 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Language Models Know Theo Has a Wife? Investigating the Proviso Problem
Mar 09, 2026We investigate how language models handle the proviso problem, an unresolved issue in pragmatics where presuppositions in conditional sentences diverge between theoretical and human interpretations. We reformulate this phenomenon as a Natural Language Inference task and introduce a diagnostic dataset designed to probe presupposition projection in conditionals. We evaluate RoBERTa, DeBERTa, LLaMA, and Gemma using explainability analyses. The results show that models broadly align with human judgments but rely on shallow pattern matching rather than semantic or pragmatic reasoning. Our work provides the first computational evaluation framework for the proviso problem and highlights the need for diagnostic, multi-method approaches to assess pragmatic competence and context-dependent meaning in language models.
SoftHateBench: Evaluating Moderation Models Against Reasoning-Driven, Policy-Compliant Hostility
Jan 28, 2026Online hate on social media ranges from overt slurs and threats (\emph{hard hate speech}) to \emph{soft hate speech}: discourse that appears reasonable on the surface but uses framing and value-based arguments to steer audiences toward blaming or excluding a target group. We hypothesize that current moderation systems, largely optimized for surface toxicity cues, are not robust to this reasoning-driven hostility, yet existing benchmarks do not measure this gap systematically. We introduce \textbf{\textsc{SoftHateBench}}, a generative benchmark that produces soft-hate variants while preserving the underlying hostile standpoint. To generate soft hate, we integrate the \emph{Argumentum Model of Topics} (AMT) and \emph{Relevance Theory} (RT) in a unified framework: AMT provides the backbone argument structure for rewriting an explicit hateful standpoint into a seemingly neutral discussion while preserving the stance, and RT guides generation to keep the AMT chain logically coherent. The benchmark spans \textbf{7} sociocultural domains and \textbf{28} target groups, comprising \textbf{4,745} soft-hate instances. Evaluations across encoder-based detectors, general-purpose LLMs, and safety models show a consistent drop from hard to soft tiers: systems that detect explicit hostility often fail when the same stance is conveyed through subtle, reasoning-based language. \textcolor{red}{\textbf{Disclaimer.} Contains offensive examples used solely for research.}
Let's CONFER: A Dataset for Evaluating Natural Language Inference Models on CONditional InFERence and Presupposition
Jun 06, 2025Natural Language Inference (NLI) is the task of determining whether a sentence pair represents entailment, contradiction, or a neutral relationship. While NLI models perform well on many inference tasks, their ability to handle fine-grained pragmatic inferences, particularly presupposition in conditionals, remains underexplored. In this study, we introduce CONFER, a novel dataset designed to evaluate how NLI models process inference in conditional sentences. We assess the performance of four NLI models, including two pre-trained models, to examine their generalization to conditional reasoning. Additionally, we evaluate Large Language Models (LLMs), including GPT-4o, LLaMA, Gemma, and DeepSeek-R1, in zero-shot and few-shot prompting settings to analyze their ability to infer presuppositions with and without prior context. Our findings indicate that NLI models struggle with presuppositional reasoning in conditionals, and fine-tuning on existing NLI datasets does not necessarily improve their performance.
