 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Evaluation of Russian-language Architectures
Nov 19, 2025Multimodal large language models (MLLMs) are currently at the center of research attention, showing rapid progress in scale and capabilities, yet their intelligence, limitations, and risks remain insufficiently understood. To address these issues, particularly in the context of the Russian language, where no multimodal benchmarks currently exist, we introduce Mera Multi, an open multimodal evaluation framework for Russian-spoken architectures. The benchmark is instruction-based and encompasses default text, image, audio, and video modalities, comprising 18 newly constructed evaluation tasks for both general-purpose models and modality-specific architectures (image-to-text, video-to-text, and audio-to-text). Our contributions include: (i) a universal taxonomy of multimodal abilities; (ii) 18 datasets created entirely from scratch with attention to Russian cultural and linguistic specificity, unified prompts, and metrics; (iii) baseline results for both closed-source and open-source models; (iv) a methodology for preventing benchmark leakage, including watermarking and licenses for private sets. While our current focus is on Russian, the proposed benchmark provides a replicable methodology for constructing multimodal benchmarks in typologically diverse languages, particularly within the Slavic language family.
HandReader: Advanced Techniques for Efficient Fingerspelling Recognition
May 15, 2025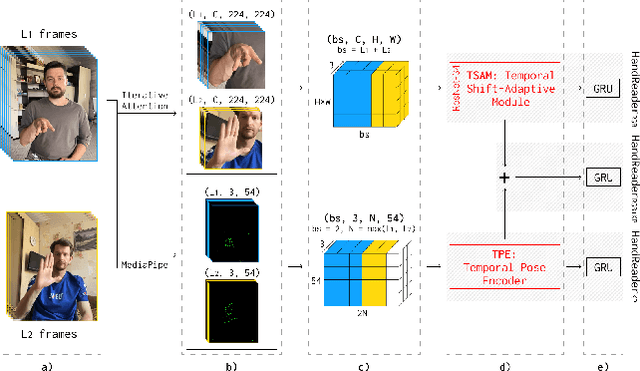
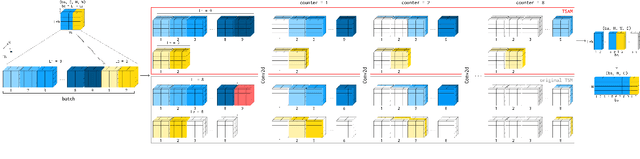
Fingerspelling is a significant component of Sign Language (SL), allowing the interpretation of proper names, characterized by fast hand movements during signing. Although previous works on fingerspelling recognition have focused on processing the temporal dimension of videos, there remains room for improving the accuracy of these approaches. This paper introduces HandReader, a group of three architectures designed to address the fingerspelling recognition task. HandReader$_{RGB}$ employs the novel Temporal Shift-Adaptive Module (TSAM) to process RGB features from videos of varying lengths while preserving important sequential information. HandReader$_{KP}$ is built on the proposed Temporal Pose Encoder (TPE) operated on keypoints as tensors. Such keypoints composition in a batch allows the encoder to pass them through 2D and 3D convolution layers, utilizing temporal and spatial information and accumulating keypoints coordinates. We also introduce HandReader_RGB+KP - architecture with a joint encoder to benefit from RGB and keypoint modalities. Each HandReader model possesses distinct advantages and achieves state-of-the-art results on the ChicagoFSWild and ChicagoFSWild+ datasets. Moreover, the models demonstrate high performance on the first open dataset for Russian fingerspelling, Znaki, presented in this paper. The Znaki dataset and HandReader pre-trained models are publicly available.
