 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNIMO: a Nonlinear Interpretable MOdel
Jun 05, 2025Neural networks (NNs) have achieved tremendous success over the past decade, yet they are still extremely difficult to interpret. In contrast, linear models are less expressive but offer inherent interpretability. Linear coefficients are interpretable as the marginal effect of a feature on the prediction, assuming all other features are kept fixed. To combine the benefits of both approaches, we introduce NIMO (Nonlinear Interpretable MOdel). The key idea is to define a model where the NN is designed to learn nonlinear corrections to the linear model predictions, while also maintaining the original interpretability of the linear coefficients. Relevantly, we develop an optimization algorithm based on profile likelihood that elegantly allows for optimizing over the NN parameters while updating the linear coefficients analytically. By relying on adaptive ridge regression we can easily incorporate sparsity constraints as well. We show empirically that we can recover the underlying linear coefficients while significantly improving the predictive accuracy. Compared to other hybrid interpretable approaches, our model is the only one that actually maintains the same interpretability of linear coefficients as in linear models. We also achieve higher performance on various regression and classification settings.
Weight Averaging for Out-of-Distribution Generalization and Few-Shot Domain Adaptation
Jan 14, 2025Empirical risk minimization (ERM) is not robust to changes in the distribution of data. When the distribution of test data is different from that of training data, the problem is known as out-of-distribution generalization. Recently, two techniques have been developed for addressing out-of-distribution generalization in computer vision: weight averaging (WA) and sharpness-aware minimization (SAM). WA involves training multiple models with different hyperparameters and then averaging the weights of these models, which can significantly improve out-of-distribution generalization performance. SAM optimizes a neural network to find minima in flat regions, which have been proven to perform well under distribution shifts. While these techniques have made great progress, there is still room for improvement and further exploration. In this thesis, we propose increasing the model diversity in WA explicitly by introducing gradient similarity as a loss regularizer to further improve out-of-distribution generalization performance. We also propose combining WA and SAM to solve the problem of few-shot domain adaptation. Our extensive experiments on digits datasets (MNIST, SVHN, USPS, MNIST-M) and other domain adaptation datasets (VLCS, PACS) show that combining WA and SAM leads to improved out-of-distribution generalization performance and significantly increases few-shot domain adaptation accuracy.
Simple Control Baselines for Evaluating Transfer Learning
Feb 07, 2022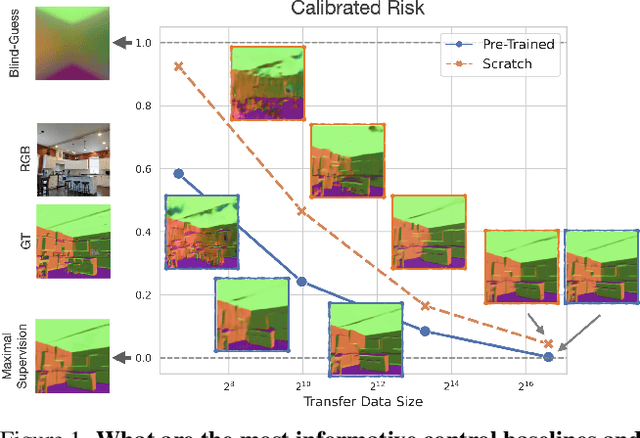
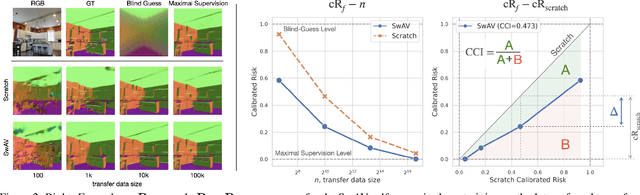
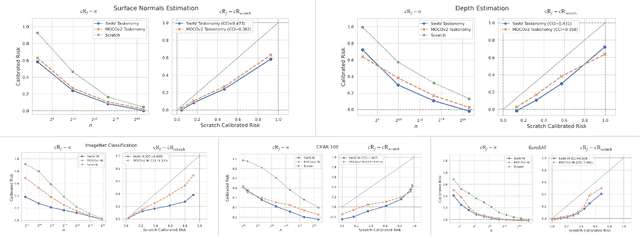
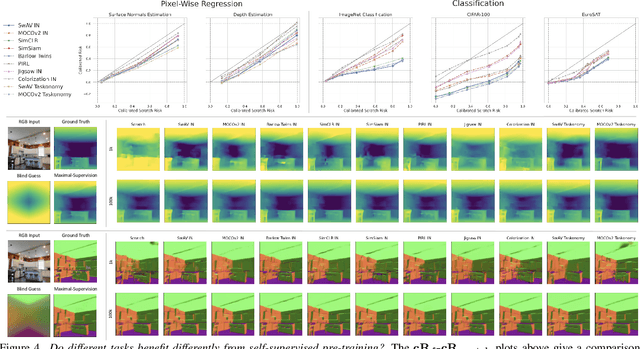
Transfer learning has witnessed remarkable progress in recent years, for example, with the introduction of augmentation-based contrastive self-supervised learning methods. While a number of large-scale empirical studies on the transfer performance of such models have been conducted, there is not yet an agreed-upon set of control baselines, evaluation practices, and metrics to report, which often hinders a nuanced and calibrated understanding of the real efficacy of the methods. We share an evaluation standard that aims to quantify and communicate transfer learning performance in an informative and accessible setup. This is done by baking a number of simple yet critical control baselines in the evaluation method, particularly the blind-guess (quantifying the dataset bias), scratch-model (quantifying the architectural contribution), and maximal-supervision (quantifying the upper-bound). To demonstrate how the evaluation standard can be employed, we provide an example empirical study investigating a few basic questions about self-supervised learning. For example, using this standard, the study shows the effectiveness of existing self-supervised pre-training methods is skewed towards image classification tasks versus dense pixel-wise predictions. In general, we encourage using/reporting the suggested control baselines in evaluating transfer learning in order to gain a more meaningful and informative understanding.