 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$μ$VLA: On Recurrent Memory for Partially Observable Manipulation in VLA Models
Jun 10, 2026Vision-language-action (VLA) models predict chunks of future actions from the current observation, an assumption that fails under partial observability, where decisions depend on information no longer visible. Existing memory-augmented VLAs simultaneously introduce recurrence, retrieval, compression modules, auxiliary objectives, hierarchical memory, or task-specific architectural changes, so the contribution of recurrence itself remains entangled with surrounding machinery. We present a controlled isolation study of recurrence in a strong pretrained VLA backbone. Our formulation augments the transformer with a small set of learnable memory tokens carried across timesteps and updated through self-attention, trained end to end with truncated backpropagation through time, with no auxiliary losses and no architectural changes. We instantiate this as $μ$VLA, a family of OpenVLA-OFT variants parameterized by memory width m, TBPTT length K, and the memory update rule (cross-step gradients or a detached EMA), so that recurrence is the only varying factor. On MIKASA-Robo, $μ$VLA improves average success rate on five training tasks from 0.42 to 0.84 at the strongest setting and reaches 0.23 on held-out tasks with the same memory structure versus 0.07 for the memoryless baseline. On tasks requiring different memory structure, performance remains near baseline. On LIBERO, the strongest recurrent variant achieves 96.2% average success, indicating no regression under full observability. We interpret these results as a calibration of the capability envelope of minimal in-backbone recurrence, identifying the regime in which it is sufficient and the regime where additional memory structure is required. Demos and videos can be found in https://avanturist322.github.io/mu-vla/.
Revisiting Tree Search for LLMs: Gumbel and Sequential Halving for Budget-Scalable Reasoning
Mar 22, 2026Neural tree search is a powerful decision-making algorithm widely used in complex domains such as game playing and model-based reinforcement learning. Recent work has applied AlphaZero-style tree search to enhance the reasoning capabilities of Large Language Models (LLMs) during inference, but we find that this approach suffers from a scaling failure: on GSM8K and Game24, accuracy drops as the search budget increases. In this paper, we present ReSCALE, an adaptation of Gumbel AlphaZero MCTS that replaces Dirichlet noise and PUCT selection with Gumbel sampling and Sequential Halving, restoring monotonic scaling without changes to the model or its training. ReSCALE reaches 58.4\% on GSM8K and 85.3\% on Game24 at budgets where the baseline degrades. Ablations confirm that Sequential Halving is the primary driver of the improvement.
GradMem: Learning to Write Context into Memory with Test-Time Gradient Descent
Mar 14, 2026Many large language model applications require conditioning on long contexts. Transformers typically support this by storing a large per-layer KV-cache of past activations, which incurs substantial memory overhead. A desirable alternative is ompressive memory: read a context once, store it in a compact state, and answer many queries from that state. We study this in a context removal setting, where the model must generate an answer without access to the original context at inference time. We introduce GradMem, which writes context into memory via per-sample test-time optimization. Given a context, GradMem performs a few steps of gradient descent on a small set of prefix memory tokens while keeping model weights frozen. GradMem explicitly optimizes a model-level self-supervised context reconstruction loss, resulting in a loss-driven write operation with iterative error correction, unlike forward-only methods. On associative key--value retrieval, GradMem outperforms forward-only memory writers with the same memory size, and additional gradient steps scale capacity much more effectively than repeated forward writes. We further show that GradMem transfers beyond synthetic benchmarks: with pretrained language models, it attains competitive results on natural language tasks including bAbI and SQuAD variants, relying only on information encoded in memory.
Diagonal Batching Unlocks Parallelism in Recurrent Memory Transformers for Long Contexts
Jun 05, 2025Transformer models struggle with long-context inference due to their quadratic time and linear memory complexity. Recurrent Memory Transformers (RMTs) offer a solution by reducing the asymptotic cost to linear time and constant memory usage. However, their memory update mechanism leads to sequential execution, causing a performance bottleneck. We introduce Diagonal Batching, a scheduling scheme that unlocks parallelism across segments in RMTs while preserving exact recurrence. This approach eliminates the sequential constraint, enabling efficient GPU inference even for single long-context inputs without complex batching and pipelining techniques. Because the technique is purely a run-time computation reordering, existing RMT models adopt it with no retraining. Applied to a LLaMA-1B ARMT model, Diagonal Batching yields a 3.3x speedup over standard full-attention LLaMA-1B and a 1.8x speedup over the sequential RMT implementation on 131,072-token sequences. By removing sequential bottleneck, Diagonal Batching reduces inference cost and latency, thereby strengthening RMTs as a practical solution for real-world, long-context applications.
