 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Does GPT-4o Understand Vision? Evaluating Multimodal Foundation Models on Standard Computer Vision Tasks
Jul 02, 2025Multimodal foundation models, such as GPT-4o, have recently made remarkable progress, but it is not clear where exactly these models stand in terms of understanding vision. In this paper, we benchmark the performance of popular multimodal foundation models (GPT-4o, o4-mini, Gemini 1.5 Pro and Gemini 2.0 Flash, Claude 3.5 Sonnet, Qwen2-VL, Llama 3.2) on standard computer vision tasks (semantic segmentation, object detection, image classification, depth and surface normal prediction) using established datasets (e.g., COCO, ImageNet and its variants, etc). The main challenges to performing this are: 1) most models are trained to output text and cannot natively express versatile domains, such as segments or 3D geometry, and 2) many leading models are proprietary and accessible only at an API level, i.e., there is no weight access to adapt them. We address these challenges by translating standard vision tasks into equivalent text-promptable and API-compatible tasks via prompt chaining to create a standardized benchmarking framework. We observe that 1) the models are not close to the state-of-the-art specialist models at any task. However, 2) they are respectable generalists; this is remarkable as they are presumably trained on primarily image-text-based tasks. 3) They perform semantic tasks notably better than geometric ones. 4) While the prompt-chaining techniques affect performance, better models exhibit less sensitivity to prompt variations. 5) GPT-4o performs the best among non-reasoning models, securing the top position in 4 out of 6 tasks, 6) reasoning models, e.g. o3, show improvements in geometric tasks, and 7) a preliminary analysis of models with native image generation, like the latest GPT-4o, shows they exhibit quirks like hallucinations and spatial misalignments.
Large (Vision) Language Models are Unsupervised In-Context Learners
Apr 03, 2025Recent advances in large language and vision-language models have enabled zero-shot inference, allowing models to solve new tasks without task-specific training. Various adaptation techniques such as prompt engineering, In-Context Learning (ICL), and supervised fine-tuning can further enhance the model's performance on a downstream task, but they require substantial manual effort to construct effective prompts or labeled examples. In this work, we introduce a joint inference framework for fully unsupervised adaptation, eliminating the need for manual prompt engineering and labeled examples. Unlike zero-shot inference, which makes independent predictions, the joint inference makes predictions simultaneously for all inputs in a given task. Since direct joint inference involves computationally expensive optimization, we develop efficient approximation techniques, leading to two unsupervised adaptation methods: unsupervised fine-tuning and unsupervised ICL. We demonstrate the effectiveness of our methods across diverse tasks and models, including language-only Llama-3.1 on natural language processing tasks, reasoning-oriented Qwen2.5-Math on grade school math problems, vision-language OpenFlamingo on vision tasks, and the API-only access GPT-4o model on massive multi-discipline tasks. Our experiments demonstrate substantial improvements over the standard zero-shot approach, including 39% absolute improvement on the challenging GSM8K math reasoning dataset. Remarkably, despite being fully unsupervised, our framework often performs on par with supervised approaches that rely on ground truth labels.
Solving Vision Tasks with Simple Photoreceptors Instead of Cameras
Jun 17, 2024A de facto standard in solving computer vision problems is to use a common high-resolution camera and choose its placement on an agent (i.e., position and orientation) based on human intuition. On the other hand, extremely simple and well-designed visual sensors found throughout nature allow many organisms to perform diverse, complex behaviors. In this work, motivated by these examples, we raise the following questions: 1. How effective simple visual sensors are in solving vision tasks? 2. What role does their design play in their effectiveness? We explore simple sensors with resolutions as low as one-by-one pixel, representing a single photoreceptor First, we demonstrate that just a few photoreceptors can be enough to solve many tasks, such as visual navigation and continuous control, reasonably well, with performance comparable to that of a high-resolution camera. Second, we show that the design of these simple visual sensors plays a crucial role in their ability to provide useful information and successfully solve these tasks. To find a well-performing design, we present a computational design optimization algorithm and evaluate its effectiveness across different tasks and domains, showing promising results. Finally, we perform a human survey to evaluate the effectiveness of intuitive designs devised manually by humans, showing that the computationally found design is among the best designs in most cases.