Logos as a Well-Tempered Pre-train for Sign Language Recognition
May 15, 2025



This paper examines two aspects of the isolated sign language recognition (ISLR) task. First, despite the availability of a number of datasets, the amount of data for most individual sign languages is limited. It poses the challenge of cross-language ISLR model training, including transfer learning. Second, similar signs can have different semantic meanings. It leads to ambiguity in dataset labeling and raises the question of the best policy for annotating such signs. To address these issues, this study presents Logos, a novel Russian Sign Language (RSL) dataset, the most extensive ISLR dataset by the number of signers and one of the largest available datasets while also the largest RSL dataset in size and vocabulary. It is shown that a model, pre-trained on the Logos dataset can be used as a universal encoder for other language SLR tasks, including few-shot learning. We explore cross-language transfer learning approaches and find that joint training using multiple classification heads benefits accuracy for the target lowresource datasets the most. The key feature of the Logos dataset is explicitly annotated visually similar sign groups. We show that explicitly labeling visually similar signs improves trained model quality as a visual encoder for downstream tasks. Based on the proposed contributions, we outperform current state-of-the-art results for the WLASL dataset and get competitive results for the AUTSL dataset, with a single stream model processing solely RGB video. The source code, dataset, and pre-trained models are publicly available.
RusCode: Russian Cultural Code Benchmark for Text-to-Image Generation
Feb 11, 2025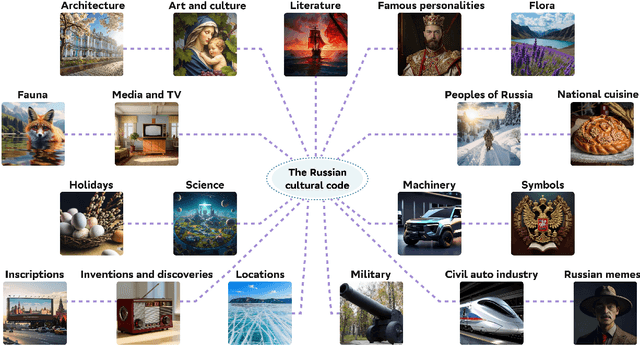
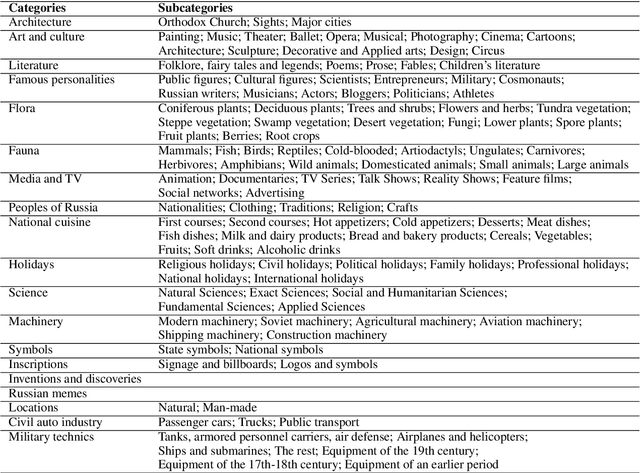
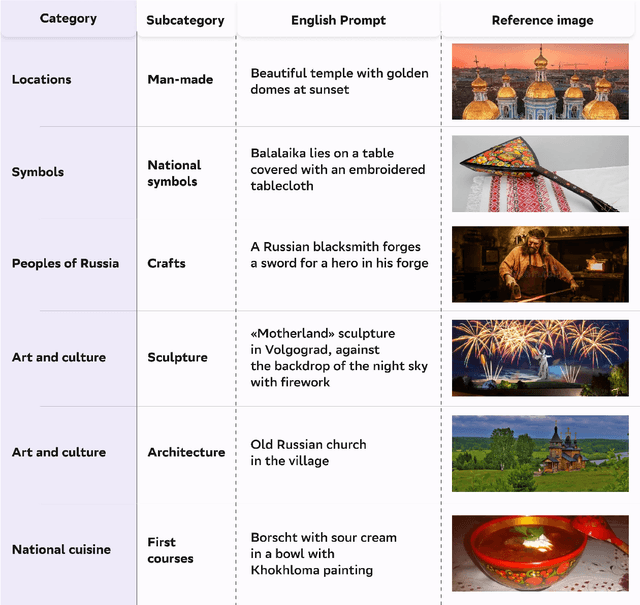
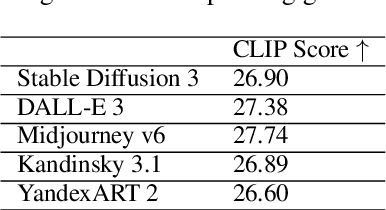
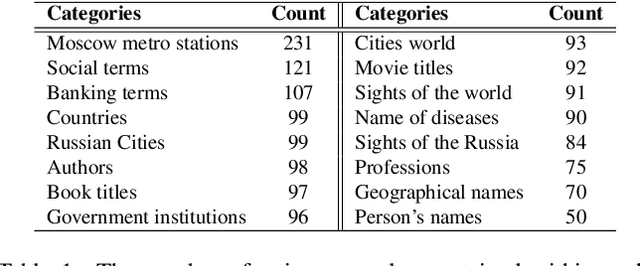
