 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKandinsky 5.0: A Family of Foundation Models for Image and Video Generation
Nov 19, 2025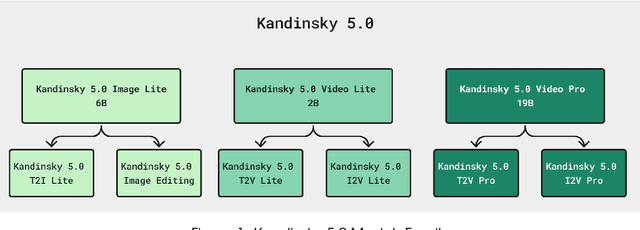

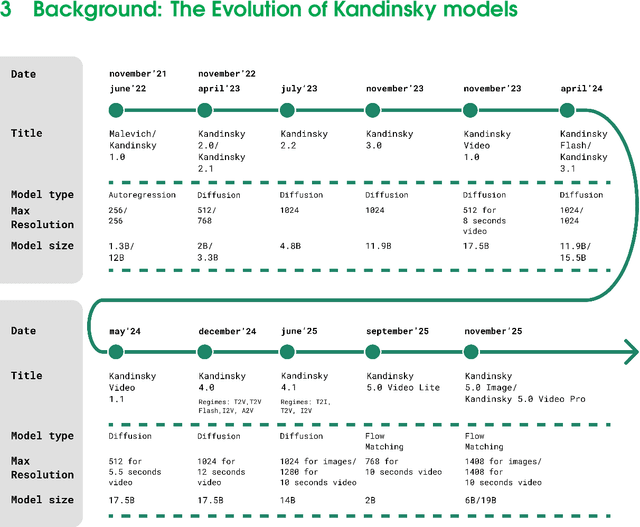
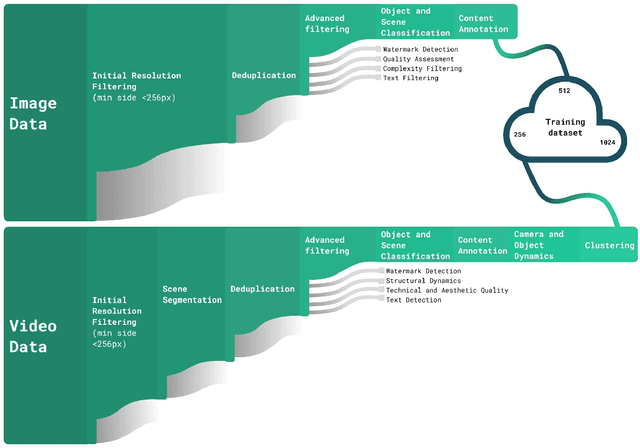
This report introduces Kandinsky 5.0, a family of state-of-the-art foundation models for high-resolution image and 10-second video synthesis. The framework comprises three core line-up of models: Kandinsky 5.0 Image Lite - a line-up of 6B parameter image generation models, Kandinsky 5.0 Video Lite - a fast and lightweight 2B parameter text-to-video and image-to-video models, and Kandinsky 5.0 Video Pro - 19B parameter models that achieves superior video generation quality. We provide a comprehensive review of the data curation lifecycle - including collection, processing, filtering and clustering - for the multi-stage training pipeline that involves extensive pre-training and incorporates quality-enhancement techniques such as self-supervised fine-tuning (SFT) and reinforcement learning (RL)-based post-training. We also present novel architectural, training, and inference optimizations that enable Kandinsky 5.0 to achieve high generation speeds and state-of-the-art performance across various tasks, as demonstrated by human evaluation. As a large-scale, publicly available generative framework, Kandinsky 5.0 leverages the full potential of its pre-training and subsequent stages to be adapted for a wide range of generative applications. We hope that this report, together with the release of our open-source code and training checkpoints, will substantially advance the development and accessibility of high-quality generative models for the research community.
