 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Evaluation of Russian-language Architectures
Nov 19, 2025Multimodal large language models (MLLMs) are currently at the center of research attention, showing rapid progress in scale and capabilities, yet their intelligence, limitations, and risks remain insufficiently understood. To address these issues, particularly in the context of the Russian language, where no multimodal benchmarks currently exist, we introduce Mera Multi, an open multimodal evaluation framework for Russian-spoken architectures. The benchmark is instruction-based and encompasses default text, image, audio, and video modalities, comprising 18 newly constructed evaluation tasks for both general-purpose models and modality-specific architectures (image-to-text, video-to-text, and audio-to-text). Our contributions include: (i) a universal taxonomy of multimodal abilities; (ii) 18 datasets created entirely from scratch with attention to Russian cultural and linguistic specificity, unified prompts, and metrics; (iii) baseline results for both closed-source and open-source models; (iv) a methodology for preventing benchmark leakage, including watermarking and licenses for private sets. While our current focus is on Russian, the proposed benchmark provides a replicable methodology for constructing multimodal benchmarks in typologically diverse languages, particularly within the Slavic language family.
MERA Code: A Unified Framework for Evaluating Code Generation Across Tasks
Jul 16, 2025Advancements in LLMs have enhanced task automation in software engineering; however, current evaluations primarily focus on natural language tasks, overlooking code quality. Most benchmarks prioritize high-level reasoning over executable code and real-world performance, leaving gaps in understanding true capabilities and risks associated with these models in production. To address this issue, we propose MERA Code, a new addition to the MERA benchmark family, specifically focused on evaluating code for the latest code generation LLMs in Russian. This benchmark includes 11 evaluation tasks that span 8 programming languages. Our proposed evaluation methodology features a taxonomy that outlines the practical coding skills necessary for models to complete these tasks. The benchmark comprises an open-source codebase for users to conduct MERA assessments, a scoring system compatible with various programming environments, and a platform featuring a leaderboard and submission system. We evaluate open LLMs and frontier API models, analyzing their limitations in terms of practical coding tasks in non-English languages. We are publicly releasing MERA to guide future research, anticipate groundbreaking features in model development, and standardize evaluation procedures.
GigaChat Family: Efficient Russian Language Modeling Through Mixture of Experts Architecture
Jun 11, 2025



Generative large language models (LLMs) have become crucial for modern NLP research and applications across various languages. However, the development of foundational models specifically tailored to the Russian language has been limited, primarily due to the significant computational resources required. This paper introduces the GigaChat family of Russian LLMs, available in various sizes, including base models and instruction-tuned versions. We provide a detailed report on the model architecture, pre-training process, and experiments to guide design choices. In addition, we evaluate their performance on Russian and English benchmarks and compare GigaChat with multilingual analogs. The paper presents a system demonstration of the top-performing models accessible via an API, a Telegram bot, and a Web interface. Furthermore, we have released three open GigaChat models in open-source (https://huggingface.co/ai-sage), aiming to expand NLP research opportunities and support the development of industrial solutions for the Russian language.
Eye of Judgement: Dissecting the Evaluation of Russian-speaking LLMs with POLLUX
May 30, 2025We introduce POLLUX, a comprehensive open-source benchmark designed to evaluate the generative capabilities of large language models (LLMs) in Russian. Our main contribution is a novel evaluation methodology that enhances the interpretability of LLM assessment. For each task type, we define a set of detailed criteria and develop a scoring protocol where models evaluate responses and provide justifications for their ratings. This enables transparent, criteria-driven evaluation beyond traditional resource-consuming, side-by-side human comparisons. POLLUX includes a detailed, fine-grained taxonomy of 35 task types covering diverse generative domains such as code generation, creative writing, and practical assistant use cases, totaling 2,100 manually crafted and professionally authored prompts. Each task is categorized by difficulty (easy/medium/hard), with experts constructing the dataset entirely from scratch. We also release a family of LLM-as-a-Judge (7B and 32B) evaluators trained for nuanced assessment of generative outputs. This approach provides scalable, interpretable evaluation and annotation tools for model development, effectively replacing costly and less precise human judgments.
