 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Input Benchmark for Russian Analysis
Aug 05, 2024
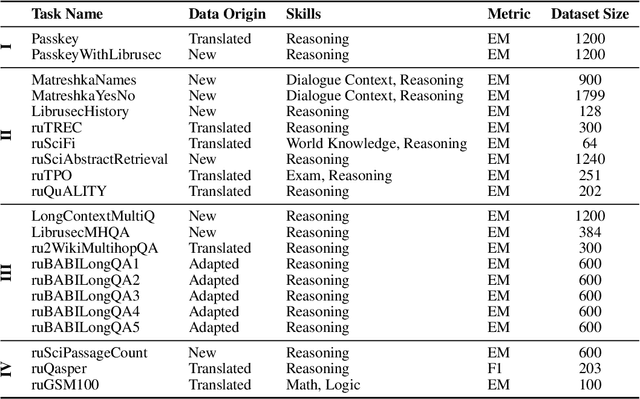
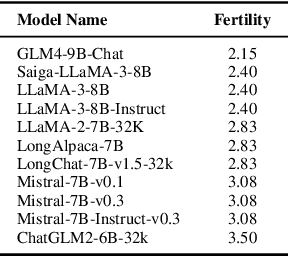
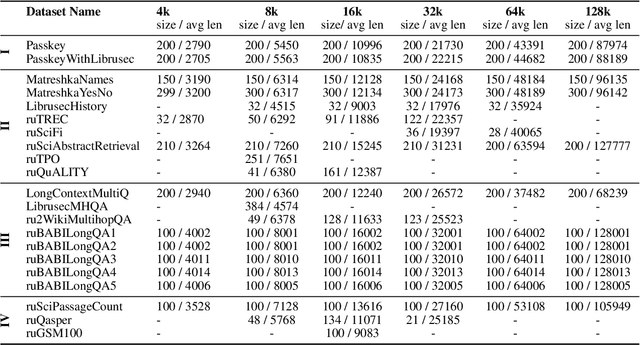
Recent advancements in Natural Language Processing (NLP) have fostered the development of Large Language Models (LLMs) that can solve an immense variety of tasks. One of the key aspects of their application is their ability to work with long text documents and to process long sequences of tokens. This has created a demand for proper evaluation of long-context understanding. To address this need for the Russian language, we propose LIBRA (Long Input Benchmark for Russian Analysis), which comprises 21 adapted datasets to study the LLM's abilities to understand long texts thoroughly. The tests are divided into four complexity groups and allow the evaluation of models across various context lengths ranging from 4k up to 128k tokens. We provide the open-source datasets, codebase, and public leaderboard for LIBRA to guide forthcoming research.
Teaching a Massive Open Online Course on Natural Language Processing
May 04, 2021

This paper presents a new Massive Open Online Course on Natural Language Processing, targeted at non-English speaking students. The course lasts 12 weeks; every week consists of lectures, practical sessions, and quiz assignments. Three weeks out of 12 are followed by Kaggle-style coding assignments. Our course intends to serve multiple purposes: (i) familiarize students with the core concepts and methods in NLP, such as language modeling or word or sentence representations, (ii) show that recent advances, including pre-trained Transformer-based models, are built upon these concepts; (iii) introduce architectures for most demanded real-life applications, (iv) develop practical skills to process texts in multiple languages. The course was prepared and recorded during 2020, launched by the end of the year, and in early 2021 has received positive feedback.