 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLensWalk: Agentic Video Understanding by Planning How You See in Videos
Mar 25, 2026The dense, temporal nature of video presents a profound challenge for automated analysis. Despite the use of powerful Vision-Language Models, prevailing methods for video understanding are limited by the inherent disconnect between reasoning and perception: they rely on static, pre-processed information and cannot actively seek raw evidence from video as their understanding evolves. To address this, we introduce LensWalk, a flexible agentic framework that empowers a Large Language Model reasoner to control its own visual observation actively. LensWalk establishes a tight reason-plan-observe loop where the agent dynamically specifies, at each step, the temporal scope and sampling density of the video it observes. Using a suite of versatile, Vision-Language Model based tools parameterized by these specifications, the agent can perform broad scans for cues, focus on specific segments for fact extraction, and stitch evidence from multiple moments for holistic verification. This design allows for progressive, on-demand evidence gathering that directly serves the agent's evolving chain of thought. Without requiring any model fine-tuning, LensWalk delivers substantial, plug-and-play performance gains on multiple model recipes, boosting their accuracy by over 5\% on challenging long-video benchmarks like LVBench and Video-MME. Our analysis reveals that enabling an agent to control how it sees is key to unlocking more accurate, robust, and interpretable video reasoning.
LaTeX Compilation: Challenges in the Era of LLMs
Mar 04, 2026As large language models (LLMs) increasingly assist scientific writing, limitations and the significant token cost of TeX become more and more visible. This paper analyzes TeX's fundamental defects in compilation and user experience design to illustrate its limitations on compilation efficiency, generated semantics, error localization, and tool ecosystem in the era of LLMs. As an alternative, Mogan STEM, a WYSIWYG structured editor, is introduced. Mogan outperforms TeX in the above aspects by its efficient data structure, fast rendering, and on-demand plugin loading. Extensive experiments are conducted to verify the benefits on compilation/rendering time and performance in LLM tasks. What's more, we show that due to Mogan's lower information entropy, it is more efficient to use .tmu (the document format of Mogan) to fine-tune LLMs than TeX. Therefore, we launch an appeal for larger experiments on LLM training using the .tmu format.
SV-TrustEval-C: Evaluating Structure and Semantic Reasoning in Large Language Models for Source Code Vulnerability Analysis
May 27, 2025As Large Language Models (LLMs) evolve in understanding and generating code, accurately evaluating their reliability in analyzing source code vulnerabilities becomes increasingly vital. While studies have examined LLM capabilities in tasks like vulnerability detection and repair, they often overlook the importance of both structure and semantic reasoning crucial for trustworthy vulnerability analysis. To address this gap, we introduce SV-TrustEval-C, a benchmark designed to evaluate LLMs' abilities for vulnerability analysis of code written in the C programming language through two key dimensions: structure reasoning - assessing how models identify relationships between code elements under varying data and control flow complexities; and semantic reasoning - examining their logical consistency in scenarios where code is structurally and semantically perturbed. Our results show that current LLMs are far from satisfactory in understanding complex code relationships and that their vulnerability analyses rely more on pattern matching than on robust logical reasoning. These findings underscore the effectiveness of the SV-TrustEval-C benchmark and highlight critical areas for enhancing the reasoning capabilities and trustworthiness of LLMs in real-world vulnerability analysis tasks. Our initial benchmark dataset is publicly available.
Learning to Help in Multi-Class Settings
Jan 23, 2025



Deploying complex machine learning models on resource-constrained devices is challenging due to limited computational power, memory, and model retrainability. To address these limitations, a hybrid system can be established by augmenting the local model with a server-side model, where samples are selectively deferred by a rejector and then sent to the server for processing. The hybrid system enables efficient use of computational resources while minimizing the overhead associated with server usage. The recently proposed Learning to Help (L2H) model trains a server model given a fixed local (client) model, differing from the Learning to Defer (L2D) framework, which trains the client for a fixed (expert) server. In both L2D and L2H, the training includes learning a rejector at the client to determine when to query the server. In this work, we extend the L2H model from binary to multi-class classification problems and demonstrate its applicability in a number of different scenarios of practical interest in which access to the server may be limited by cost, availability, or policy. We derive a stage-switching surrogate loss function that is differentiable, convex, and consistent with the Bayes rule corresponding to the 0-1 loss for the L2H model. Experiments show that our proposed methods offer an efficient and practical solution for multi-class classification in resource-constrained environments.