Text-to-image generation models have gained popularity among users around the world. However, many of these models exhibit a strong bias toward English-speaking cultures, ignoring or misrepresenting the unique characteristics of other language groups, countries, and nationalities. The lack of cultural awareness can reduce the generation quality and lead to undesirable consequences such as unintentional insult, and the spread of prejudice. In contrast to the field of natural language processing, cultural awareness in computer vision has not been explored as extensively. In this paper, we strive to reduce this gap. We propose a RusCode benchmark for evaluating the quality of text-to-image generation containing elements of the Russian cultural code. To do this, we form a list of 19 categories that best represent the features of Russian visual culture. Our final dataset consists of 1250 text prompts in Russian and their translations into English. The prompts cover a wide range of topics, including complex concepts from art, popular culture, folk traditions, famous people's names, natural objects, scientific achievements, etc. We present the results of a human evaluation of the side-by-side comparison of Russian visual concepts representations using popular generative models.
Training Strategies for Isolated Sign Language Recognition
Dec 16, 2024
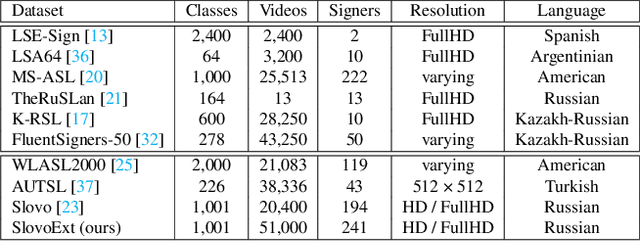
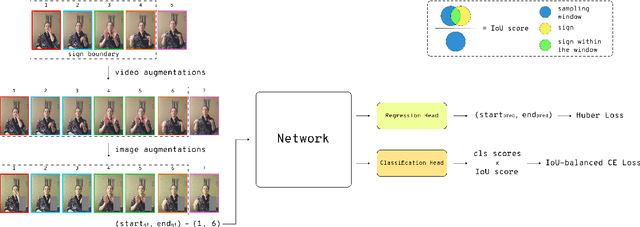
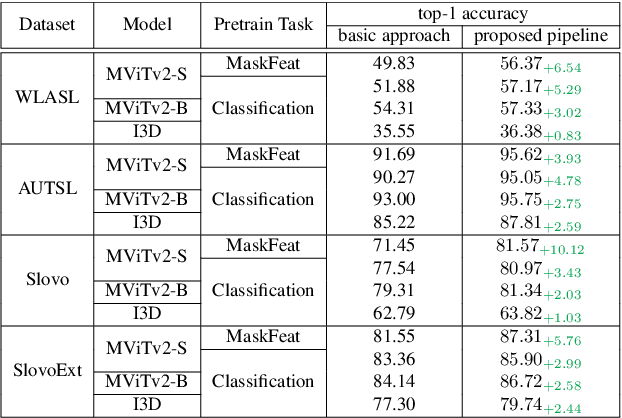
This paper introduces a comprehensive model training pipeline for Isolated Sign Language Recognition (ISLR) designed to accommodate the distinctive characteristics and constraints of the Sign Language (SL) domain. The constructed pipeline incorporates carefully selected image and video augmentations to tackle the challenges of low data quality and varying sign speeds. Including an additional regression head combined with IoU-balanced classification loss enhances the model's awareness of the gesture and simplifies capturing temporal information. Extensive experiments demonstrate that the developed training pipeline easily adapts to different datasets and architectures. Additionally, the ablation study shows that each proposed component expands the potential to consider ISLR task specifics. The presented strategies improve recognition performance on a broad set of ISLR benchmarks. Moreover, we achieved a state-of-the-art result on the WLASL and Slovo benchmarks with 1.63% and 14.12% improvements compared to the previous best solution, respectively.
