 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGRegBench: A Novel Benchmark Dataset with Anatomical Landmarks for Mammography Image Registration
Dec 19, 2025Robust mammography registration is essential for clinical applications like tracking disease progression and monitoring longitudinal changes in breast tissue. However, progress has been limited by the absence of public datasets and standardized benchmarks. Existing studies are often not directly comparable, as they use private data and inconsistent evaluation frameworks. To address this, we present MGRegBench, a public benchmark dataset for mammogram registration. It comprises over 5,000 image pairs, with 100 containing manual anatomical landmarks and segmentation masks for rigorous evaluation. This makes MGRegBench one of the largest public 2D registration datasets with manual annotations. Using this resource, we benchmarked diverse registration methods including classical (ANTs), learning-based (VoxelMorph, TransMorph), implicit neural representation (IDIR), a classic mammography-specific approach, and a recent state-of-the-art deep learning method MammoRegNet. The implementations were adapted to this modality from the authors' implementations or re-implemented from scratch. Our contributions are: (1) the first public dataset of this scale with manual landmarks and masks for mammography registration; (2) the first like-for-like comparison of diverse methods on this modality; and (3) an extensive analysis of deep learning-based registration. We publicly release our code and data to establish a foundational resource for fair comparisons and catalyze future research. The source code and data are at https://github.com/KourtKardash/MGRegBench.
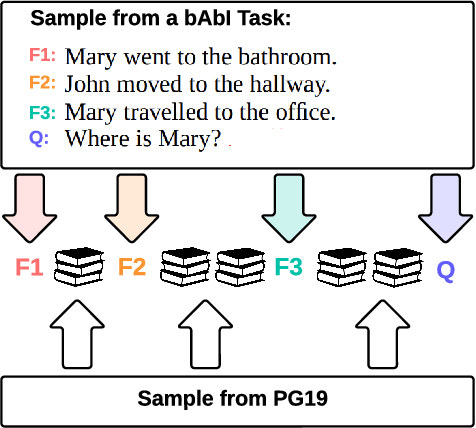
BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack
Jun 14, 2024
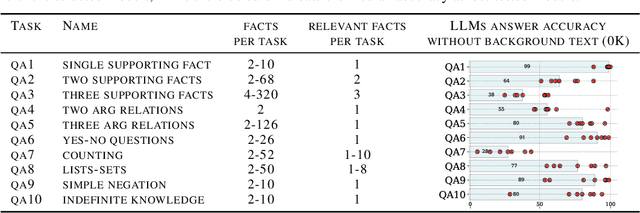

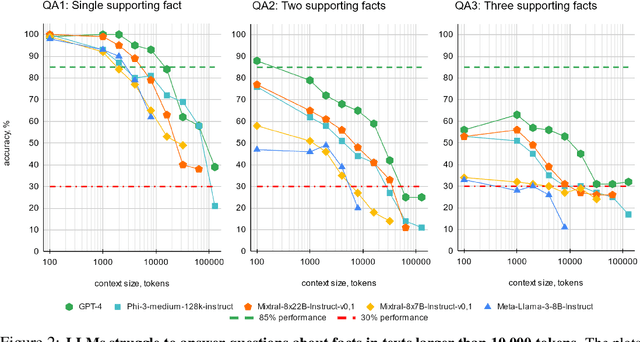
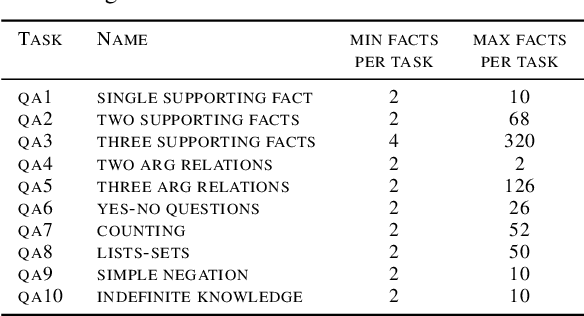
In recent years, the input context sizes of large language models (LLMs) have increased dramatically. However, existing evaluation methods have not kept pace, failing to comprehensively assess the efficiency of models in handling long contexts. To bridge this gap, we introduce the BABILong benchmark, designed to test language models' ability to reason across facts distributed in extremely long documents. BABILong includes a diverse set of 20 reasoning tasks, including fact chaining, simple induction, deduction, counting, and handling lists/sets. These tasks are challenging on their own, and even more demanding when the required facts are scattered across long natural text. Our evaluations show that popular LLMs effectively utilize only 10-20\% of the context and their performance declines sharply with increased reasoning complexity. Among alternatives to in-context reasoning, Retrieval-Augmented Generation methods achieve a modest 60\% accuracy on single-fact question answering, independent of context length. Among context extension methods, the highest performance is demonstrated by recurrent memory transformers, enabling the processing of lengths up to 11 million tokens. The BABILong benchmark is extendable to any length to support the evaluation of new upcoming models with increased capabilities, and we provide splits up to 1 million token lengths.
