 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning an optical interferometer with beam divergence control and continuous action space
Jul 09, 2021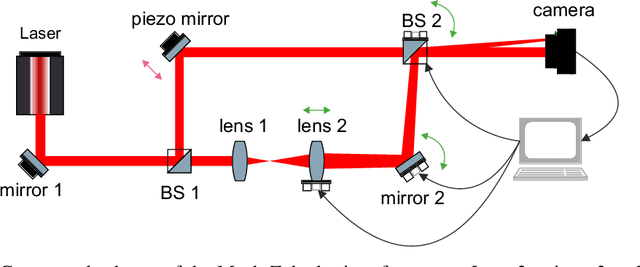


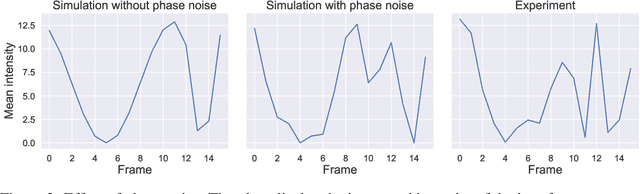
Reinforcement learning is finding its way to real-world problem application, transferring from simulated environments to physical setups. In this work, we implement vision-based alignment of an optical Mach-Zehnder interferometer with a confocal telescope in one arm, which controls the diameter and divergence of the corresponding beam. We use a continuous action space; exponential scaling enables us to handle actions within a range of over two orders of magnitude. Our agent trains only in a simulated environment with domain randomizations. In an experimental evaluation, the agent significantly outperforms an existing solution and a human expert.
Adaptation of Quadruped Robot Locomotion with Meta-Learning
Jul 08, 2021

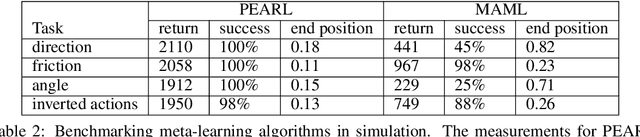
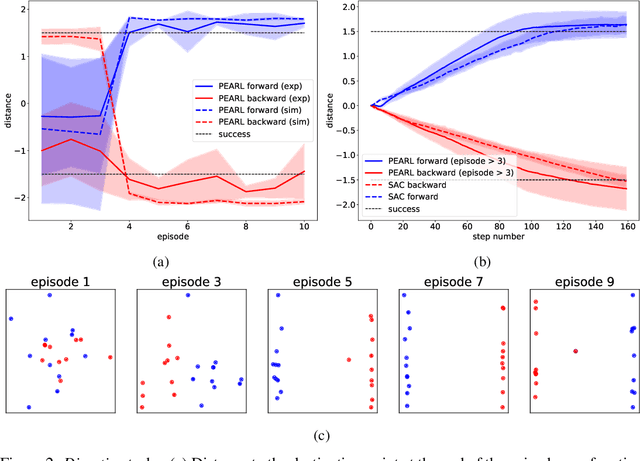
Animals have remarkable abilities to adapt locomotion to different terrains and tasks. However, robots trained by means of reinforcement learning are typically able to solve only a single task and a transferred policy is usually inferior to that trained from scratch. In this work, we demonstrate that meta-reinforcement learning can be used to successfully train a robot capable to solve a wide range of locomotion tasks. The performance of the meta-trained robot is similar to that of a robot that is trained on a single task.
Interferobot: aligning an optical interferometer by a reinforcement learning agent
Jun 03, 2020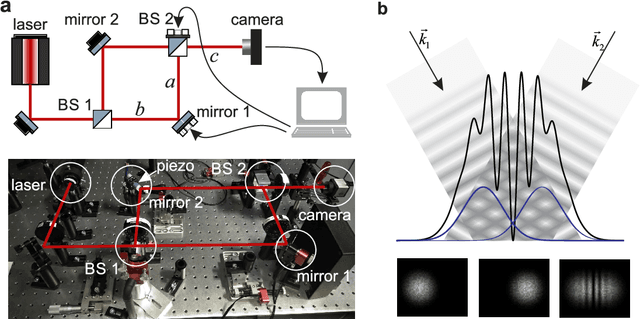



Limitations in acquiring training data restrict potential applications of deep reinforcement learning (RL) methods to the training of real-world robots. Here we train an RL agent to align a Mach-Zehnder interferometer, which is an essential part of many optical experiments, based on images of interference fringes acquired by a monocular camera. The agent is trained in a simulated environment, without any hand-coded features or a priori information about the physics, and subsequently transferred to a physical interferometer. Thanks to a set of domain randomizations simulating uncertainties in physical measurements, the agent successfully aligns this interferometer without any fine tuning, achieving a performance level of a human expert.
Modeling Scalability of Distributed Machine Learning
Mar 25, 2017



Present day machine learning is computationally intensive and processes large amounts of data. It is implemented in a distributed fashion in order to address these scalability issues. The work is parallelized across a number of computing nodes. It is usually hard to estimate in advance how many nodes to use for a particular workload. We propose a simple framework for estimating the scalability of distributed machine learning algorithms. We measure the scalability by means of the speedup an algorithm achieves with more nodes. We propose time complexity models for gradient descent and graphical model inference. We validate our models with experiments on deep learning training and belief propagation. This framework was used to study the scalability of machine learning algorithms in Apache Spark.