REPA: Russian Error Types Annotation for Evaluating Text Generation and Judgment Capabilities
Mar 17, 2025Recent advances in large language models (LLMs) have introduced the novel paradigm of using LLMs as judges, where an LLM evaluates and scores the outputs of another LLM, which often correlates highly with human preferences. However, the use of LLM-as-a-judge has been primarily studied in English. In this paper, we evaluate this framework in Russian by introducing the Russian Error tyPes Annotation dataset (REPA), a dataset of 1k user queries and 2k LLM-generated responses. Human annotators labeled each response pair expressing their preferences across ten specific error types, as well as selecting an overall preference. We rank six generative LLMs across the error types using three rating systems based on human preferences. We also evaluate responses using eight LLM judges in zero-shot and few-shot settings. We describe the results of analyzing the judges and position and length biases. Our findings reveal a notable gap between LLM judge performance in Russian and English. However, rankings based on human and LLM preferences show partial alignment, suggesting that while current LLM judges struggle with fine-grained evaluation in Russian, there is potential for improvement.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
The Russian-focused embedders' exploration: ruMTEB benchmark and Russian embedding model design
Aug 22, 2024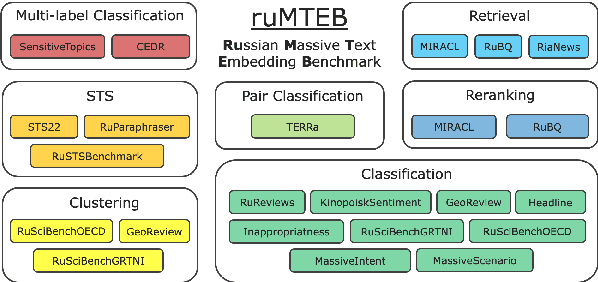



Embedding models play a crucial role in Natural Language Processing (NLP) by creating text embeddings used in various tasks such as information retrieval and assessing semantic text similarity. This paper focuses on research related to embedding models in the Russian language. It introduces a new Russian-focused embedding model called ru-en-RoSBERTa and the ruMTEB benchmark, the Russian version extending the Massive Text Embedding Benchmark (MTEB). Our benchmark includes seven categories of tasks, such as semantic textual similarity, text classification, reranking, and retrieval. The research also assesses a representative set of Russian and multilingual models on the proposed benchmark. The findings indicate that the new model achieves results that are on par with state-of-the-art models in Russian. We release the model ru-en-RoSBERTa, and the ruMTEB framework comes with open-source code, integration into the original framework and a public leaderboard.
Long Input Benchmark for Russian Analysis
Aug 05, 2024
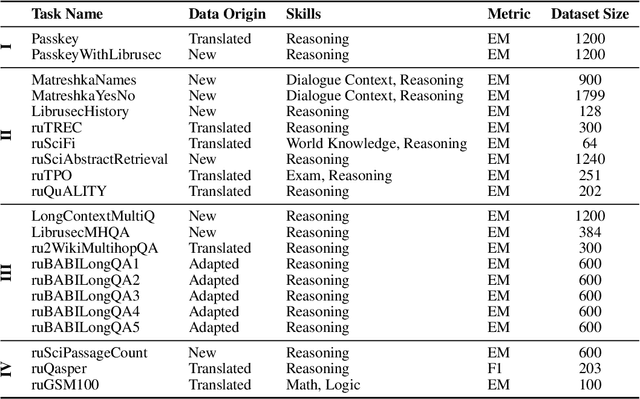
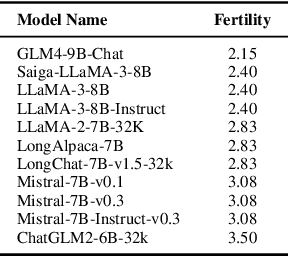
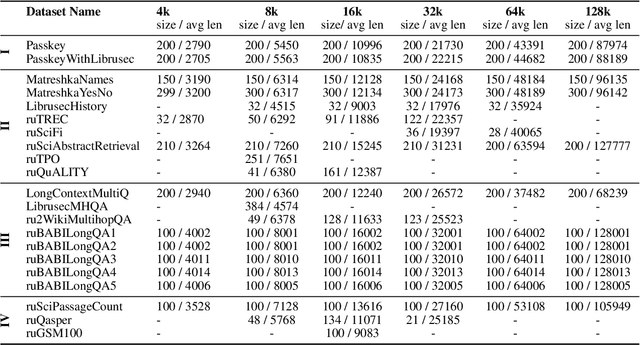
Recent advancements in Natural Language Processing (NLP) have fostered the development of Large Language Models (LLMs) that can solve an immense variety of tasks. One of the key aspects of their application is their ability to work with long text documents and to process long sequences of tokens. This has created a demand for proper evaluation of long-context understanding. To address this need for the Russian language, we propose LIBRA (Long Input Benchmark for Russian Analysis), which comprises 21 adapted datasets to study the LLM's abilities to understand long texts thoroughly. The tests are divided into four complexity groups and allow the evaluation of models across various context lengths ranging from 4k up to 128k tokens. We provide the open-source datasets, codebase, and public leaderboard for LIBRA to guide forthcoming research.