HaGRIDv2: 1M Images for Static and Dynamic Hand Gesture Recognition
Dec 02, 2024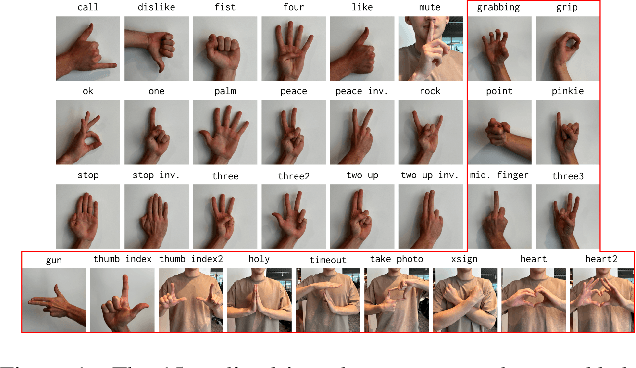
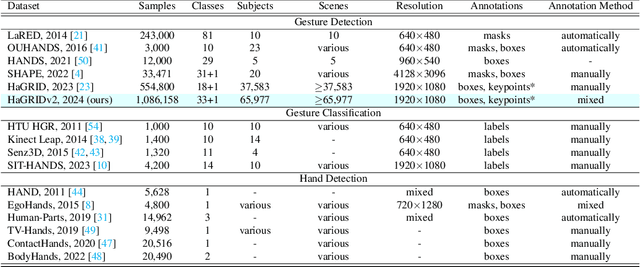
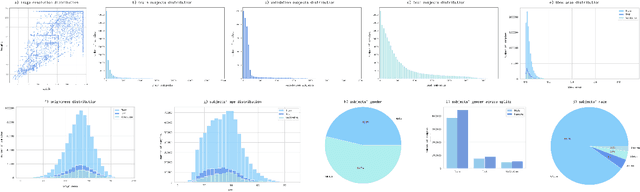
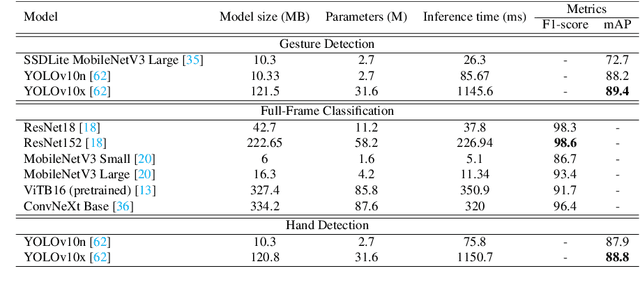
This paper proposes the second version of the widespread Hand Gesture Recognition dataset HaGRID -- HaGRIDv2. We cover 15 new gestures with conversation and control functions, including two-handed ones. Building on the foundational concepts proposed by HaGRID's authors, we implemented the dynamic gesture recognition algorithm and further enhanced it by adding three new groups of manipulation gestures. The ``no gesture" class was diversified by adding samples of natural hand movements, which allowed us to minimize false positives by 6 times. Combining extra samples with HaGRID, the received version outperforms the original in pre-training models for gesture-related tasks. Besides, we achieved the best generalization ability among gesture and hand detection datasets. In addition, the second version enhances the quality of the gestures generated by the diffusion model. HaGRIDv2, pre-trained models, and a dynamic gesture recognition algorithm are publicly available.