Controlled Training Data Generation with Diffusion Models
Mar 22, 2024In this work, we present a method to control a text-to-image generative model to produce training data specifically "useful" for supervised learning. Unlike previous works that employ an open-loop approach and pre-define prompts to generate new data using either a language model or human expertise, we develop an automated closed-loop system which involves two feedback mechanisms. The first mechanism uses feedback from a given supervised model and finds adversarial prompts that result in image generations that maximize the model loss. While these adversarial prompts result in diverse data informed by the model, they are not informed of the target distribution, which can be inefficient. Therefore, we introduce the second feedback mechanism that guides the generation process towards a certain target distribution. We call the method combining these two mechanisms Guided Adversarial Prompts. We perform our evaluations on different tasks, datasets and architectures, with different types of distribution shifts (spuriously correlated data, unseen domains) and demonstrate the efficiency of the proposed feedback mechanisms compared to open-loop approaches.
Unraveling the Key Components of OOD Generalization via Diversification
Dec 26, 2023Real-world datasets may contain multiple features that explain the training data equally well, i.e., learning any of them would lead to correct predictions on the training data. However, many of them can be spurious, i.e., lose their predictive power under a distribution shift and fail to generalize to out-of-distribution (OOD) data. Recently developed ``diversification'' methods approach this problem by finding multiple diverse hypotheses that rely on different features. This paper aims to study this class of methods and identify the key components contributing to their OOD generalization abilities. We show that (1) diversification methods are highly sensitive to the distribution of the unlabeled data used for diversification and can underperform significantly when away from a method-specific sweet spot. (2) Diversification alone is insufficient for OOD generalization. The choice of the used learning algorithm, e.g., the model's architecture and pretraining, is crucial, and using the second-best choice leads to an up to 20% absolute drop in accuracy.(3) The optimal choice of learning algorithm depends on the unlabeled data, and vice versa.Finally, we show that the above pitfalls cannot be alleviated by increasing the number of diverse hypotheses, allegedly the major feature of diversification methods. These findings provide a clearer understanding of the critical design factors influencing the OOD generalization of diversification methods. They can guide practitioners in how to use the existing methods best and guide researchers in developing new, better ones.
Task Discovery: Finding the Tasks that Neural Networks Generalize on
Dec 01, 2022



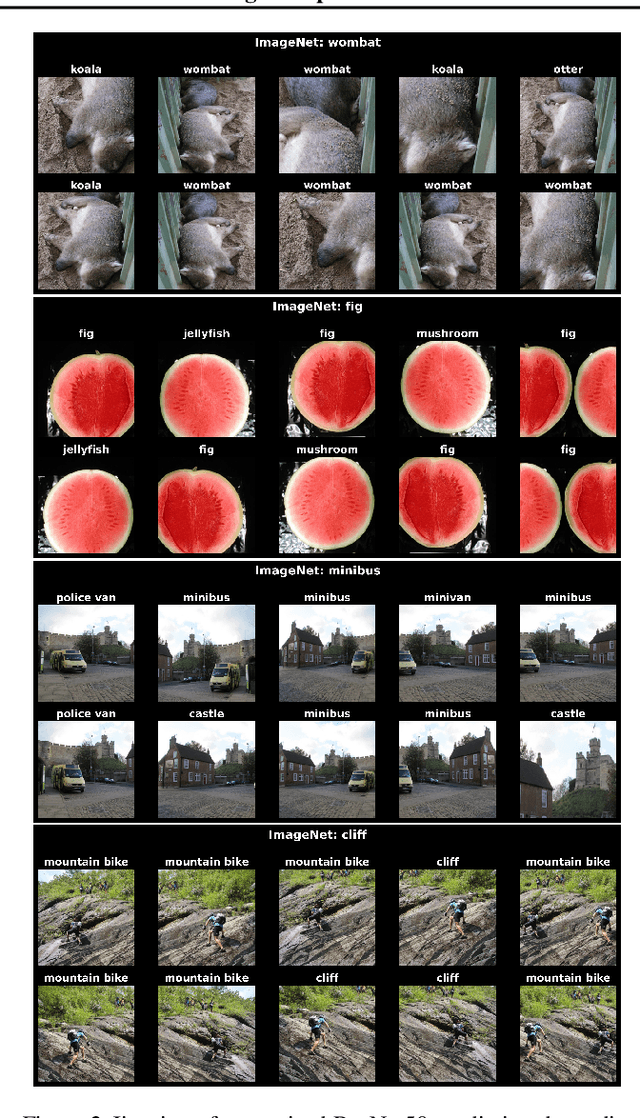
When developing deep learning models, we usually decide what task we want to solve then search for a model that generalizes well on the task. An intriguing question would be: what if, instead of fixing the task and searching in the model space, we fix the model and search in the task space? Can we find tasks that the model generalizes on? How do they look, or do they indicate anything? These are the questions we address in this paper. We propose a task discovery framework that automatically finds examples of such tasks via optimizing a generalization-based quantity called agreement score. We demonstrate that one set of images can give rise to many tasks on which neural networks generalize well. These tasks are a reflection of the inductive biases of the learning framework and the statistical patterns present in the data, thus they can make a useful tool for analysing the neural networks and their biases. As an example, we show that the discovered tasks can be used to automatically create adversarial train-test splits which make a model fail at test time, without changing the pixels or labels, but by only selecting how the datapoints should be split between the train and test sets. We end with a discussion on human-interpretability of the discovered tasks.