RuBLiMP: Russian Benchmark of Linguistic Minimal Pairs
Jun 27, 2024Minimal pairs are a well-established approach to evaluating the grammatical knowledge of language models. However, existing resources for minimal pairs address a limited number of languages and lack diversity of language-specific grammatical phenomena. This paper introduces the Russian Benchmark of Linguistic Minimal Pairs (RuBLiMP), which includes 45k pairs of sentences that differ in grammaticality and isolate a morphological, syntactic, or semantic phenomenon. In contrast to existing benchmarks of linguistic minimal pairs, RuBLiMP is created by applying linguistic perturbations to automatically annotated sentences from open text corpora and carefully curating test data. We describe the data collection protocol and present the results of evaluating 25 language models in various scenarios. We find that the widely used language models for Russian are sensitive to morphological and agreement-oriented contrasts but fall behind humans on phenomena requiring understanding of structural relations, negation, transitivity, and tense. RuBLiMP, the codebase, and other materials are publicly available.
MERA: A Comprehensive LLM Evaluation in Russian
Jan 12, 2024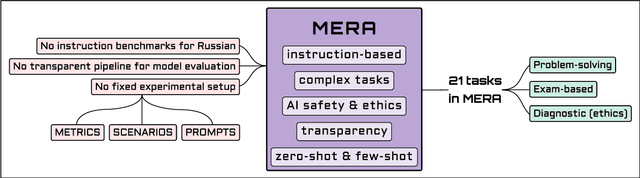
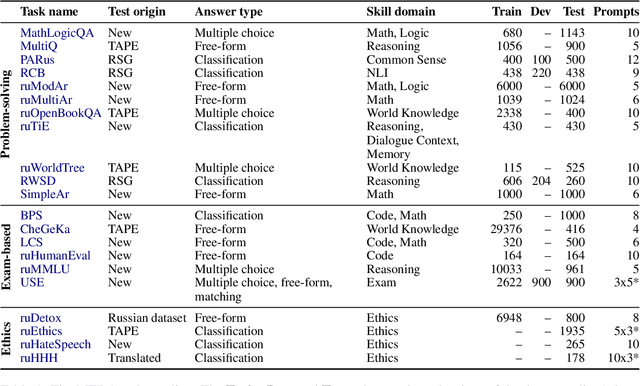

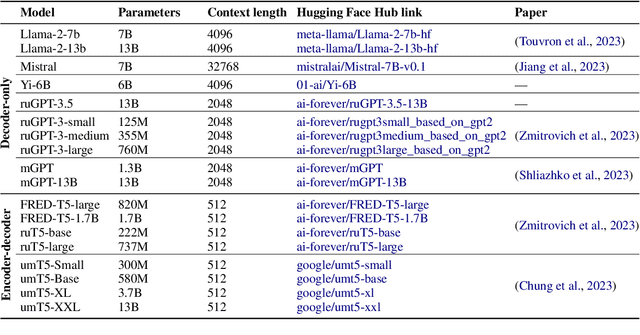
Over the past few years, one of the most notable advancements in AI research has been in foundation models (FMs), headlined by the rise of language models (LMs). As the models' size increases, LMs demonstrate enhancements in measurable aspects and the development of new qualitative features. However, despite researchers' attention and the rapid growth in LM application, the capabilities, limitations, and associated risks still need to be better understood. To address these issues, we introduce an open Multimodal Evaluation of Russian-language Architectures (MERA), a new instruction benchmark for evaluating foundation models oriented towards the Russian language. The benchmark encompasses 21 evaluation tasks for generative models in 11 skill domains and is designed as a black-box test to ensure the exclusion of data leakage. The paper introduces a methodology to evaluate FMs and LMs in zero- and few-shot fixed instruction settings that can be extended to other modalities. We propose an evaluation methodology, an open-source code base for the MERA assessment, and a leaderboard with a submission system. We evaluate open LMs as baselines and find that they are still far behind the human level. We publicly release MERA to guide forthcoming research, anticipate groundbreaking model features, standardize the evaluation procedure, and address potential societal drawbacks.