videos acquired through multiple mobile platforms. The final results show an improvement over the existing state-of-the-art visual place recognition systems.