Cramming 1568 Tokens into a Single Vector and Back Again: Exploring the Limits of Embedding Space Capacity
Feb 18, 2025A range of recent works addresses the problem of compression of sequence of tokens into a shorter sequence of real-valued vectors to be used as inputs instead of token embeddings or key-value cache. These approaches allow to reduce the amount of compute in existing language models. Despite relying on powerful models as encoders, the maximum attainable lossless compression ratio is typically not higher than x10. This fact is highly intriguing because, in theory, the maximum information capacity of large real-valued vectors is far beyond the presented rates even for 16-bit precision and a modest vector size. In this work, we explore the limits of compression by replacing the encoder with a per-sample optimization procedure. We show that vectors with compression ratios up to x1500 exist, which highlights two orders of magnitude gap between existing and practically attainable solutions. Furthermore, we empirically show that the compression limits are determined not by the length of the input but by the amount of uncertainty to be reduced, namely, the cross-entropy loss on this sequence without any conditioning. The obtained limits highlight the substantial gap between the theoretical capacity of input embeddings and their practical utilization, suggesting significant room for optimization in model design.
Long Input Benchmark for Russian Analysis
Aug 05, 2024
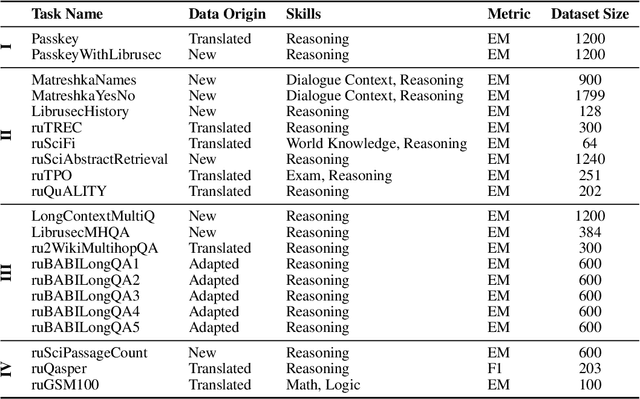
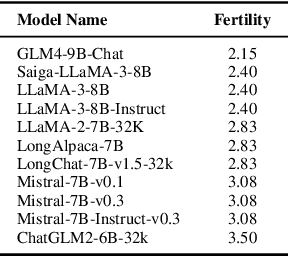
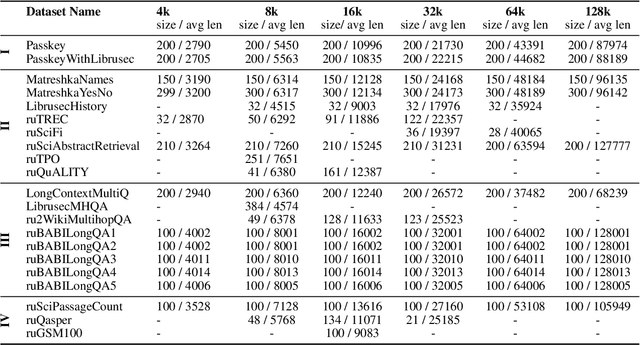
Recent advancements in Natural Language Processing (NLP) have fostered the development of Large Language Models (LLMs) that can solve an immense variety of tasks. One of the key aspects of their application is their ability to work with long text documents and to process long sequences of tokens. This has created a demand for proper evaluation of long-context understanding. To address this need for the Russian language, we propose LIBRA (Long Input Benchmark for Russian Analysis), which comprises 21 adapted datasets to study the LLM's abilities to understand long texts thoroughly. The tests are divided into four complexity groups and allow the evaluation of models across various context lengths ranging from 4k up to 128k tokens. We provide the open-source datasets, codebase, and public leaderboard for LIBRA to guide forthcoming research.