In Search of Needles in a 11M Haystack: Recurrent Memory Finds What LLMs Miss
Feb 21, 2024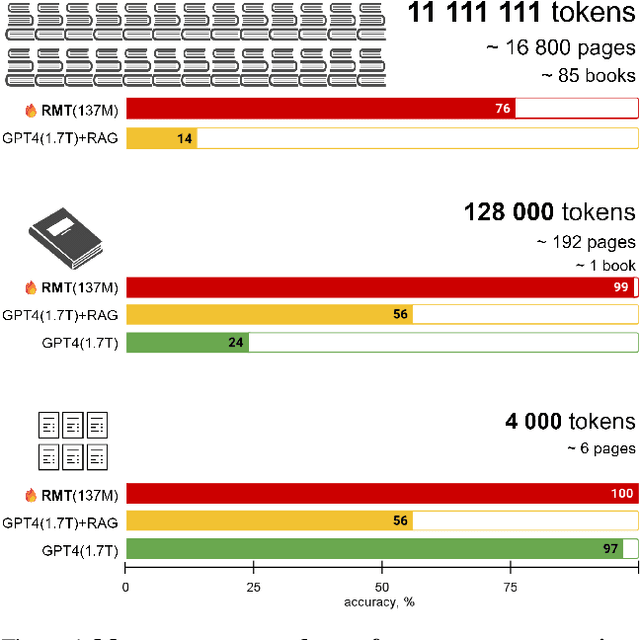

This paper addresses the challenge of processing long documents using generative transformer models. To evaluate different approaches, we introduce BABILong, a new benchmark designed to assess model capabilities in extracting and processing distributed facts within extensive texts. Our evaluation, which includes benchmarks for GPT-4 and RAG, reveals that common methods are effective only for sequences up to $10^4$ elements. In contrast, fine-tuning GPT-2 with recurrent memory augmentations enables it to handle tasks involving up to $11\times 10^6$ elements. This achievement marks a substantial leap, as it is by far the longest input processed by any neural network model to date, demonstrating a significant improvement in the processing capabilities for long sequences.
TreeDQN: Learning to minimize Branch-and-Bound tree
Jun 09, 2023Combinatorial optimization problems require an exhaustive search to find the optimal solution. A convenient approach to solving combinatorial optimization tasks in the form of Mixed Integer Linear Programs is Branch-and-Bound. Branch-and-Bound solver splits a task into two parts dividing the domain of an integer variable, then it solves them recursively, producing a tree of nested sub-tasks. The efficiency of the solver depends on the branchning heuristic used to select a variable for splitting. In the present work, we propose a reinforcement learning method that can efficiently learn the branching heuristic. We view the variable selection task as a tree Markov Decision Process, prove that the Bellman operator adapted for the tree Markov Decision Process is contracting in mean, and propose a modified learning objective for the reinforcement learning agent. Our agent requires less training data and produces smaller trees compared to previous reinforcement learning methods.