uOttawa at LegalLens-2024: Transformer-based Classification Experiments
Oct 28, 2024



This paper presents the methods used for LegalLens-2024 shared task, which focused on detecting legal violations within unstructured textual data and associating these violations with potentially affected individuals. The shared task included two subtasks: A) Legal Named Entity Recognition (L-NER) and B) Legal Natural Language Inference (L-NLI). For subtask A, we utilized the spaCy library, while for subtask B, we employed a combined model incorporating RoBERTa and CNN. Our results were 86.3% in the L-NER subtask and 88.25% in the L-NLI subtask. Overall, our paper demonstrates the effectiveness of transformer models in addressing complex tasks in the legal domain. The source code for our implementation is publicly available at https://github.com/NimaMeghdadi/uOttawa-at-LegalLens-2024-Transformer-based-Classification
HateSieve: A Contrastive Learning Framework for Detecting and Segmenting Hateful Content in Multimodal Memes
Aug 11, 2024Amidst the rise of Large Multimodal Models (LMMs) and their widespread application in generating and interpreting complex content, the risk of propagating biased and harmful memes remains significant. Current safety measures often fail to detect subtly integrated hateful content within ``Confounder Memes''. To address this, we introduce \textsc{HateSieve}, a new framework designed to enhance the detection and segmentation of hateful elements in memes. \textsc{HateSieve} features a novel Contrastive Meme Generator that creates semantically paired memes, a customized triplet dataset for contrastive learning, and an Image-Text Alignment module that produces context-aware embeddings for accurate meme segmentation. Empirical experiments on the Hateful Meme Dataset show that \textsc{HateSieve} not only surpasses existing LMMs in performance with fewer trainable parameters but also offers a robust mechanism for precisely identifying and isolating hateful content. \textcolor{red}{Caution: Contains academic discussions of hate speech; viewer discretion advised.}
Co-Regularized Adversarial Learning for Multi-Domain Text Classification
Jan 30, 2022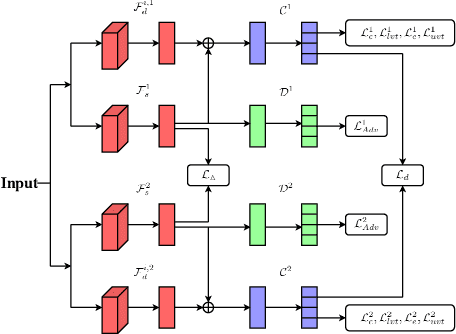

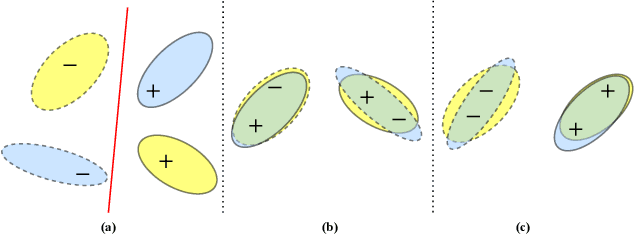
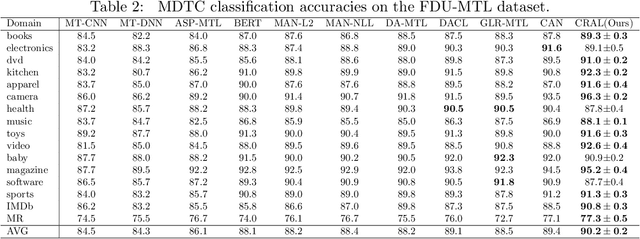
Multi-domain text classification (MDTC) aims to leverage all available resources from multiple domains to learn a predictive model that can generalize well on these domains. Recently, many MDTC methods adopt adversarial learning, shared-private paradigm, and entropy minimization to yield state-of-the-art results. However, these approaches face three issues: (1) Minimizing domain divergence can not fully guarantee the success of domain alignment; (2) Aligning marginal feature distributions can not fully guarantee the discriminability of the learned features; (3) Standard entropy minimization may make the predictions on unlabeled data over-confident, deteriorating the discriminability of the learned features. In order to address the above issues, we propose a co-regularized adversarial learning (CRAL) mechanism for MDTC. This approach constructs two diverse shared latent spaces, performs domain alignment in each of them, and punishes the disagreements of these two alignments with respect to the predictions on unlabeled data. Moreover, virtual adversarial training (VAT) with entropy minimization is incorporated to impose consistency regularization to the CRAL method. Experiments show that our model outperforms state-of-the-art methods on two MDTC benchmarks.