Sonicmesh: Enhancing 3D Human Mesh Reconstruction in Vision-Impaired Environments With Acoustic Signals
Dec 15, 20243D Human Mesh Reconstruction (HMR) from 2D RGB images faces challenges in environments with poor lighting, privacy concerns, or occlusions. These weaknesses of RGB imaging can be complemented by acoustic signals, which are widely available, easy to deploy, and capable of penetrating obstacles. However, no existing methods effectively combine acoustic signals with RGB data for robust 3D HMR. The primary challenges include the low-resolution images generated by acoustic signals and the lack of dedicated processing backbones. We introduce SonicMesh, a novel approach combining acoustic signals with RGB images to reconstruct 3D human mesh. To address the challenges of low resolution and the absence of dedicated processing backbones in images generated by acoustic signals, we modify an existing method, HRNet, for effective feature extraction. We also integrate a universal feature embedding technique to enhance the precision of cross-dimensional feature alignment, enabling SonicMesh to achieve high accuracy. Experimental results demonstrate that SonicMesh accurately reconstructs 3D human mesh in challenging environments such as occlusions, non-line-of-sight scenarios, and poor lighting.
StarWhisper Telescope: Agent-Based Observation Assistant System to Approach AI Astrophysicist
Dec 09, 2024



With the rapid advancements in Large Language Models (LLMs), LLM-based agents have introduced convenient and user-friendly methods for leveraging tools across various domains. In the field of astronomical observation, the construction of new telescopes has significantly increased astronomers' workload. Deploying LLM-powered agents can effectively alleviate this burden and reduce the costs associated with training personnel. Within the Nearby Galaxy Supernovae Survey (NGSS) project, which encompasses eight telescopes across three observation sites, aiming to find the transients from the galaxies in 50 mpc, we have developed the \textbf{StarWhisper Telescope System} to manage the entire observation process. This system automates tasks such as generating observation lists, conducting observations, analyzing data, and providing feedback to the observer. Observation lists are customized for different sites and strategies to ensure comprehensive coverage of celestial objects. After manual verification, these lists are uploaded to the telescopes via the agents in the system, which initiates observations upon neutral language. The observed images are analyzed in real-time, and the transients are promptly communicated to the observer. The agent modifies them into a real-time follow-up observation proposal and send to the Xinglong observatory group chat, then add them to the next-day observation lists. Additionally, the integration of AI agents within the system provides online accessibility, saving astronomers' time and encouraging greater participation from amateur astronomers in the NGSS project.
Generalizing End-To-End Autonomous Driving In Real-World Environments Using Zero-Shot LLMs
Nov 21, 2024



Traditional autonomous driving methods adopt a modular design, decomposing tasks into sub-tasks. In contrast, end-to-end autonomous driving directly outputs actions from raw sensor data, avoiding error accumulation. However, training an end-to-end model requires a comprehensive dataset; otherwise, the model exhibits poor generalization capabilities. Recently, large language models (LLMs) have been applied to enhance the generalization capabilities of end-to-end driving models. Most studies explore LLMs in an open-loop manner, where the output actions are compared to those of experts without direct feedback from the real world, while others examine closed-loop results only in simulations. This paper proposes an efficient architecture that integrates multimodal LLMs into end-to-end driving models operating in closed-loop settings in real-world environments. In our architecture, the LLM periodically processes raw sensor data to generate high-level driving instructions, effectively guiding the end-to-end model, even at a slower rate than the raw sensor data. This architecture relaxes the trade-off between the latency and inference quality of the LLM. It also allows us to choose from a wide variety of LLMs to improve high-level driving instructions and minimize fine-tuning costs. Consequently, our architecture reduces data collection requirements because the LLMs do not directly output actions; we only need to train a simple imitation learning model to output actions. In our experiments, the training data for the end-to-end model in a real-world environment consists of only simple obstacle configurations with one traffic cone, while the test environment is more complex and contains multiple obstacles placed in various positions. Experiments show that the proposed architecture enhances the generalization capabilities of the end-to-end model even without fine-tuning the LLM.