MultiMAE: Multi-modal Multi-task Masked Autoencoders
Apr 04, 2022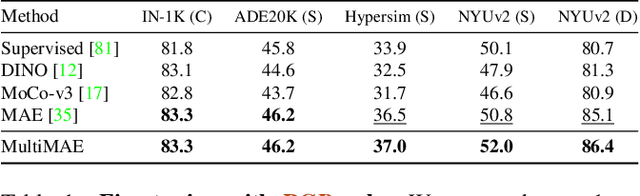
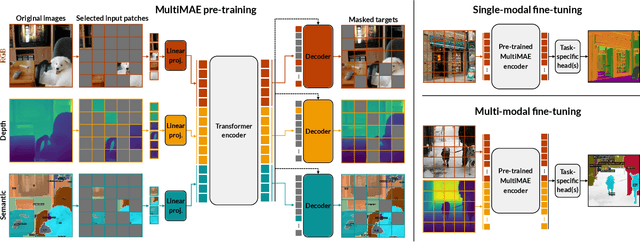

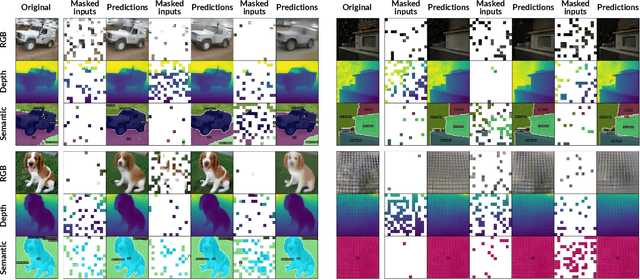
We propose a pre-training strategy called Multi-modal Multi-task Masked Autoencoders (MultiMAE). It differs from standard Masked Autoencoding in two key aspects: I) it can optionally accept additional modalities of information in the input besides the RGB image (hence "multi-modal"), and II) its training objective accordingly includes predicting multiple outputs besides the RGB image (hence "multi-task"). We make use of masking (across image patches and input modalities) to make training MultiMAE tractable as well as to ensure cross-modality predictive coding is indeed learned by the network. We show this pre-training strategy leads to a flexible, simple, and efficient framework with improved transfer results to downstream tasks. In particular, the same exact pre-trained network can be flexibly used when additional information besides RGB images is available or when no information other than RGB is available - in all configurations yielding competitive to or significantly better results than the baselines. To avoid needing training datasets with multiple modalities and tasks, we train MultiMAE entirely using pseudo labeling, which makes the framework widely applicable to any RGB dataset. The experiments are performed on multiple transfer tasks (image classification, semantic segmentation, depth estimation) and datasets (ImageNet, ADE20K, Taskonomy, Hypersim, NYUv2). The results show an intriguingly impressive capability by the model in cross-modal/task predictive coding and transfer.
