 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKandinsky 3: Text-to-Image Synthesis for Multifunctional Generative Framework
Oct 28, 2024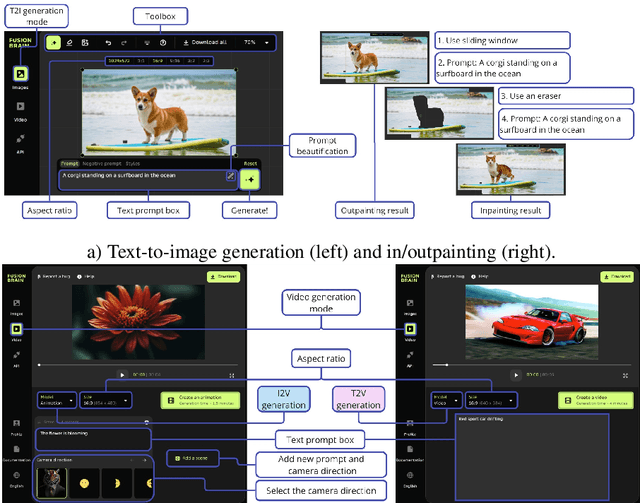


Text-to-image (T2I) diffusion models are popular for introducing image manipulation methods, such as editing, image fusion, inpainting, etc. At the same time, image-to-video (I2V) and text-to-video (T2V) models are also built on top of T2I models. We present Kandinsky 3, a novel T2I model based on latent diffusion, achieving a high level of quality and photorealism. The key feature of the new architecture is the simplicity and efficiency of its adaptation for many types of generation tasks. We extend the base T2I model for various applications and create a multifunctional generation system that includes text-guided inpainting/outpainting, image fusion, text-image fusion, image variations generation, I2V and T2V generation. We also present a distilled version of the T2I model, evaluating inference in 4 steps of the reverse process without reducing image quality and 3 times faster than the base model. We deployed a user-friendly demo system in which all the features can be tested in the public domain. Additionally, we released the source code and checkpoints for the Kandinsky 3 and extended models. Human evaluations show that Kandinsky 3 demonstrates one of the highest quality scores among open source generation systems.
Kandinsky 3.0 Technical Report
Dec 11, 2023



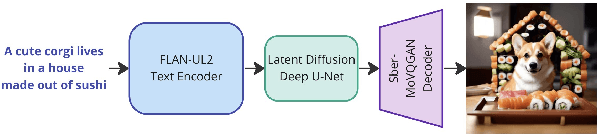
We present Kandinsky 3.0, a large-scale text-to-image generation model based on latent diffusion, continuing the series of text-to-image Kandinsky models and reflecting our progress to achieve higher quality and realism of image generation. Compared to previous versions of Kandinsky 2.x, Kandinsky 3.0 leverages a two times larger U-Net backbone, a ten times larger text encoder and removes diffusion mapping. We describe the architecture of the model, the data collection procedure, the training technique, and the production system of user interaction. We focus on the key components that, as we have identified as a result of a large number of experiments, had the most significant impact on improving the quality of our model compared to the others. By our side-by-side comparisons, Kandinsky becomes better in text understanding and works better on specific domains. Project page: https://ai-forever.github.io/Kandinsky-3
Task Discovery: Finding the Tasks that Neural Networks Generalize on
Dec 01, 2022