Time-Correlated Video Bridge Matching
Oct 14, 2025Diffusion models excel in noise-to-data generation tasks, providing a mapping from a Gaussian distribution to a more complex data distribution. However they struggle to model translations between complex distributions, limiting their effectiveness in data-to-data tasks. While Bridge Matching (BM) models address this by finding the translation between data distributions, their application to time-correlated data sequences remains unexplored. This is a critical limitation for video generation and manipulation tasks, where maintaining temporal coherence is particularly important. To address this gap, we propose Time-Correlated Video Bridge Matching (TCVBM), a framework that extends BM to time-correlated data sequences in the video domain. TCVBM explicitly models inter-sequence dependencies within the diffusion bridge, directly incorporating temporal correlations into the sampling process. We compare our approach to classical methods based on bridge matching and diffusion models for three video-related tasks: frame interpolation, image-to-video generation, and video super-resolution. TCVBM achieves superior performance across multiple quantitative metrics, demonstrating enhanced generation quality and reconstruction fidelity.
$ abla$NABLA: Neighborhood Adaptive Block-Level Attention
Jul 17, 2025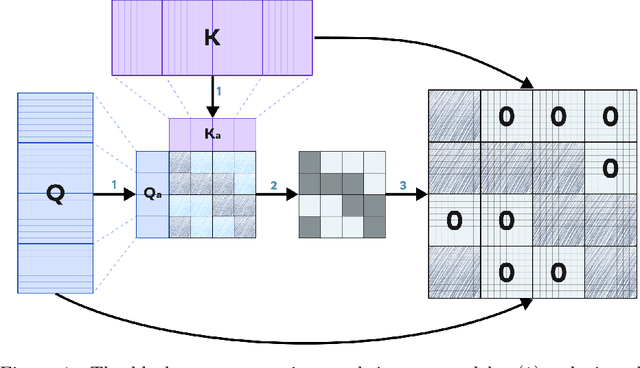
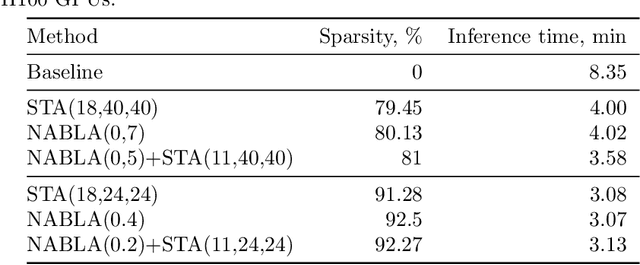
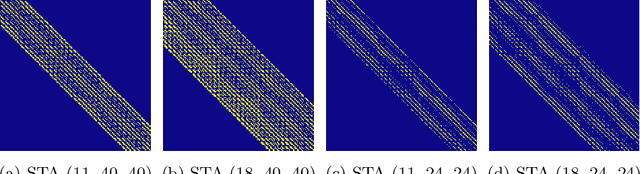
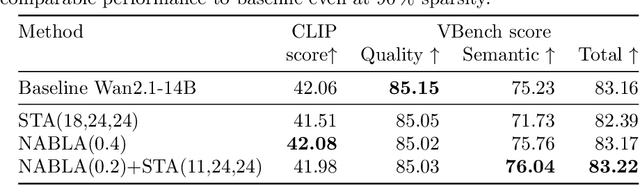
Recent progress in transformer-based architectures has demonstrated remarkable success in video generation tasks. However, the quadratic complexity of full attention mechanisms remains a critical bottleneck, particularly for high-resolution and long-duration video sequences. In this paper, we propose NABLA, a novel Neighborhood Adaptive Block-Level Attention mechanism that dynamically adapts to sparsity patterns in video diffusion transformers (DiTs). By leveraging block-wise attention with adaptive sparsity-driven threshold, NABLA reduces computational overhead while preserving generative quality. Our method does not require custom low-level operator design and can be seamlessly integrated with PyTorch's Flex Attention operator. Experiments demonstrate that NABLA achieves up to 2.7x faster training and inference compared to baseline almost without compromising quantitative metrics (CLIP score, VBench score, human evaluation score) and visual quality drop. The code and model weights are available here: https://github.com/gen-ai-team/Wan2.1-NABLA
VIVAT: Virtuous Improving VAE Training through Artifact Mitigation
Jun 09, 2025Variational Autoencoders (VAEs) remain a cornerstone of generative computer vision, yet their training is often plagued by artifacts that degrade reconstruction and generation quality. This paper introduces VIVAT, a systematic approach to mitigating common artifacts in KL-VAE training without requiring radical architectural changes. We present a detailed taxonomy of five prevalent artifacts - color shift, grid patterns, blur, corner and droplet artifacts - and analyze their root causes. Through straightforward modifications, including adjustments to loss weights, padding strategies, and the integration of Spatially Conditional Normalization, we demonstrate significant improvements in VAE performance. Our method achieves state-of-the-art results in image reconstruction metrics (PSNR and SSIM) across multiple benchmarks and enhances text-to-image generation quality, as evidenced by superior CLIP scores. By preserving the simplicity of the KL-VAE framework while addressing its practical challenges, VIVAT offers actionable insights for researchers and practitioners aiming to optimize VAE training.