Maximum Batch Frobenius Norm for Multi-Domain Text Classification
Jan 29, 2022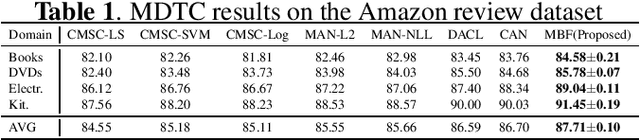
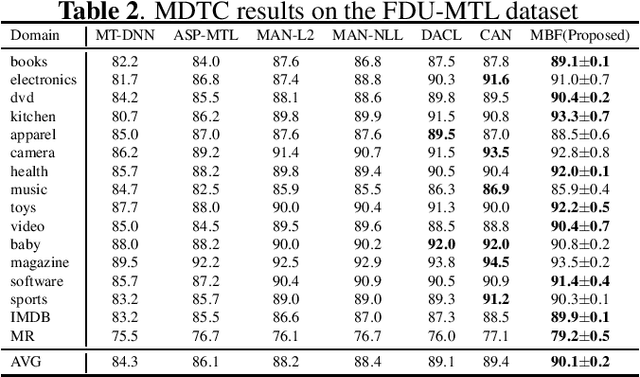
Multi-domain text classification (MDTC) has obtained remarkable achievements due to the advent of deep learning. Recently, many endeavors are devoted to applying adversarial learning to extract domain-invariant features to yield state-of-the-art results. However, these methods still face one challenge: transforming original features to be domain-invariant distorts the distributions of the original features, degrading the discriminability of the learned features. To address this issue, we first investigate the structure of the batch classification output matrix and theoretically justify that the discriminability of the learned features has a positive correlation with the Frobenius norm of the batch output matrix. Based on this finding, we propose a maximum batch Frobenius norm (MBF) method to boost the feature discriminability for MDTC. Experiments on two MDTC benchmarks show that our MBF approach can effectively advance the performance of the state-of-the-art.
Towards Category and Domain Alignment: Category-Invariant Feature Enhancement for Adversarial Domain Adaptation
Aug 14, 2021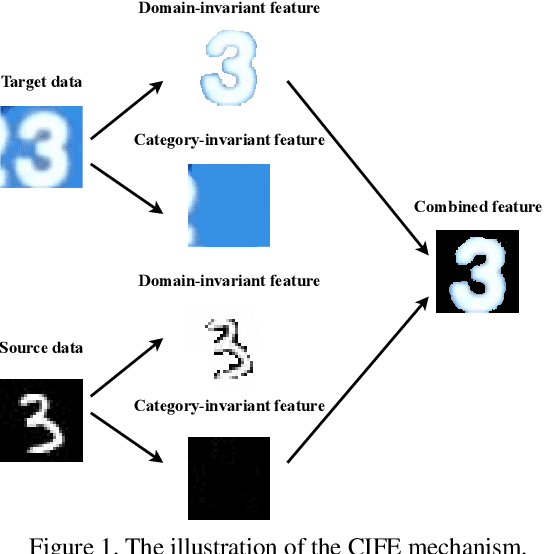
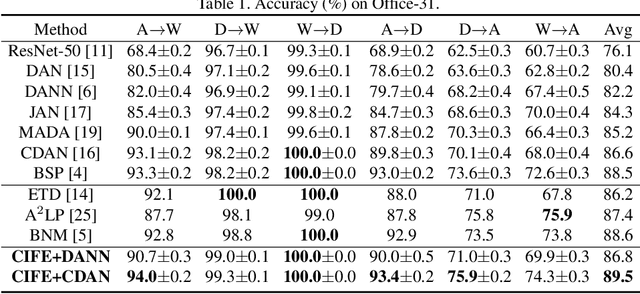
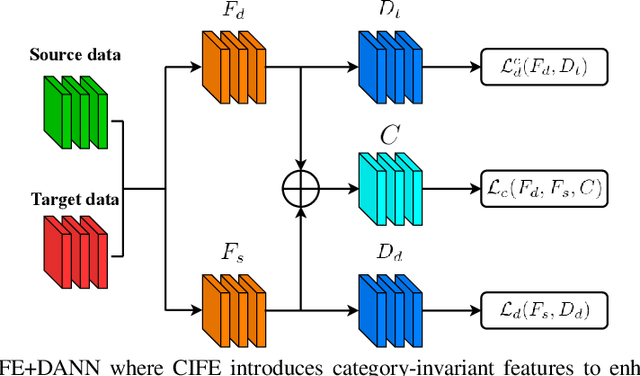
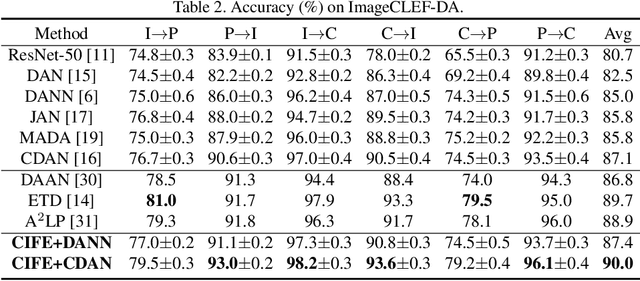
Adversarial domain adaptation has made impressive advances in transferring knowledge from the source domain to the target domain by aligning feature distributions of both domains. These methods focus on minimizing domain divergence and regard the adaptability, which is measured as the expected error of the ideal joint hypothesis on these two domains, as a small constant. However, these approaches still face two issues: (1) Adversarial domain alignment distorts the original feature distributions, deteriorating the adaptability; (2) Transforming feature representations to be domain-invariant needs to sacrifice domain-specific variations, resulting in weaker discriminability. In