 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Blinks in Healthy and Parkinson's EEG: A Deep Learning Perspective
Sep 05, 2025Blinks in electroencephalography (EEG) are often treated as unwanted artifacts. However, recent studies have demonstrated that blink rate and its variability are important physiological markers to monitor cognitive load, attention, and potential neurological disorders. This paper addresses the critical task of accurate blink detection by evaluating various deep learning models for segmenting EEG signals into involuntary blinks and non-blinks. We present a pipeline for blink detection using 1, 3, or 5 frontal EEG electrodes. The problem is formulated as a sequence-to-sequence task and tested on various deep learning architectures including standard recurrent neural networks, convolutional neural networks (both standard and depth-wise), temporal convolutional networks (TCN), transformer-based models, and hybrid architectures. The models were trained on raw EEG signals with minimal pre-processing. Training and testing was carried out on a public dataset of 31 subjects collected at UCSD. This dataset consisted of 15 healthy participants and 16 patients with Parkinson's disease allowing us to verify the model's robustness to tremor. Out of all models, CNN-RNN hybrid model consistently outperformed other models and achieved the best blink detection accuracy of 93.8%, 95.4% and 95.8% with 1, 3, and 5 channels in the healthy cohort and correspondingly 73.8%, 75.4% and 75.8% in patients with PD. The paper compares neural networks for the task of segmenting EEG recordings to involuntary blinks and no blinks allowing for computing blink rate and other statistics.
3D Scene Graph Prediction on Point Clouds Using Knowledge Graphs
Aug 13, 20233D scene graph prediction is a task that aims to concurrently predict object classes and their relationships within a 3D environment. As these environments are primarily designed by and for humans, incorporating commonsense knowledge regarding objects and their relationships can significantly constrain and enhance the prediction of the scene graph. In this paper, we investigate the application of commonsense knowledge graphs for 3D scene graph prediction on point clouds of indoor scenes. Through experiments conducted on a real-world indoor dataset, we demonstrate that integrating external commonsense knowledge via the message-passing method leads to a 15.0 % improvement in scene graph prediction accuracy with external knowledge and $7.96\%$ with internal knowledge when compared to state-of-the-art algorithms. We also tested in the real world with 10 frames per second for scene graph generation to show the usage of the model in a more realistic robotics setting.
Target driven visual navigation exploiting object relationships
Mar 15, 2020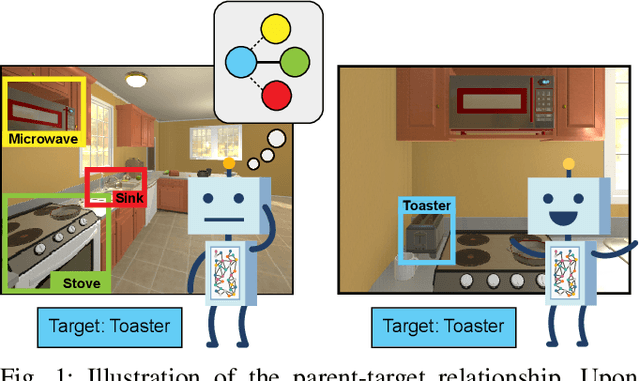
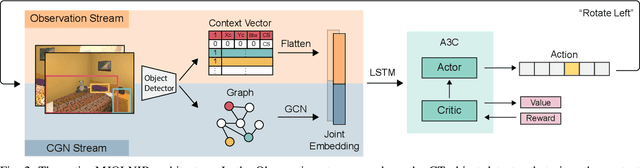
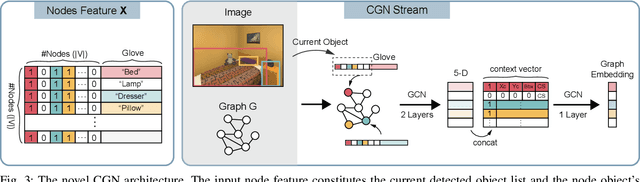
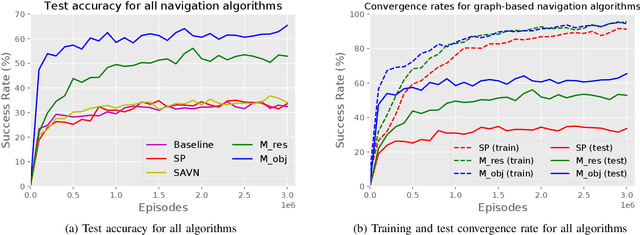
Recently target driven visual navigation strategies have gained a lot of popularity in the computer vision and reinforcement learning community. Unfortunately, most of the current research tends to incorporate sensory input into a reward-based learning approach, with the hope that a robot can implicitly learn its optimal actions through recursive trials. These methods seldom generalize across domains as they fail to exploit natural environment object relationships. We present Memory-utilized Joint hierarchical Object Learning for Navigation in Indoor Rooms (MJOLNIR), a target-driven visual navigation algorithm, which considers the inherent relationship between "target" objects, along with the more salient "parent" objects occurring in its surrounding. Extensive experiments conducted across multiple environment settings show $\approx \textbf{30 %}$ improvement over the existing state-of-the-art navigation methods in terms of the success rate. We also show that our model learns to converge much faster than other algorithms. We will make our code publicly available for use in the scientific community.