Bukva: Russian Sign Language Alphabet
Oct 11, 2024



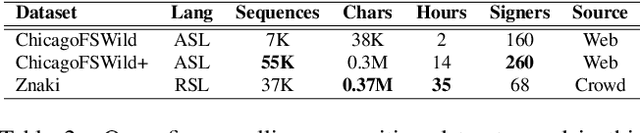
This paper investigates the recognition of the Russian fingerspelling alphabet, also known as the Russian Sign Language (RSL) dactyl. Dactyl is a component of sign languages where distinct hand movements represent individual letters of a written language. This method is used to spell words without specific signs, such as proper nouns or technical terms. The alphabet learning simulator is an essential isolated dactyl recognition application. There is a notable issue of data shortage in isolated dactyl recognition: existing Russian dactyl datasets lack subject heterogeneity, contain insufficient samples, or cover only static signs. We provide Bukva, the first full-fledged open-source video dataset for RSL dactyl recognition. It contains 3,757 videos with more than 101 samples for each RSL alphabet sign, including dynamic ones. We utilized crowdsourcing platforms to increase the subject's heterogeneity, resulting in the participation of 155 deaf and hard-of-hearing experts in the dataset creation. We use a TSM (Temporal Shift Module) block to handle static and dynamic signs effectively, achieving 83.6% top-1 accuracy with a real-time inference with CPU only. The dataset, demo code, and pre-trained models are publicly available.
PHNet: Patch-based Normalization for Portrait Harmonization
Mar 08, 2024



A common problem for composite images is the incompatibility of their foreground and background components. Image harmonization aims to solve this problem, making the whole image look more authentic and coherent. Most existing solutions predict lookup tables (LUTs) or reconstruct images, utilizing various attributes of composite images. Recent approaches have primarily focused on employing global transformations like normalization and color curve rendering to achieve visual consistency, and they often overlook the importance of local visual coherence. We present a patch-based harmonization network consisting of novel Patch-based normalization (PN) blocks and a feature extractor based on statistical color transfer. Extensive experiments demonstrate the network's high generalization capability for different domains. Our network achieves state-of-the-art results on the iHarmony4 dataset. Also, we created a new human portrait harmonization dataset based on FFHQ and checked the proposed method to show the generalization ability by achieving the best metrics on it. The benchmark experiments confirm that the suggested patch-based normalization block and feature extractor effectively improve the network's capability to harmonize portraits. Our code and model baselines are publicly available.
Slovo: Russian Sign Language Dataset
May 23, 2023One of the main challenges of the sign language recognition task is the difficulty of collecting a suitable dataset due to the gap between deaf and hearing society. In addition, the sign language in each country differs significantly, which obliges the creation of new data for each of them. This paper presents the Russian Sign Language (RSL) video dataset Slovo, produced using crowdsourcing platforms. The dataset contains 20,000 FullHD recordings, divided into 1,000 classes of RSL gestures received by 194 signers. We also provide the entire dataset creation pipeline, from data collection to video annotation, with the following demo application. Several neural networks are trained and evaluated on the Slovo to demonstrate its teaching ability. Proposed data and pre-trained models are publicly available.
EasyPortrait -- Face Parsing and Portrait Segmentation Dataset
May 02, 2023Recently, due to COVID-19 and the growing demand for remote work, video conferencing apps have become especially widespread. The most valuable features of video chats are real-time background removal and face beautification. While solving these tasks, computer vision researchers face the problem of having relevant data for the training stage. There is no large dataset with high-quality labeled and diverse images of people in front of a laptop or smartphone camera to train a lightweight model without additional approaches. To boost the progress in this area, we provide a new image dataset, EasyPortrait, for portrait segmentation and face parsing tasks. It contains 20,000 primarily indoor photos of 8,377 unique users, and fine-grained segmentation masks separated into 9 classes. Images are collected and labeled from crowdsourcing platforms. Unlike most face parsing datasets, in EasyPortrait, the beard is not considered part of the skin mask, and the inside area of the mouth is separated from the teeth. These features allow using EasyPortrait for skin enhancement and teeth whitening tasks. This paper describes the pipeline for creating a large-scale and clean image segmentation dataset using crowdsourcing platforms without additional synthetic data. Moreover, we trained several models on EasyPortrait and showed experimental results. Proposed dataset and trained models are publicly available.