Associative Recurrent Memory Transformer
Jul 05, 2024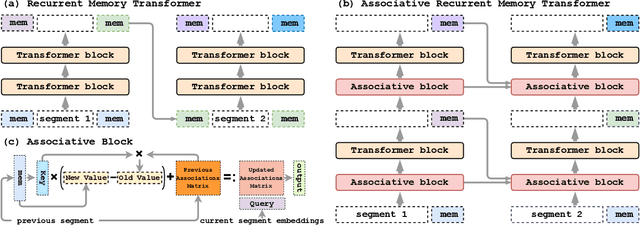
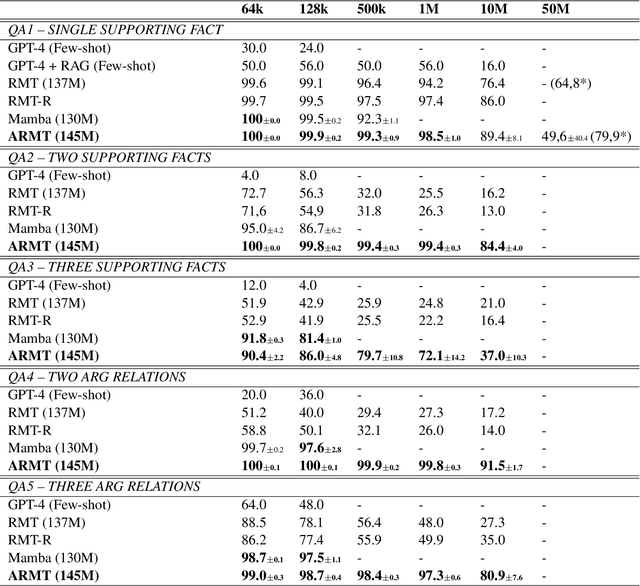
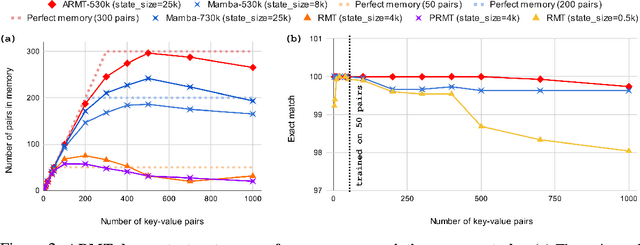

This paper addresses the challenge of creating a neural architecture for very long sequences that requires constant time for processing new information at each time step. Our approach, Associative Recurrent Memory Transformer (ARMT), is based on transformer self-attention for local context and segment-level recurrence for storage of task specific information distributed over a long context. We demonstrate that ARMT outperfors existing alternatives in associative retrieval tasks and sets a new performance record in the recent BABILong multi-task long-context benchmark by answering single-fact questions over 50 million tokens with an accuracy of 79.9%. The source code for training and evaluation is available on github.
BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack
Jun 14, 2024
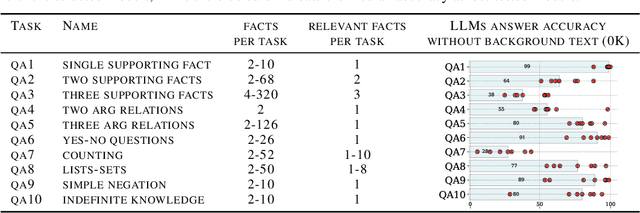

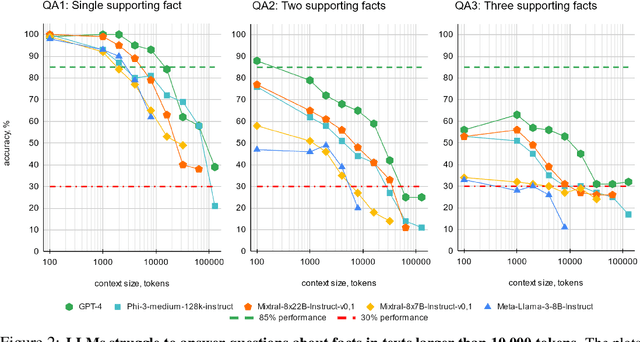
In recent years, the input context sizes of large language models (LLMs) have increased dramatically. However, existing evaluation methods have not kept pace, failing to comprehensively assess the efficiency of models in handling long contexts. To bridge this gap, we introduce the BABILong benchmark, designed to test language models' ability to reason across facts distributed in extremely long documents. BABILong includes a diverse set of 20 reasoning tasks, including fact chaining, simple induction, deduction, counting, and handling lists/sets. These tasks are challenging on their own, and even more demanding when the required facts are scattered across long natural text. Our evaluations show that popular LLMs effectively utilize only 10-20\% of the context and their performance declines sharply with increased reasoning complexity. Among alternatives to in-context reasoning, Retrieval-Augmented Generation methods achieve a modest 60\% accuracy on single-fact question answering, independent of context length. Among context extension methods, the highest performance is demonstrated by recurrent memory transformers, enabling the processing of lengths up to 11 million tokens. The BABILong benchmark is extendable to any length to support the evaluation of new upcoming models with increased capabilities, and we provide splits up to 1 million token lengths.