Insights From the NeurIPS 2021 NetHack Challenge
Mar 22, 2022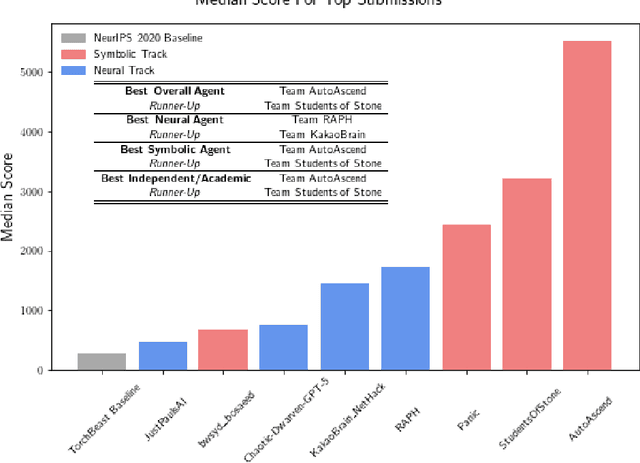

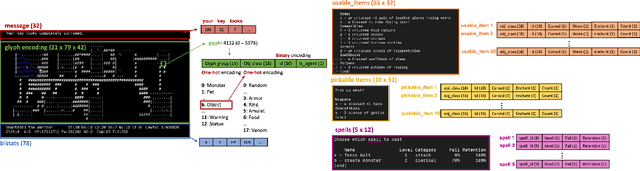
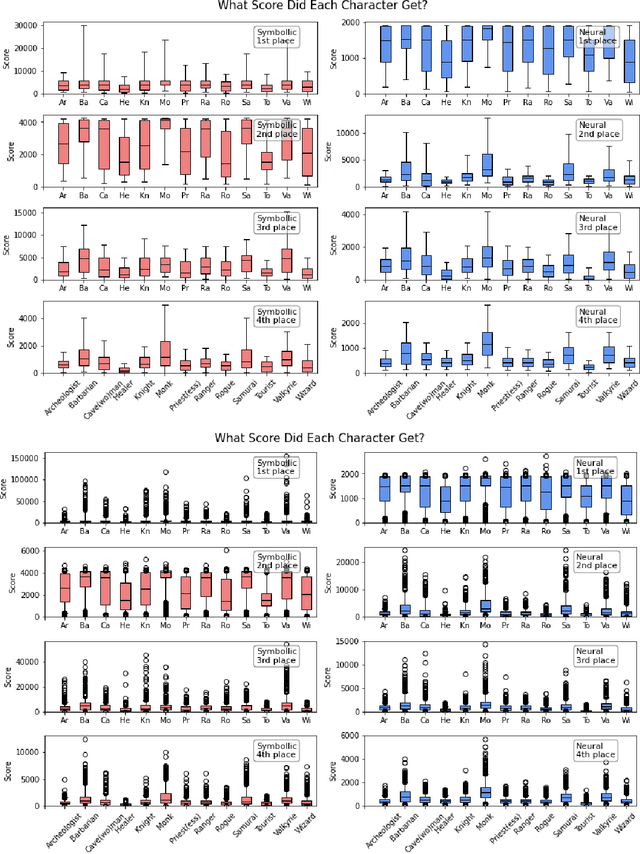
In this report, we summarize the takeaways from the first NeurIPS 2021 NetHack Challenge. Participants were tasked with developing a program or agent that can win (i.e., 'ascend' in) the popular dungeon-crawler game of NetHack by interacting with the NetHack Learning Environment (NLE), a scalable, procedurally generated, and challenging Gym environment for reinforcement learning (RL). The challenge showcased community-driven progress in AI with many diverse approaches significantly beating the previously best results on NetHack. Furthermore, it served as a direct comparison between neural (e.g., deep RL) and symbolic AI, as well as hybrid systems, demonstrating that on NetHack symbolic bots currently outperform deep RL by a large margin. Lastly, no agent got close to winning the game, illustrating NetHack's suitability as a long-term benchmark for AI research.