3D Common Corruptions and Data Augmentation
Apr 04, 2022
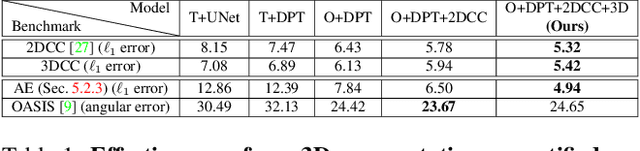

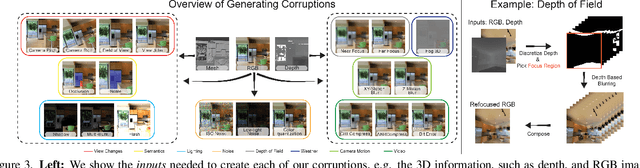
We introduce a set of image transformations that can be used as corruptions to evaluate the robustness of models as well as data augmentation mechanisms for training neural networks. The primary distinction of the proposed transformations is that, unlike existing approaches such as Common Corruptions, the geometry of the scene is incorporated in the transformations -- thus leading to corruptions that are more likely to occur in the real world. We also introduce a set of semantic corruptions (e.g. natural object occlusions). We show these transformations are `efficient' (can be computed on-the-fly), `extendable' (can be applied on most image datasets), expose vulnerability of existing models, and can effectively make models more robust when employed as `3D data augmentation' mechanisms. The evaluations on several tasks and datasets suggest incorporating 3D information into benchmarking and training opens up a promising direction for robustness research.
Simple Control Baselines for Evaluating Transfer Learning
Feb 07, 2022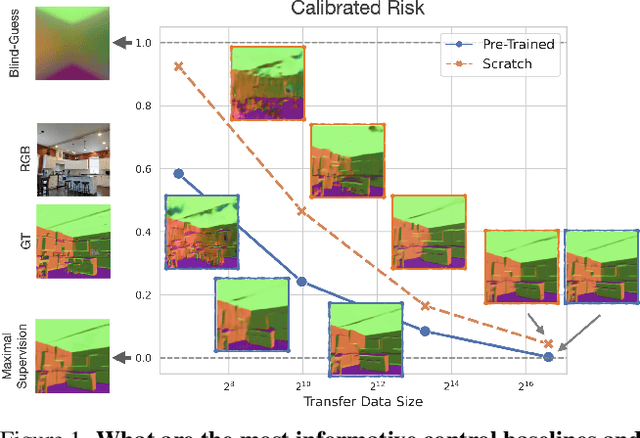
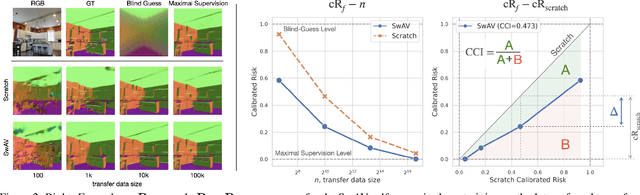
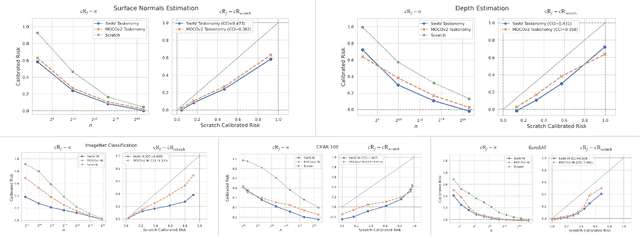
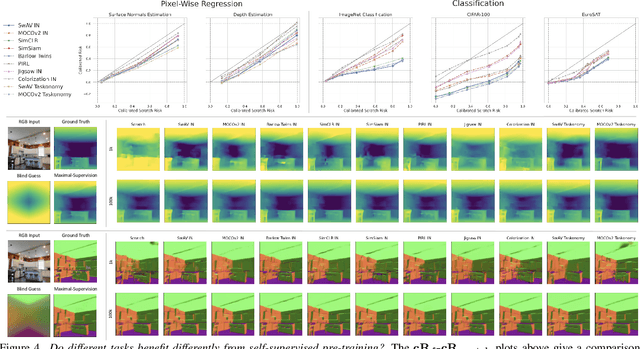
Transfer learning has witnessed remarkable progress in recent years, for example, with the introduction of augmentation-based contrastive self-supervised learning methods. While a number of large-scale empirical studies on the transfer performance of such models have been conducted, there is not yet an agreed-upon set of control baselines, evaluation practices, and metrics to report, which often hinders a nuanced and calibrated understanding of the real efficacy of the methods. We share an evaluation standard that aims to quantify and communicate transfer learning performance in an informative and accessible setup. This is done by baking a number of simple yet critical control baselines in the evaluation method, particularly the blind-guess (quantifying the dataset bias), scratch-model (quantifying the architectural contribution), and maximal-supervision (quantifying the upper-bound). To demonstrate how the evaluation standard can be employed, we provide an example empirical study investigating a few basic questions about self-supervised learning. For example, using this standard, the study shows the effectiveness of existing self-supervised pre-training methods is skewed towards image classification tasks versus dense pixel-wise predictions. In general, we encourage using/reporting the suggested control baselines in evaluating transfer learning in order to gain a more meaningful and informative understanding.
