 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSV-TrustEval-C: Evaluating Structure and Semantic Reasoning in Large Language Models for Source Code Vulnerability Analysis
May 27, 2025As Large Language Models (LLMs) evolve in understanding and generating code, accurately evaluating their reliability in analyzing source code vulnerabilities becomes increasingly vital. While studies have examined LLM capabilities in tasks like vulnerability detection and repair, they often overlook the importance of both structure and semantic reasoning crucial for trustworthy vulnerability analysis. To address this gap, we introduce SV-TrustEval-C, a benchmark designed to evaluate LLMs' abilities for vulnerability analysis of code written in the C programming language through two key dimensions: structure reasoning - assessing how models identify relationships between code elements under varying data and control flow complexities; and semantic reasoning - examining their logical consistency in scenarios where code is structurally and semantically perturbed. Our results show that current LLMs are far from satisfactory in understanding complex code relationships and that their vulnerability analyses rely more on pattern matching than on robust logical reasoning. These findings underscore the effectiveness of the SV-TrustEval-C benchmark and highlight critical areas for enhancing the reasoning capabilities and trustworthiness of LLMs in real-world vulnerability analysis tasks. Our initial benchmark dataset is publicly available.
Is $F_1$ Score Suboptimal for Cybersecurity Models? Introducing $C_{score}$, a Cost-Aware Alternative for Model Assessment
Jul 19, 2024The cost of errors related to machine learning classifiers, namely, false positives and false negatives, are not equal and are application dependent. For example, in cybersecurity applications, the cost of not detecting an attack is very different from marking a benign activity as an attack. Various design choices during machine learning model building, such as hyperparameter tuning and model selection, allow a data scientist to trade-off between these two errors. However, most of the commonly used metrics to evaluate model quality, such as $F_1$ score, which is defined in terms of model precision and recall, treat both these errors equally, making it difficult for users to optimize for the actual cost of these errors. In this paper, we propose a new cost-aware metric, $C_{score}$ based on precision and recall that can replace $F_1$ score for model evaluation and selection. It includes a cost ratio that takes into account the differing costs of handling false positives and false negatives. We derive and characterize the new cost metric, and compare it to $F_1$ score. Further, we use this metric for model thresholding for five cybersecurity related datasets for multiple cost ratios. The results show an average cost savings of 49%.