Aligning an optical interferometer with beam divergence control and continuous action space
Jul 09, 2021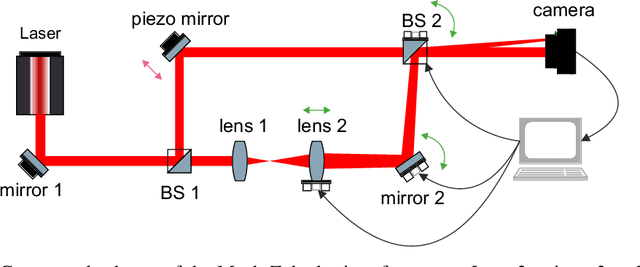


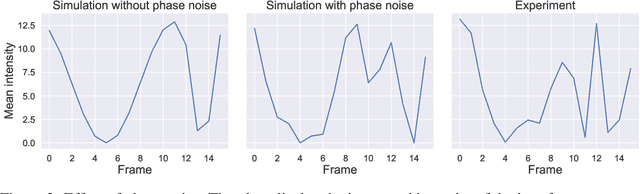
Reinforcement learning is finding its way to real-world problem application, transferring from simulated environments to physical setups. In this work, we implement vision-based alignment of an optical Mach-Zehnder interferometer with a confocal telescope in one arm, which controls the diameter and divergence of the corresponding beam. We use a continuous action space; exponential scaling enables us to handle actions within a range of over two orders of magnitude. Our agent trains only in a simulated environment with domain randomizations. In an experimental evaluation, the agent significantly outperforms an existing solution and a human expert.
Adaptation of Quadruped Robot Locomotion with Meta-Learning
Jul 08, 2021

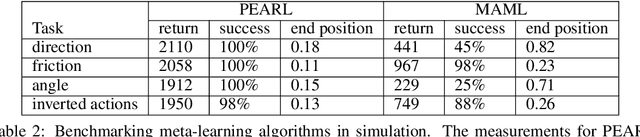
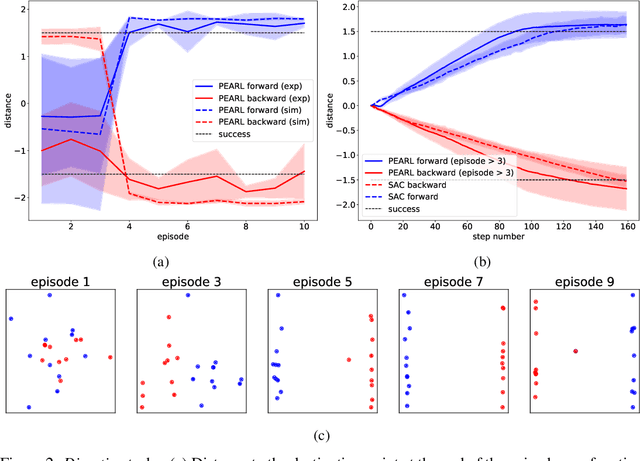
Animals have remarkable abilities to adapt locomotion to different terrains and tasks. However, robots trained by means of reinforcement learning are typically able to solve only a single task and a transferred policy is usually inferior to that trained from scratch. In this work, we demonstrate that meta-reinforcement learning can be used to successfully train a robot capable to solve a wide range of locomotion tasks. The performance of the meta-trained robot is similar to that of a robot that is trained on a single task.
Interferobot: aligning an optical interferometer by a reinforcement learning agent
Jun 03, 2020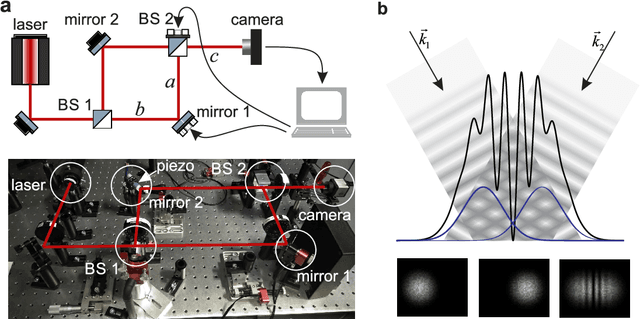



Limitations in acquiring training data restrict potential applications of deep reinforcement learning (RL) methods to the training of real-world robots. Here we train an RL agent to align a Mach-Zehnder interferometer, which is an essential part of many optical experiments, based on images of interference fringes acquired by a monocular camera. The agent is trained in a simulated environment, without any hand-coded features or a priori information about the physics, and subsequently transferred to a physical interferometer. Thanks to a set of domain randomizations simulating uncertainties in physical measurements, the agent successfully aligns this interferometer without any fine tuning, achieving a performance level of a human expert.