 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRusCode: Russian Cultural Code Benchmark for Text-to-Image Generation
Feb 11, 2025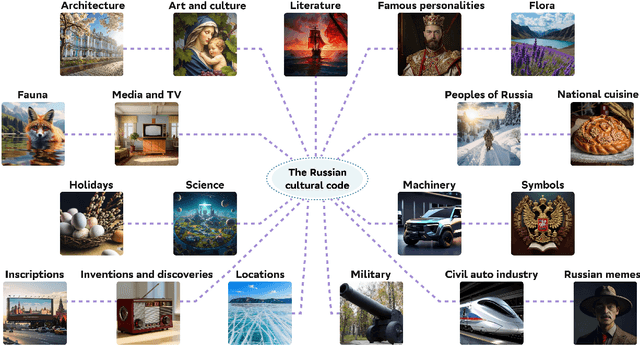
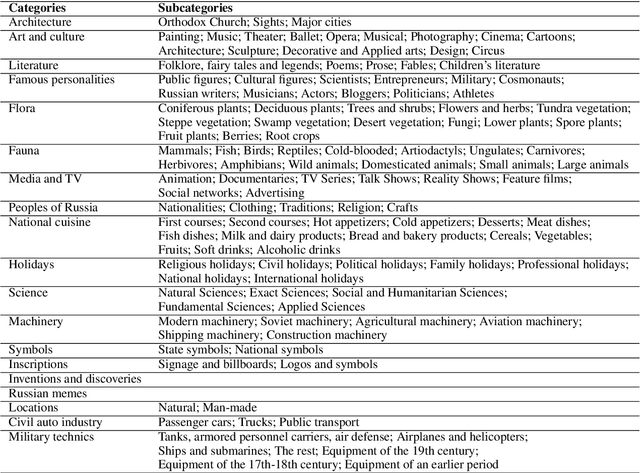
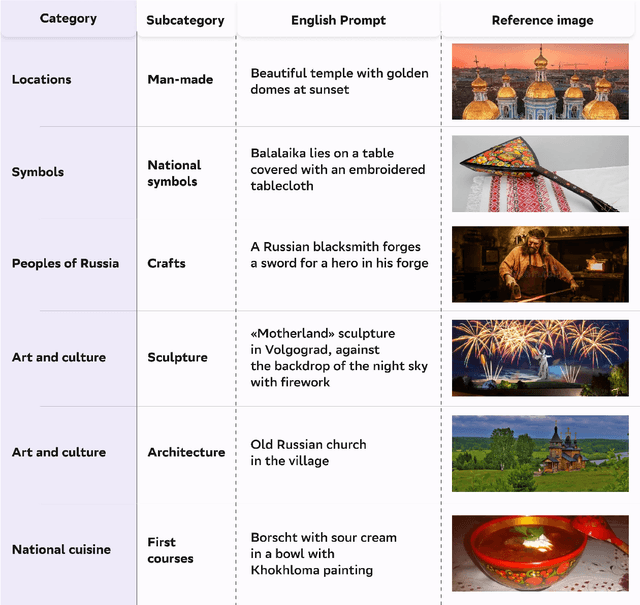
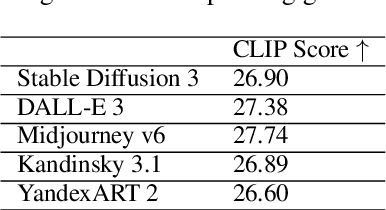
Text-to-image generation models have gained popularity among users around the world. However, many of these models exhibit a strong bias toward English-speaking cultures, ignoring or misrepresenting the unique characteristics of other language groups, countries, and nationalities. The lack of cultural awareness can reduce the generation quality and lead to undesirable consequences such as unintentional insult, and the spread of prejudice. In contrast to the field of natural language processing, cultural awareness in computer vision has not been explored as extensively. In this paper, we strive to reduce this gap. We propose a RusCode benchmark for evaluating the quality of text-to-image generation containing elements of the Russian cultural code. To do this, we form a list of 19 categories that best represent the features of Russian visual culture. Our final dataset consists of 1250 text prompts in Russian and their translations into English. The prompts cover a wide range of topics, including complex concepts from art, popular culture, folk traditions, famous people's names, natural objects, scientific achievements, etc. We present the results of a human evaluation of the side-by-side comparison of Russian visual concepts representations using popular generative models.
MERA: A Comprehensive LLM Evaluation in Russian
Jan 12, 2024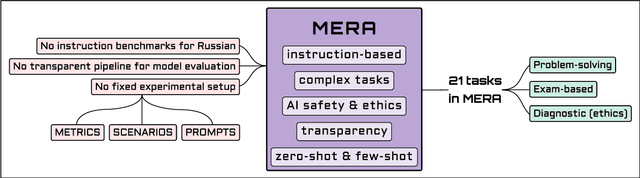
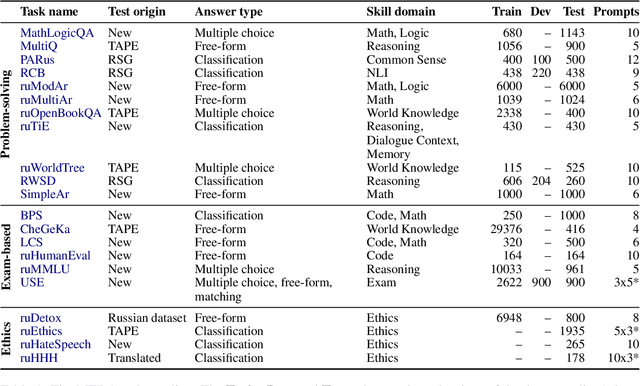

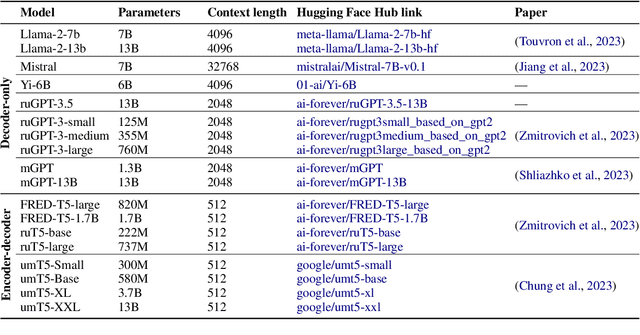
Over the past few years, one of the most notable advancements in AI research has been in foundation models (FMs), headlined by the rise of language models (LMs). As the models' size increases, LMs demonstrate enhancements in measurable aspects and the development of new qualitative features. However, despite researchers' attention and the rapid growth in LM application, the capabilities, limitations, and associated risks still need to be better understood. To address these issues, we introduce an open Multimodal Evaluation of Russian-language Architectures (MERA), a new instruction benchmark for evaluating foundation models oriented towards the Russian language. The benchmark encompasses 21 evaluation tasks for generative models in 11 skill domains and is designed as a black-box test to ensure the exclusion of data leakage. The paper introduces a methodology to evaluate FMs and LMs in zero- and few-shot fixed instruction settings that can be extended to other modalities. We propose an evaluation methodology, an open-source code base for the MERA assessment, and a leaderboard with a submission system. We evaluate open LMs as baselines and find that they are still far behind the human level. We publicly release MERA to guide forthcoming research, anticipate groundbreaking model features, standardize the evaluation procedure, and address potential societal drawbacks.