EAPCR: A Universal Feature Extractor for Scientific Data without Explicit Feature Relation Patterns
Nov 12, 2024



Conventional methods, including Decision Tree (DT)-based methods, have been effective in scientific tasks, such as non-image medical diagnostics, system anomaly detection, and inorganic catalysis efficiency prediction. However, most deep-learning techniques have struggled to surpass or even match this level of success as traditional machine-learning methods. The primary reason is that these applications involve multi-source, heterogeneous data where features lack explicit relationships. This contrasts with image data, where pixels exhibit spatial relationships; textual data, where words have sequential dependencies; and graph data, where nodes are connected through established associations. The absence of explicit Feature Relation Patterns (FRPs) presents a significant challenge for deep learning techniques in scientific applications that are not image, text, and graph-based. In this paper, we introduce EAPCR, a universal feature extractor designed for data without explicit FRPs. Tested across various scientific tasks, EAPCR consistently outperforms traditional methods and bridges the gap where deep learning models fall short. To further demonstrate its robustness, we synthesize a dataset without explicit FRPs. While Kolmogorov-Arnold Network (KAN) and feature extractors like Convolutional Neural Networks (CNNs), Graph Convolutional Networks (GCNs), and Transformers struggle, EAPCR excels, demonstrating its robustness and superior performance in scientific tasks without FRPs.
When to Trust Your Data: Enhancing Dyna-Style Model-Based Reinforcement Learning With Data Filter
Oct 16, 2024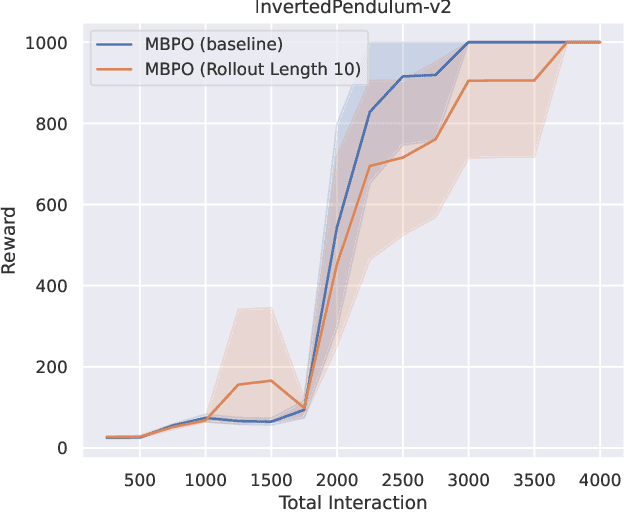

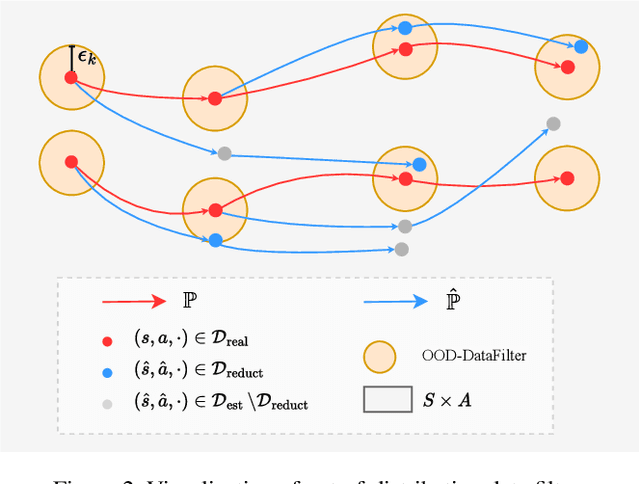
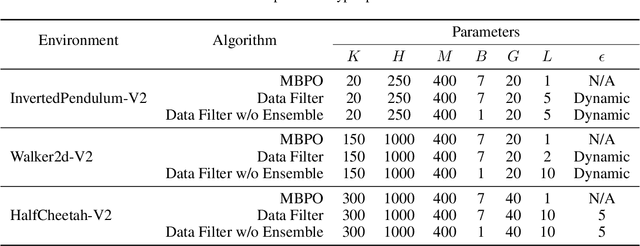
Reinforcement learning (RL) algorithms can be divided into two classes: model-free algorithms, which are sample-inefficient, and model-based algorithms, which suffer from model bias. Dyna-style algorithms combine these two approaches by using simulated data from an estimated environmental model to accelerate model-free training. However, their efficiency is compromised when the estimated model is inaccurate. Previous works address this issue by using model ensembles or pretraining the estimated model with data collected from the real environment, increasing computational and sample complexity. To tackle this issue, we introduce an out-of-distribution (OOD) data filter that removes simulated data from the estimated model that significantly diverges from data collected in the real environment. We show theoretically that this technique enhances the quality of simulated data. With the help of the OOD data filter, the data simulated from the estimated model better mimics the data collected by interacting with the real model. This improvement is evident in the critic updates compared to using the simulated data without the OOD data filter. Our experiment integrates the data filter into the model-based policy optimization (MBPO) algorithm. The results demonstrate that our method requires fewer interactions with the real environment to achieve a higher level of optimality than MBPO, even without a model ensemble.