In Search of Needles in a 11M Haystack: Recurrent Memory Finds What LLMs Miss
Feb 21, 2024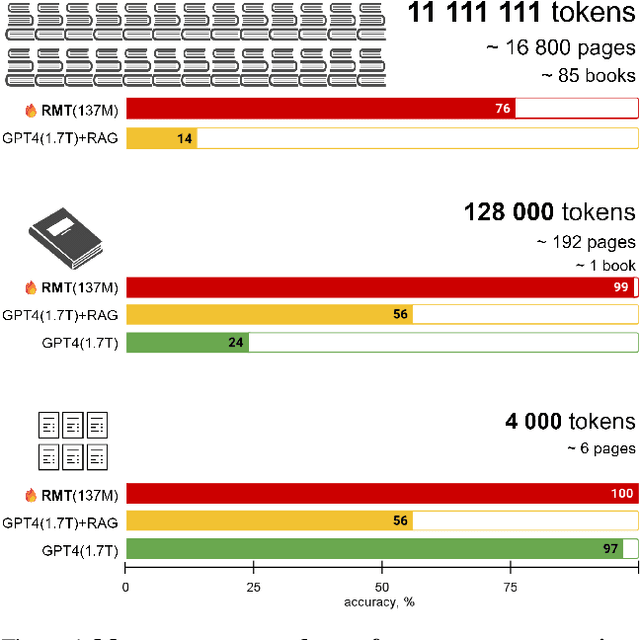

This paper addresses the challenge of processing long documents using generative transformer models. To evaluate different approaches, we introduce BABILong, a new benchmark designed to assess model capabilities in extracting and processing distributed facts within extensive texts. Our evaluation, which includes benchmarks for GPT-4 and RAG, reveals that common methods are effective only for sequences up to $10^4$ elements. In contrast, fine-tuning GPT-2 with recurrent memory augmentations enables it to handle tasks involving up to $11\times 10^6$ elements. This achievement marks a substantial leap, as it is by far the longest input processed by any neural network model to date, demonstrating a significant improvement in the processing capabilities for long sequences.
Better Together: Enhancing Generative Knowledge Graph Completion with Language Models and Neighborhood Information
Nov 02, 2023Real-world Knowledge Graphs (KGs) often suffer from incompleteness, which limits their potential performance. Knowledge Graph Completion (KGC) techniques aim to address this issue. However, traditional KGC methods are computationally intensive and impractical for large-scale KGs, necessitating the learning of dense node embeddings and computing pairwise distances. Generative transformer-based language models (e.g., T5 and recent KGT5) offer a promising solution as they can predict the tail nodes directly. In this study, we propose to include node neighborhoods as additional information to improve KGC methods based on language models. We examine the effects of this imputation and show that, on both inductive and transductive Wikidata subsets, our method outperforms KGT5 and conventional KGC approaches. We also provide an extensive analysis of the impact of neighborhood on model prediction and show its importance. Furthermore, we point the way to significantly improve KGC through more effective neighborhood selection.