 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagonal Batching Unlocks Parallelism in Recurrent Memory Transformers for Long Contexts
Jun 05, 2025Transformer models struggle with long-context inference due to their quadratic time and linear memory complexity. Recurrent Memory Transformers (RMTs) offer a solution by reducing the asymptotic cost to linear time and constant memory usage. However, their memory update mechanism leads to sequential execution, causing a performance bottleneck. We introduce Diagonal Batching, a scheduling scheme that unlocks parallelism across segments in RMTs while preserving exact recurrence. This approach eliminates the sequential constraint, enabling efficient GPU inference even for single long-context inputs without complex batching and pipelining techniques. Because the technique is purely a run-time computation reordering, existing RMT models adopt it with no retraining. Applied to a LLaMA-1B ARMT model, Diagonal Batching yields a 3.3x speedup over standard full-attention LLaMA-1B and a 1.8x speedup over the sequential RMT implementation on 131,072-token sequences. By removing sequential bottleneck, Diagonal Batching reduces inference cost and latency, thereby strengthening RMTs as a practical solution for real-world, long-context applications.
Associative Recurrent Memory Transformer
Jul 05, 2024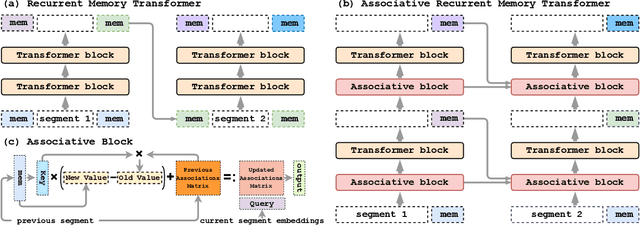
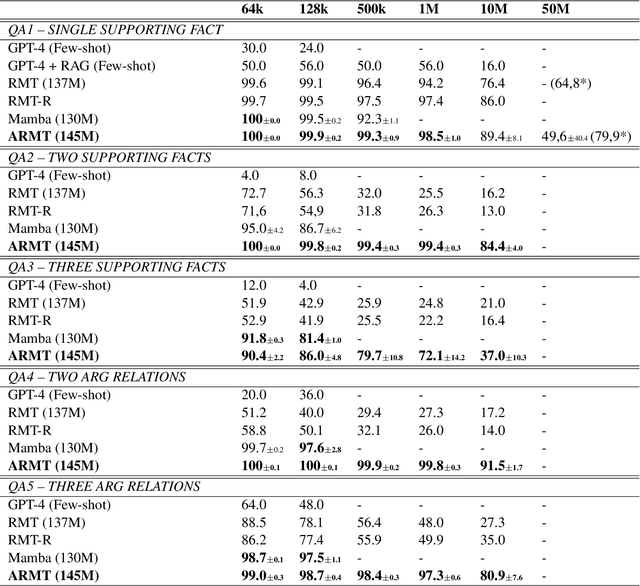
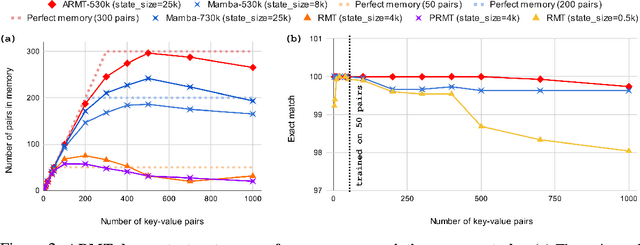

This paper addresses the challenge of creating a neural architecture for very long sequences that requires constant time for processing new information at each time step. Our approach, Associative Recurrent Memory Transformer (ARMT), is based on transformer self-attention for local context and segment-level recurrence for storage of task specific information distributed over a long context. We demonstrate that ARMT outperfors existing alternatives in associative retrieval tasks and sets a new performance record in the recent BABILong multi-task long-context benchmark by answering single-fact questions over 50 million tokens with an accuracy of 79.9%. The source code for training and evaluation is available on github.
BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack
Jun 14, 2024
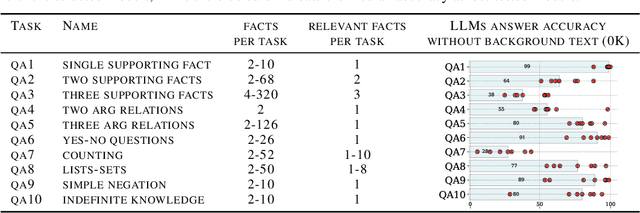

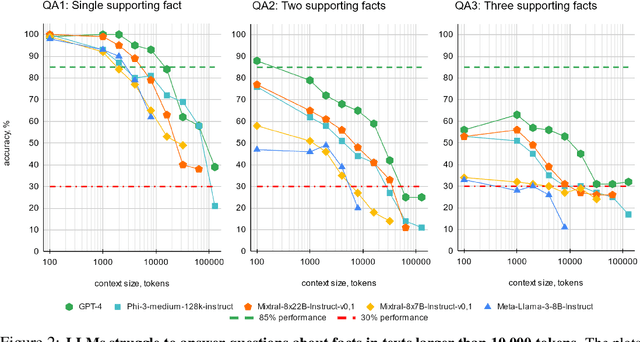
In recent years, the input context sizes of large language models (LLMs) have increased dramatically. However, existing evaluation methods have not kept pace, failing to comprehensively assess the efficiency of models in handling long contexts. To bridge this gap, we introduce the BABILong benchmark, designed to test language models' ability to reason across facts distributed in extremely long documents. BABILong includes a diverse set of 20 reasoning tasks, including fact chaining, simple induction, deduction, counting, and handling lists/sets. These tasks are challenging on their own, and even more demanding when the required facts are scattered across long natural text. Our evaluations show that popular LLMs effectively utilize only 10-20\% of the context and their performance declines sharply with increased reasoning complexity. Among alternatives to in-context reasoning, Retrieval-Augmented Generation methods achieve a modest 60\% accuracy on single-fact question answering, independent of context length. Among context extension methods, the highest performance is demonstrated by recurrent memory transformers, enabling the processing of lengths up to 11 million tokens. The BABILong benchmark is extendable to any length to support the evaluation of new upcoming models with increased capabilities, and we provide splits up to 1 million token lengths.