 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs $F_1$ Score Suboptimal for Cybersecurity Models? Introducing $C_{score}$, a Cost-Aware Alternative for Model Assessment
Jul 19, 2024The cost of errors related to machine learning classifiers, namely, false positives and false negatives, are not equal and are application dependent. For example, in cybersecurity applications, the cost of not detecting an attack is very different from marking a benign activity as an attack. Various design choices during machine learning model building, such as hyperparameter tuning and model selection, allow a data scientist to trade-off between these two errors. However, most of the commonly used metrics to evaluate model quality, such as $F_1$ score, which is defined in terms of model precision and recall, treat both these errors equally, making it difficult for users to optimize for the actual cost of these errors. In this paper, we propose a new cost-aware metric, $C_{score}$ based on precision and recall that can replace $F_1$ score for model evaluation and selection. It includes a cost ratio that takes into account the differing costs of handling false positives and false negatives. We derive and characterize the new cost metric, and compare it to $F_1$ score. Further, we use this metric for model thresholding for five cybersecurity related datasets for multiple cost ratios. The results show an average cost savings of 49%.
Attention-Based Self-Supervised Feature Learning for Security Data
Mar 24, 2020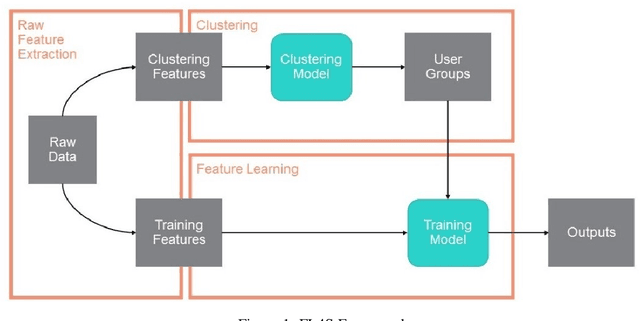
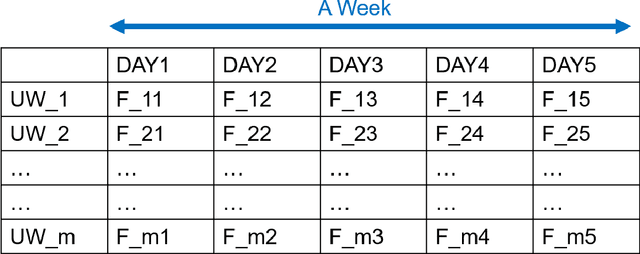
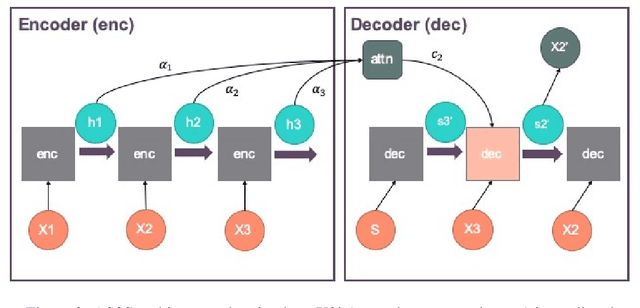
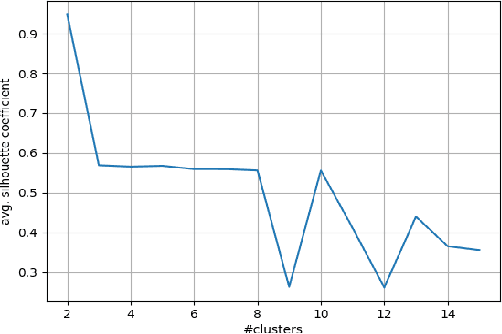
While applications of machine learning in cyber-security have grown rapidly, most models use manually constructed features. This manual approach is error-prone and requires domain expertise. In this paper, we design a self-supervised sequence-to-sequence model with attention to learn an embedding for data routinely used in cyber-security applications. The method is validated on two real world public data sets. The learned features are used in an anomaly detection model and perform better than learned features from baseline methods.