Predicting and Accelerating Nanomaterials Synthesis Using Machine Learning Featurization
Sep 12, 2024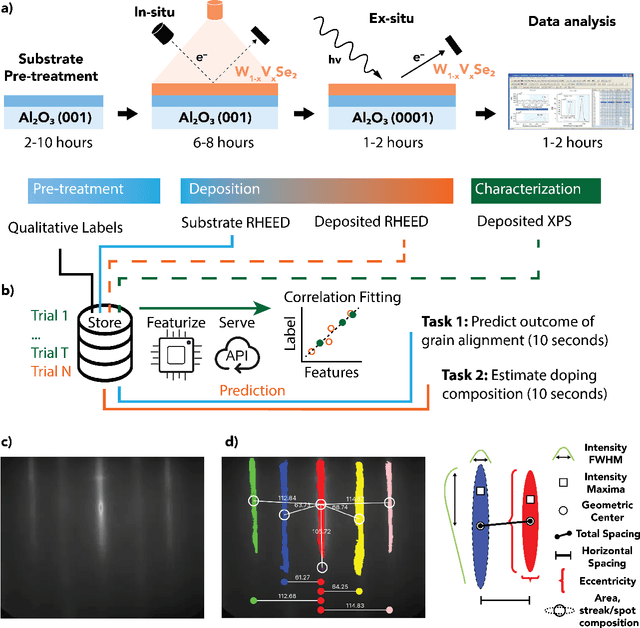
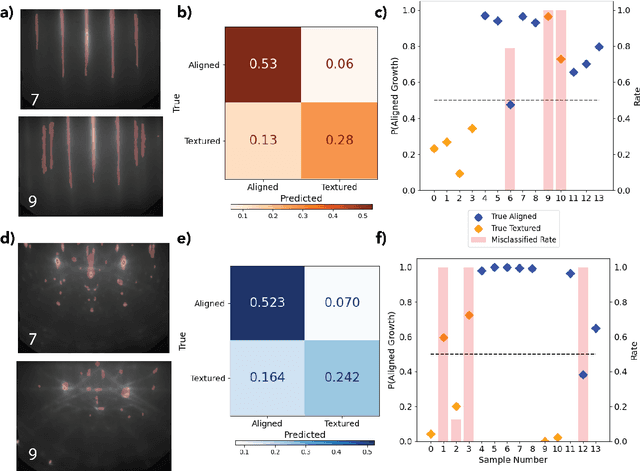
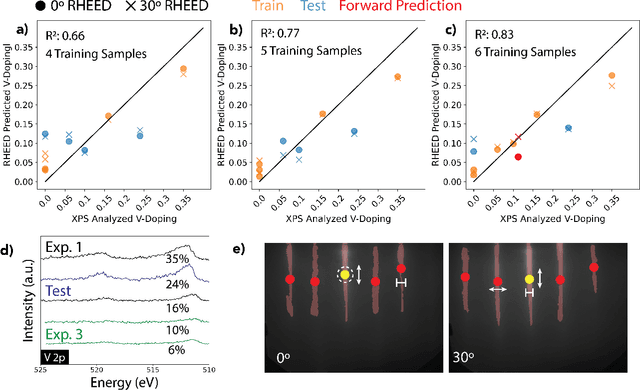
Solving for the complex conditions of materials synthesis and processing requires analyzing information gathered from multiple modes of characterization. Currently, quantitative information is extracted serially with manual tools and intuition, constraining the feedback cycle for process optimization. We use machine learning to automate and generalize feature extraction for in-situ reflection high-energy electron diffraction (RHEED) data to establish quantitatively predictive relationships in small sets ($\sim$10) of expert-labeled data, and apply these to save significant time on subsequent epitaxially grown samples. The fidelity of these relationships is tested on a representative material system ($W_{1-x}V_xSe2$ growth on c-plane sapphire substrate (0001)) at two stages of synthesis with two aims: 1) predicting the grain alignment of the deposited film from the pre-growth substrate surface data, and 2) estimating the vanadium (V) dopant concentration using in-situ RHEED as a proxy for ex-situ methods (e.g. x-ray photoelectron spectroscopy). Both tasks are accomplished using the same set of materials agnostic core features, eliminating the need to retrain for specific systems and leading to a potential 80\% time saving over a 100 sample synthesis campaign. These predictions provide guidance for recipe adjustments to avoid doomed trials, reduce follow-on characterization, and improve control resolution for materials synthesis, ultimately accelerating materials discovery and commercial scale-up.