Mean Embeddings with Test-Time Data Augmentation for Ensembling of Representations
Jul 14, 2021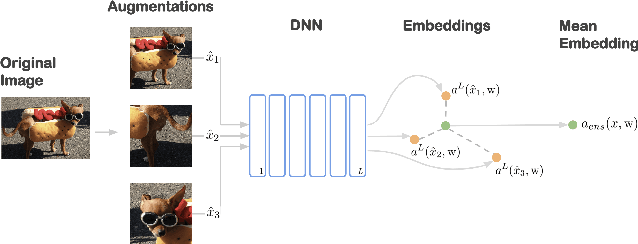
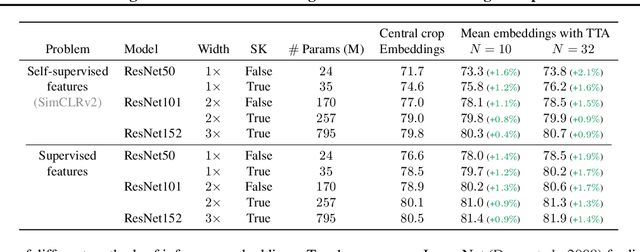
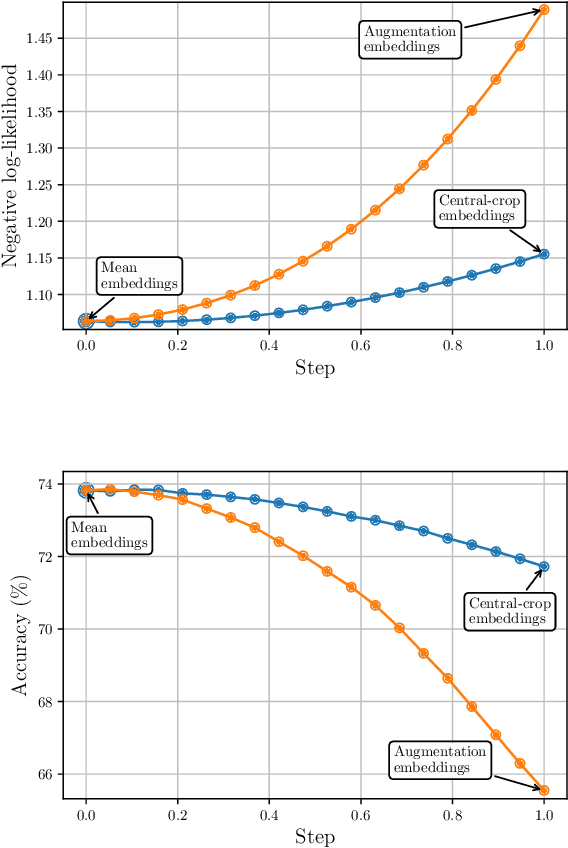
Averaging predictions over a set of models -- an ensemble -- is widely used to improve predictive performance and uncertainty estimation of deep learning models. At the same time, many machine learning systems, such as search, matching, and recommendation systems, heavily rely on embeddings. Unfortunately, due to misalignment of features of independently trained models, embeddings, cannot be improved with a naive deep ensemble like approach. In this work, we look at the ensembling of representations and propose mean embeddings with test-time augmentation (MeTTA) simple yet well-performing recipe for ensembling representations. Empirically we demonstrate that MeTTA significantly boosts the quality of linear evaluation on ImageNet for both supervised and self-supervised models. Even more exciting, we draw connections between MeTTA, image retrieval, and transformation invariant models. We believe that spreading the success of ensembles to inference higher-quality representations is the important step that will open many new applications of ensembling.