CRAFT: Cultural Russian-Oriented Dataset Adaptation for Focused Text-to-Image Generation
May 07, 2025Despite the fact that popular text-to-image generation models cope well with international and general cultural queries, they have a significant knowledge gap regarding individual cultures. This is due to the content of existing large training datasets collected on the Internet, which are predominantly based on Western European or American popular culture. Meanwhile, the lack of cultural adaptation of the model can lead to incorrect results, a decrease in the generation quality, and the spread of stereotypes and offensive content. In an effort to address this issue, we examine the concept of cultural code and recognize the critical importance of its understanding by modern image generation models, an issue that has not been sufficiently addressed in the research community to date. We propose the methodology for collecting and processing the data necessary to form a dataset based on the cultural code, in particular the Russian one. We explore how the collected data affects the quality of generations in the national domain and analyze the effectiveness of our approach using the Kandinsky 3.1 text-to-image model. Human evaluation results demonstrate an increase in the level of awareness of Russian culture in the model.
* This is arxiv version of the paper which was accepted for the Doklady Mathematics Journal in 2024
RusCode: Russian Cultural Code Benchmark for Text-to-Image Generation
Feb 11, 2025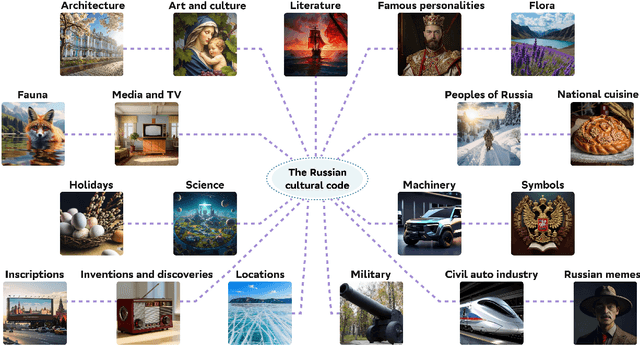
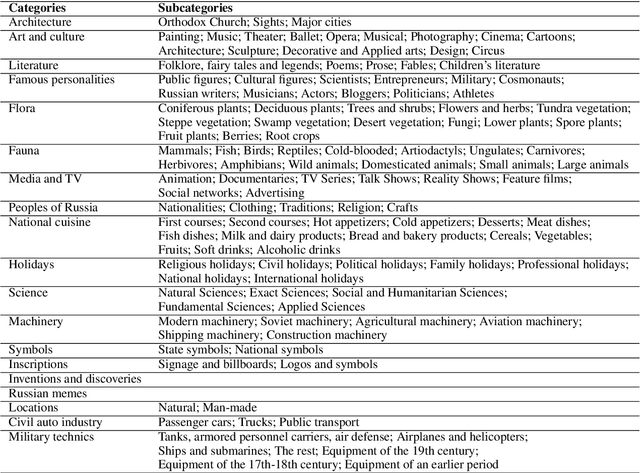
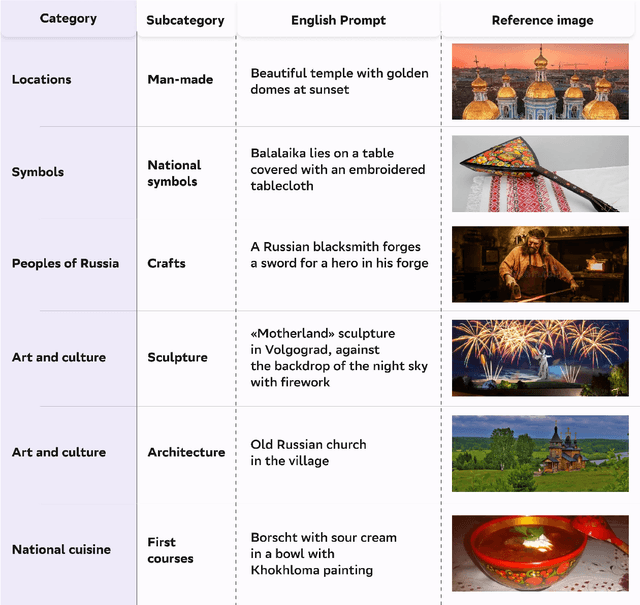
Text-to-image generation models have gained popularity among users around the world. However, many of these models exhibit a strong bias toward English-speaking cultures, ignoring or misrepresenting the unique characteristics of other language groups, countries, and nationalities. The lack of cultural awareness can reduce the generation quality and lead to undesirable consequences such as unintentional insult, and the spread of prejudice. In contrast to the field of natural language processing, cultural awareness in computer