When developing deep learning models, we usually decide what task we want to solve then search for a model that generalizes well on the task. An intriguing question would be: what if, instead of fixing the task and searching in the model space, we fix the model and search in the task space? Can we find tasks that the model generalizes on? How do they look, or do they indicate anything? These are the questions we address in this paper. We propose a task discovery framework that automatically finds examples of such tasks via optimizing a generalization-based quantity called agreement score. We demonstrate that one set of images can give rise to many tasks on which neural networks generalize well. These tasks are a reflection of the inductive biases of the learning framework and the statistical patterns present in the data, thus they can make a useful tool for analysing the neural networks and their biases. As an example, we show that the discovered tasks can be used to automatically create adversarial train-test splits which make a model fail at test time, without changing the pixels or labels, but by only selecting how the datapoints should be split between the train and test sets. We end with a discussion on human-interpretability of the discovered tasks.
Simple Control Baselines for Evaluating Transfer Learning
Feb 07, 2022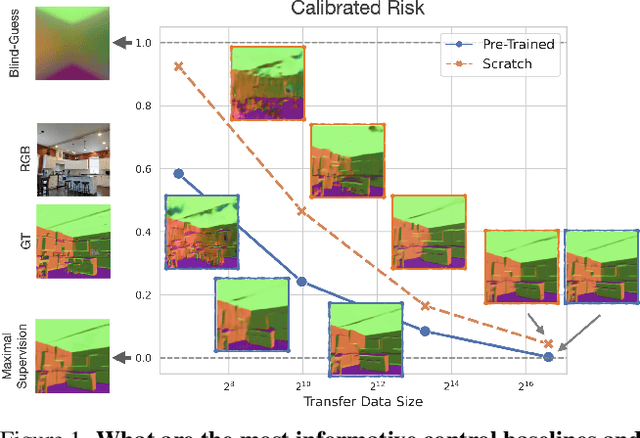
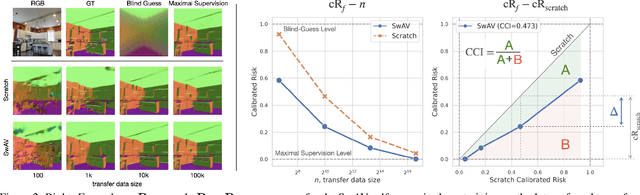
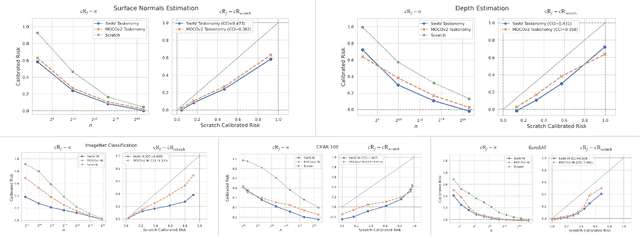
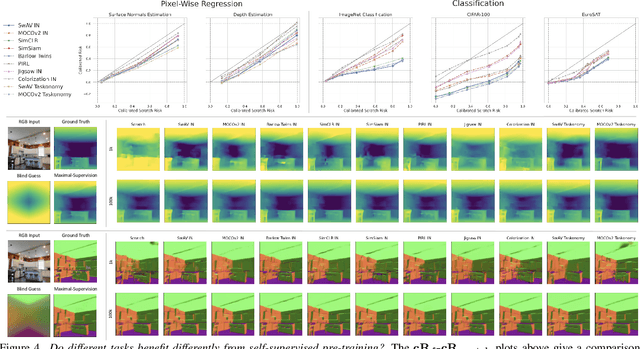
Transfer learning has witnessed remarkable progress in recent years, for example, with the introduction of augmentation-based contrastive self-supervised learning methods. While a number of large-scale empirical studies on the transfer performance of such models have been conducted, there is not yet an agreed-upon set of control baselines, evaluation practices, and metrics to report, which often hinders a nuanced and calibrated understanding of the real efficacy of the methods. We share an evaluation standard that aims to quantify and communicate transfer learning performance in an informative and accessible setup. This is done by baking a number of simple yet critical control baselines in the evaluation method, particularly the blind-guess (quantifying the dataset bias), scratch-model (quantifying the architectural contribution), and maximal-supervision (quantifying the upper-bound). To demonstrate how the evaluation standard can be employed, we provide an example empirical study investigating a few basic questions about self-supervised learning. For example, using this standard, the study shows the effectiveness of existing self-supervised pre-training methods is skewed towards image classification tasks versus dense pixel-wise predictions. In general, we encourage using/reporting the suggested control baselines in evaluating transfer learning in order to gain a more meaningful and informative understanding.