order to alleviate these issues, we propose category-invariant feature enhancement (CIFE), a general mechanism that enhances the adversarial domain adaptation through optimizing the adaptability. Specifically, the CIFE approach introduces category-invariant features to boost the discriminability of domain-invariant features with preserving the transferability. Experiments show that the CIFE could improve upon representative adversarial domain adaptation methods to yield state-of-the-art results on five benchmarks.
Context-Sensitive Visualization of Deep Learning Natural Language Processing Models
May 25, 2021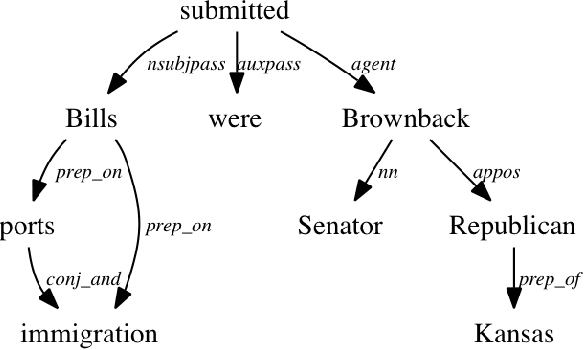
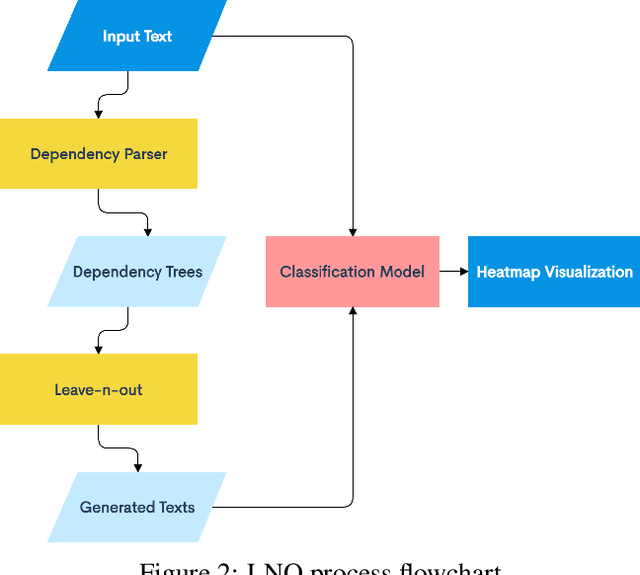
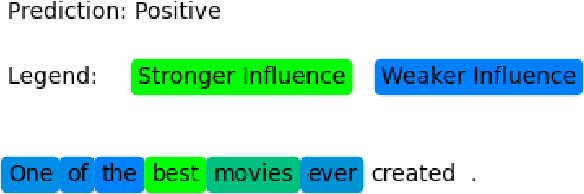

The introduction of Transformer neural networks has changed the landscape of Natural Language Processing (NLP) during the last years. So far, none of the visualization systems has yet managed to examine all the facets of the Transformers. This gave us the motivation of the current work. We propose a new NLP Transformer context-sensitive visualization method that leverages existing NLP tools to find the most significant groups of tokens (words) that have the greatest effect on the output, thus preserving some context from the original text. First, we use a sentence-level dependency parser to highlight promising word groups. The dependency parser creates a tree of relationships between the words in the sentence. Next, we systematically remove adjacent and non-adjacent tuples of \emph{n} tokens from the input text, producing several new texts with those tokens missing. The resulting texts are then passed to a pre-trained BERT model. The classification output is compared with that of the full text, and the difference in the activation strength is recorded. The modified texts that produce the largest difference in the target classification output neuron are selected, and the combination of removed words are then considered to be the most influential on the model's output. Finally, the most influential word combinations are visualized in a heatmap.