vision has not been explored as extensively. In this paper, we strive to reduce this gap. We propose a RusCode benchmark for evaluating the quality of text-to-image generation containing elements of the Russian cultural code. To do this, we form a list of 19 categories that best represent the features of Russian visual culture. Our final dataset consists of 1250 text prompts in Russian and their translations into English. The prompts cover a wide range of topics, including complex concepts from art, popular culture, folk traditions, famous people's names, natural objects, scientific achievements, etc. We present the results of a human evaluation of the side-by-side comparison of Russian visual concepts representations using popular generative models.
Kandinsky 3: Text-to-Image Synthesis for Multifunctional Generative Framework
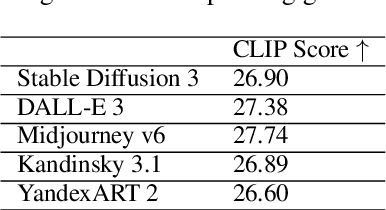
Oct 28, 2024

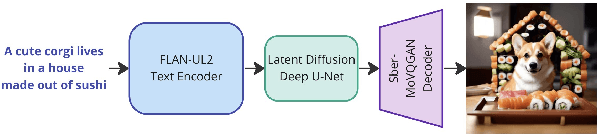

Text-to-image (T2I) diffusion models are popular for introducing image manipulation methods, such as editing, image fusion, inpainting, etc. At the same time, image-to-video (I2V) and text-to-video (T2V) models are also built on top of T2I models. We present Kandinsky 3, a novel T2I model based on latent diffusion, achieving a high level of quality and photorealism. The key feature of the new architecture is the simplicity and efficiency of its adaptation for many types of generation tasks. We extend the base T2I model for various applications and create a multifunctional generation system that includes text-guided inpainting/outpainting, image fusion, text-image fusion, image variations generation, I2V and T2V generation. We also present a distilled version of the T2I model, evaluating inference in 4 steps of the reverse process without reducing image quality and 3 times faster than the base model. We deployed a user-friendly demo system in which all the features can be tested in the public domain. Additionally, we released the source code and checkpoints for the Kandinsky 3 and extended models. Human evaluations show that Kandinsky 3 demonstrates one of the highest quality scores among open source generation systems.