STAN: Synthetic Network Traffic Generation using Autoregressive Neural Models
Sep 27, 2020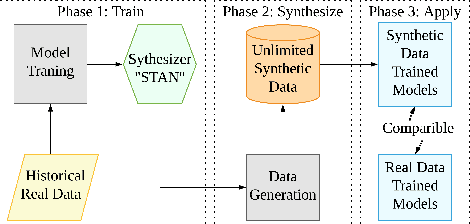
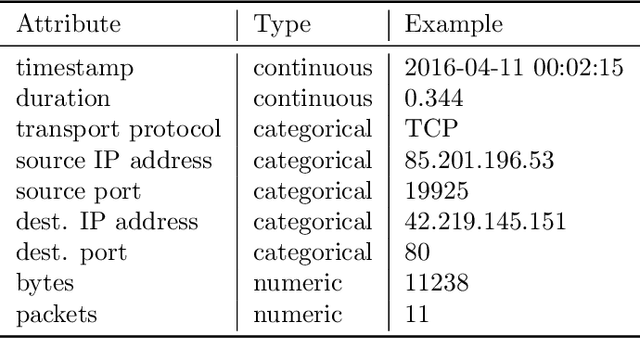

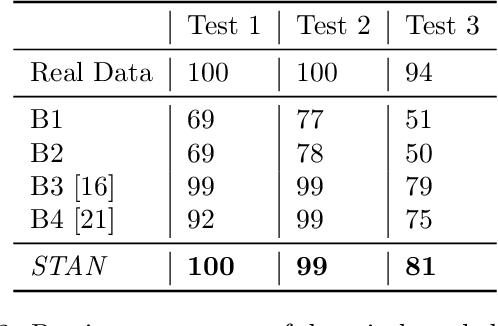
Deep learning models have achieved great success in recent years. However, large amounts of data are typically required to train such models. While some types of data, such as images, videos, and text, are easier to find, data in certain domains is difficult to obtain. For instance, cybersecurity applications routinely use network traffic data which organizations are reluctant to share, even internally, due to privacy reasons. An alternative is to use synthetically generated data; however, most existing data generating methods lack the ability to capture complex dependency structures that are usually prevalent in real data by assuming independence either temporally or between attributes. This paper presents our approach called STAN, Synthetic Network Traffic Generation using Autoregressive Neural models, to generate realistic synthetic network traffic data. Our novel autoregressive neural architecture captures both temporal dependence and dependence between attributes at any given time. It integrates convolutional neural layers (CNN) with mixture density layers (MDN) and softmax layers to model both continuous and discrete variables. We evaluate performance of STAN by training it on both a simulated dataset and a real network traffic data set. Multiple metrics are used to compare the generated data with real data and with data generated via several baseline methods. Finally, to answer the question -- can real network traffic data be substituted with synthetic data to train models of comparable accuracy -- we consider two commonly used models for anomaly detection in such data, and compare F1/MSE measures of models trained on real data and those on increasing proportions of generated data. The results show only a small decline in accuracy of models trained solely on synthetic data.
Attention-Based Self-Supervised Feature Learning for Security Data
Mar 24, 2020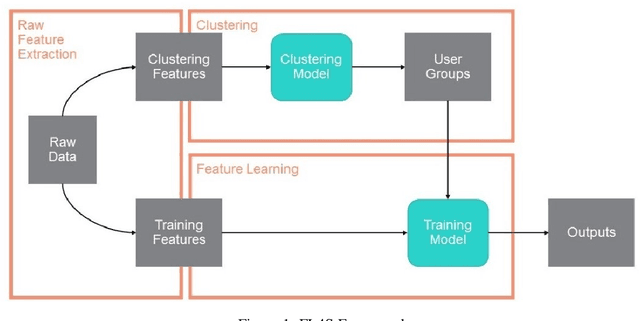
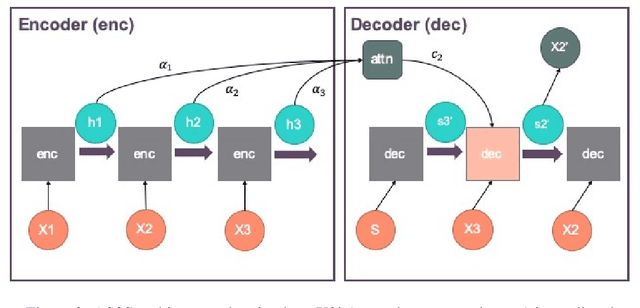
While applications of machine learning in cyber-security have grown rapidly, most models use manually constructed features. This manual approach is error-prone and requires domain expertise. In this paper, we design a self-supervised sequence-to-sequence model with attention to learn an embedding for data routinely used in cyber-security applications. The method is validated on two real world public data sets. The learned features are used in an anomaly detection model and perform better than learned features from baseline methods.