An Anomaly Contribution Explainer for Cyber-Security Applications
Dec 01, 2019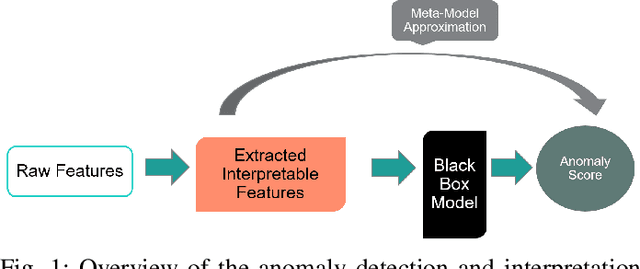
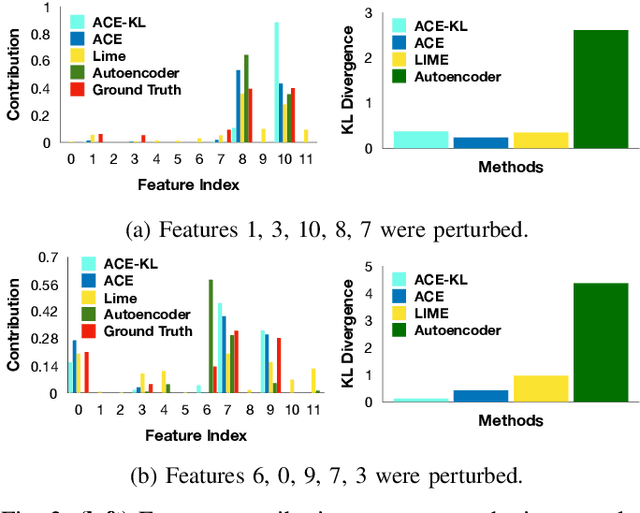
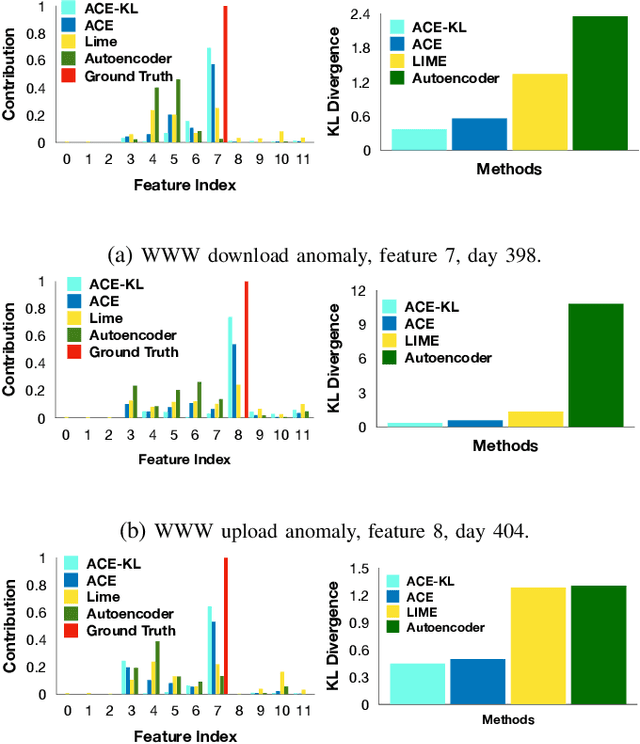

In this paper, we introduce Anomaly Contribution Explainer or ACE, a tool to explain security anomaly detection models in terms of the model features through a regression framework, and its variant, ACE-KL, which highlights the important anomaly contributors. ACE and ACE-KL provide insights in diagnosing which attributes significantly contribute to an anomaly by building a specialized linear model to locally approximate the anomaly score that a black-box model generates. We conducted experiments with these anomaly detection models to detect security anomalies on both synthetic data and real data. In particular, we evaluate performance on three public data sets: CERT insider threat, netflow logs, and Android malware. The experimental results are encouraging: our methods consistently identify the correct contributing feature in the synthetic data where ground truth is available; similarly, for real data sets, our methods point a security analyst in the direction of the underlying causes of an anomaly, including in one case leading to the discovery of previously overlooked network scanning activity. We have made our source code publicly available.