Kandinsky 3.0 Technical Report
Dec 11, 2023



We present Kandinsky 3.0, a large-scale text-to-image generation model based on latent diffusion, continuing the series of text-to-image Kandinsky models and reflecting our progress to achieve higher quality and realism of image generation. Compared to previous versions of Kandinsky 2.x, Kandinsky 3.0 leverages a two times larger U-Net backbone, a ten times larger text encoder and removes diffusion mapping. We describe the architecture of the model, the data collection procedure, the training technique, and the production system of user interaction. We focus on the key components that, as we have identified as a result of a large number of experiments, had the most significant impact on improving the quality of our model compared to the others. By our side-by-side comparisons, Kandinsky becomes better in text understanding and works better on specific domains. Project page: https://ai-forever.github.io/Kandinsky-3
FusionFrames: Efficient Architectural Aspects for Text-to-Video Generation Pipeline
Nov 22, 2023


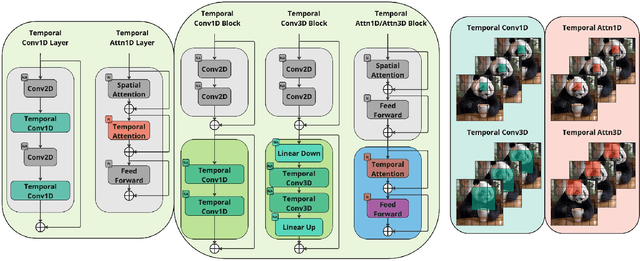
Multimedia generation approaches occupy a prominent place in artificial intelligence research. Text-to-image models achieved high-quality results over the last few years. However, video synthesis methods recently started to develop. This paper presents a new two-stage latent diffusion text-to-video generation architecture based on the text-to-image diffusion model. The first stage concerns keyframes synthesis to figure the storyline of a video, while the second one is devoted to interpolation frames generation to make movements of the scene and objects smooth. We compare several temporal conditioning approaches for keyframes generation. The results show the advantage of using separate temporal blocks over temporal layers in terms of metrics reflecting video generation quality aspects and human preference. The design of our interpolation model significantly reduces computational costs compared to other masked frame interpolation approaches. Furthermore, we evaluate different configurations of MoVQ-based video decoding scheme to improve consistency and achieve higher PSNR, SSIM, MSE, and LPIPS scores. Finally, we compare our pipeline with existing solutions and achieve top-2 scores overall and top-1 among open-source solutions: CLIPSIM = 0.2976 and FVD = 433.054. Project page: https://ai-forever.github.io/kandinsky-video/
On the properties of some low-parameter models for color reproduction in terms of spectrum transformations and coverage of a color triangle
Oct 21, 2021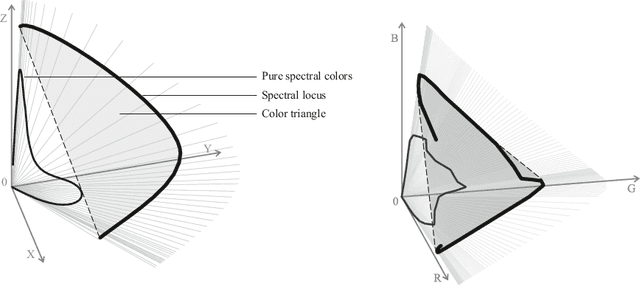
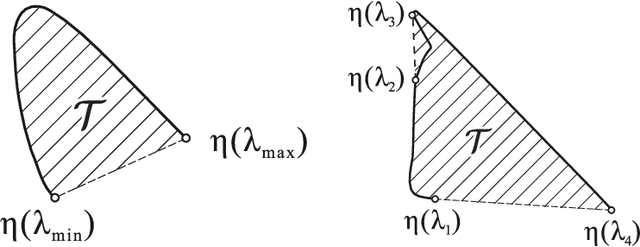
One of the classical approaches to solving color reproduction problems, such as color adaptation or color space transform, is the use of low-parameter spectral models. The strength of this approach is the ability to choose a set of properties that the model should have, be it a large coverage area of a color triangle, an accurate description of the addition or multiplication of spectra, knowing only the tristimulus corresponding to them. The disadvantage is that some of the properties of the mentioned spectral models are confirmed only experimentally. This work is devoted to the theoretical substantiation of various properties of spectral models. In particular, we prove that the banded model is the only model that simultaneously possesses the properties of closure under addition and multiplication. We also show that the Gaussian model is the limiting case of the von Mises model and prove that the set of protomers of the von Mises model unambiguously covers the color triangle in both the case of convex and non-convex spectral locus.