An Anomaly Contribution Explainer for Cyber-Security Applications
Dec 01, 2019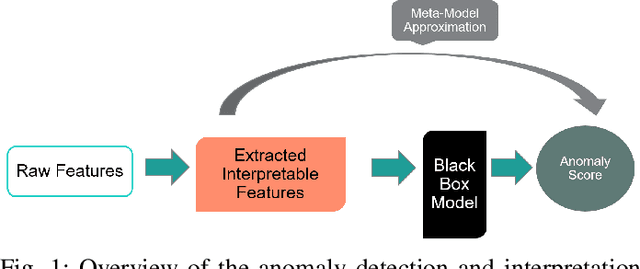
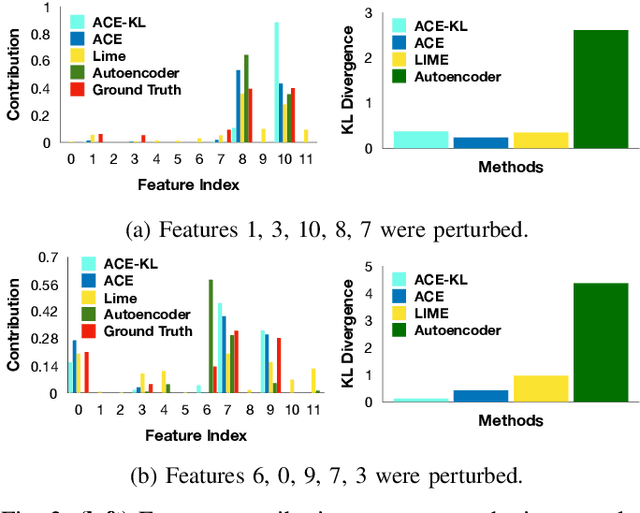
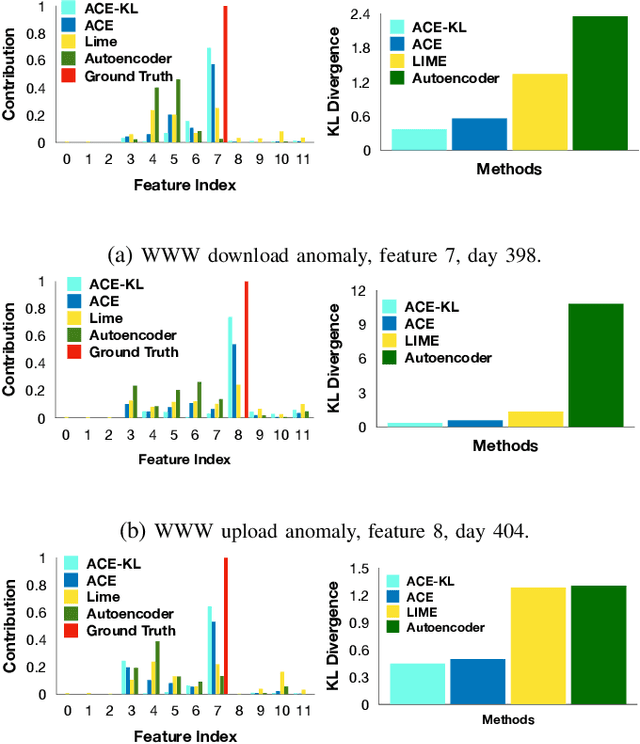

In this paper, we introduce Anomaly Contribution Explainer or ACE, a tool to explain security anomaly detection models in terms of the model features through a regression framework, and its variant, ACE-KL, which highlights the important anomaly contributors. ACE and ACE-KL provide insights in diagnosing which attributes significantly contribute to an anomaly by building a specialized linear model to locally approximate the anomaly score that a black-box model generates. We conducted experiments with these anomaly detection models to detect security anomalies on both synthetic data and real data. In particular, we evaluate performance on three public data sets: CERT insider threat, netflow logs, and Android malware. The experimental results are encouraging: our methods consistently identify the correct contributing feature in the synthetic data where ground truth is available; similarly, for real data sets, our methods point a security analyst in the direction of the underlying causes of an anomaly, including in one case leading to the discovery of previously overlooked network scanning activity. We have made our source code publicly available.
Modeling Scalability of Distributed Machine Learning
Mar 25, 2017



Present day machine learning is computationally intensive and processes large amounts of data. It is implemented in a distributed fashion in order to address these scalability issues. The work is parallelized across a number of computing nodes. It is usually hard to estimate in advance how many nodes to use for a particular workload. We propose a simple framework for estimating the scalability of distributed machine learning algorithms. We measure the scalability by means of the speedup an algorithm achieves with more nodes. We propose time complexity models for gradient descent and graphical model inference. We validate our models with experiments on deep learning training and belief propagation. This framework was used to study the scalability of machine learning algorithms in Apache Spark.