Conditional Adversarial Networks for Multi-Domain Text Classification
Feb 19, 2021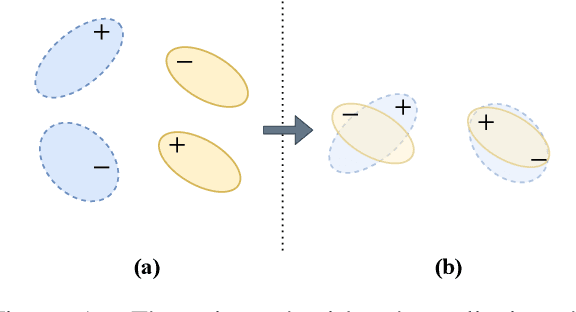

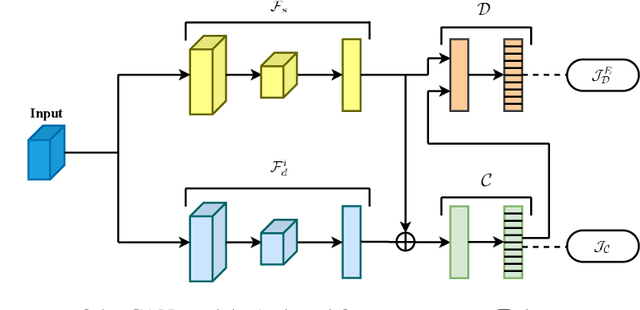
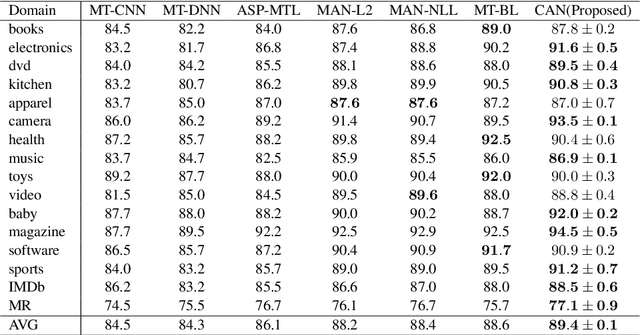
In this paper, we propose conditional adversarial networks (CANs), a framework that explores the relationship between the shared features and the label predictions to impose more discriminability to the shared features, for multi-domain text classification (MDTC). The proposed CAN introduces a conditional domain discriminator to model the domain variance in both shared feature representations and class-aware information simultaneously and adopts entropy conditioning to guarantee the transferability of the shared features. We provide theoretical analysis for the CAN framework, showing that CAN's objective is equivalent to minimizing the total divergence among multiple joint distributions of shared features and label predictions. Therefore, CAN is a theoretically sound adversarial network that discriminates over multiple distributions. Evaluation results on two MDTC benchmarks show that CAN outperforms prior methods. Further experiments demonstrate that CAN has a good ability to generalize learned knowledge to unseen domains.